RabbitMQ防止消息丢失
转载请注明出处
0.目录
RabbitMQ-从基础到实战(1)— Hello RabbitMQ
1.简介
RabbitMQ中,消息丢失可以简单的分为两种:客户端丢失和服务端丢失。针对这两种消息丢失,RabbitMQ都给出了相应的解决方案。
2.防止客户端丢失消息
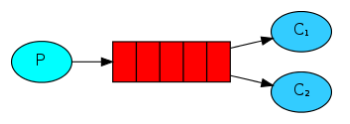
如图,生产者P向队列中生产消息,C1和C2消费队列中的消息,默认情况下,RabbitMQ会平均的分发消费给C1C2(Round-robin dispatching),假设一个任务的执行时间非常长,在执行过程中,客户端挂了(连接断开),那么,该客户端正在处理且未完成的消息,以及分配给它还没来得及执行的消息,都将丢失。因为默认情况下,RabbitMQ分发完消息后,就会从内存中把消息删除掉。
3.消息确认(Message acknowledgment)
为了解决上述问题,RabbitMQ引入了消息确认机制,当消息处理完成后,给Server端发送一个确认消息,来告诉服务端可以删除该消息了,如果连接断开的时候,Server端没有收到消费者发出的确认信息,则会把消息转发给其他保持在线的消费者。
验证上述问题
首先,我们验证上述问题(客户端丢失消息)是否真的存在,对Consumer进行如下改造。
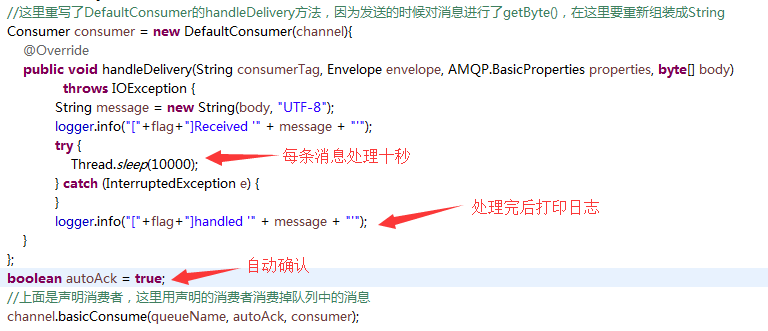
先生产两条消息
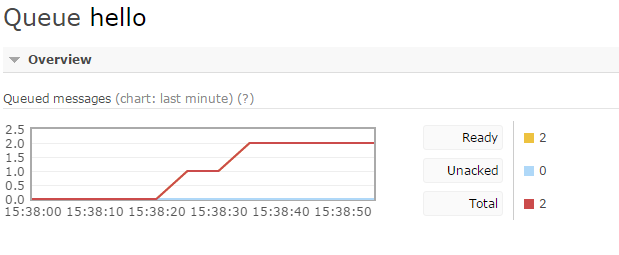
启动消费者,在消费者接收到消息,还没处理完成的时候,强制关掉

这时,观察控制台,发现两条消息都没有了,1条是在执行中丢失的,还有1条,已经分配给这个Consumer,还没来得及处理,也丢失了
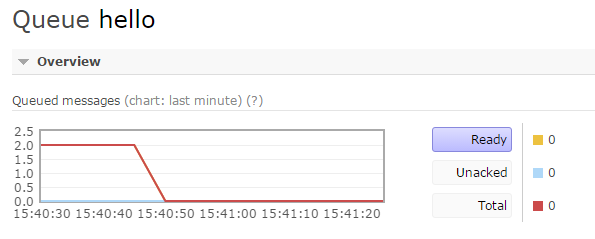
这证明了上述问题是真的存在的,如果发生在生产环境,将产生难以预料的后果
引入消息确认机制
为了方便观察,我们用CMD来运行Consumer,要通过maven打成可执行的JAR包,需要在pom.xml中增加如下配置

<build>
<finalName>Consumer</finalName>
<plugins>
<plugin>
<artifactId>maven-assembly-plugin</artifactId>
<configuration>
<appendAssemblyId>false</appendAssemblyId>
<descriptorRefs>
<descriptorRef>jar-with-dependencies</descriptorRef>
</descriptorRefs>
<archive>
<manifest>
<mainClass>com.liyang.ticktock.rabbitmq.App</mainClass>
</manifest>
</archive>
</configuration>
<executions>
<execution>
<id>make-assembly</id>
<phase>package</phase>
<goals>
<goal>assembly</goal>
</goals>
</execution>
</executions>
</plugin>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-compiler-plugin</artifactId>
<configuration>
<source>1.8</source>
<target>1.8</target>
</configuration>
</plugin> </plugins>
</build>
上述配置描述了最终打包名字、入口类路径、带上依赖包、使用1.8版本的JDK进行打包,配置完后,就可以通过maven的install方法,在target目录生成可执行的jar包,如果包大小很小,应检查配置,是不是没有带上依赖包

再次改造Consummer类
install成可执行jar包,通过cmd开启两个consumer
通过Sender发送一条消息,然后用Ctrl+C结束先收到消息的Consumer,发现另外一个Consumer接收到了未处理完的消息
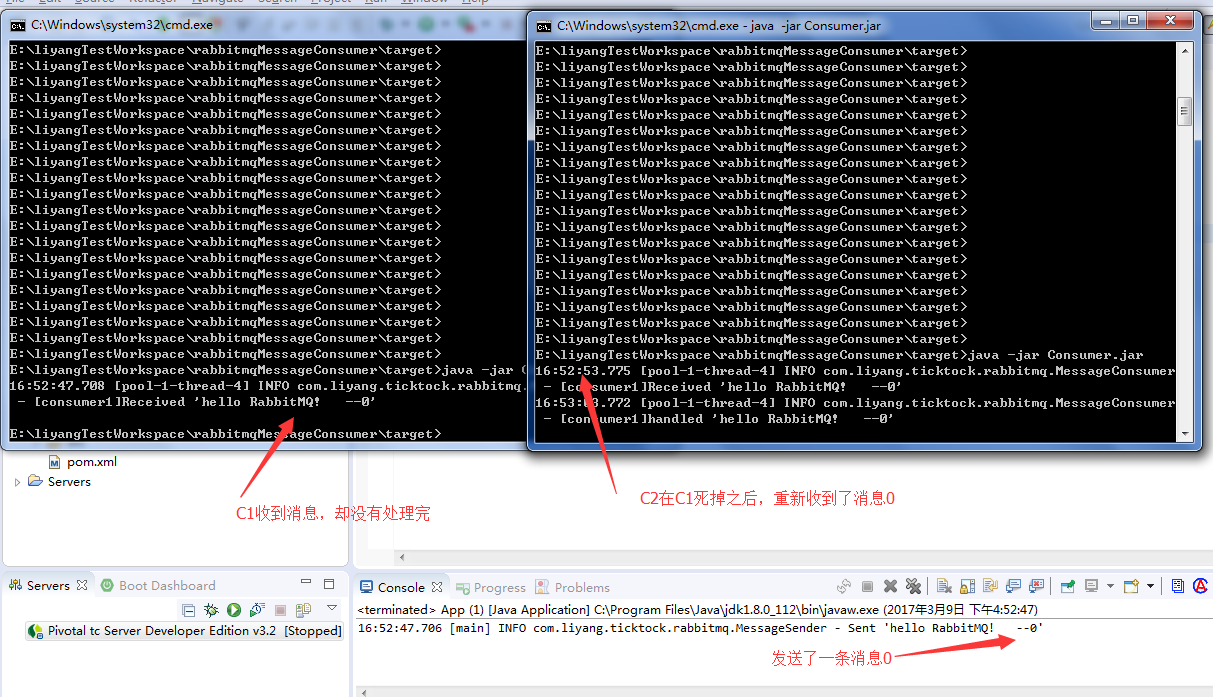
问题得到了解决,现在消费者在执行过程中死掉也不会丢失消息了
看一下发送确认的方法
1 /**
2 * Acknowledge one or several received
3 * messages. Supply the deliveryTag from the {@link com.rabbitmq.client.AMQP.Basic.GetOk}
4 * or {@link com.rabbitmq.client.AMQP.Basic.Deliver} method
5 * containing the received message being acknowledged.
6 * @see com.rabbitmq.client.AMQP.Basic.Ack
7 * @param deliveryTag the tag from the received 这个是RabbitMQ用来区分消息的,文档在这 8 * @param multiple true to acknowledge all messages up to and 为true的话,确认所有消息,为false只确认当前消息
9 * including the supplied delivery tag; false to acknowledge just
10 * the supplied delivery tag.
11 * @throws java.io.IOException if an error is encountered
12 */
13 void basicAck(long deliveryTag, boolean multiple) throws IOException;
在官方文档中,这样描述deliveryTag

简单来说,就是RabbitMQ内部用来区分消息的一个标签,从envelope中获取就行了
忘记确认将引起内存泄漏
RabbitMQ只有在收到消费者确认后,才会从内存中删除消息,如果消费者忘了确认(更多情况是因为代码问题没有执行到确认的代码),将会导致内存泄漏
验证一下
注释掉Consumer中的确认代码

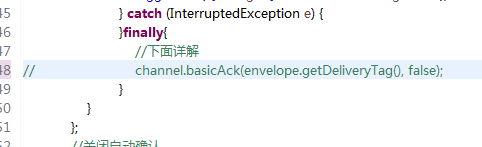
运行Sender和Consumer,不停的生产消费消息,发现消费者在正常的消费消息
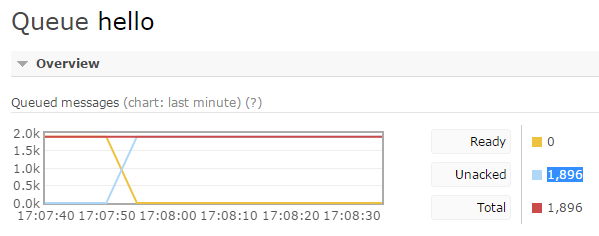
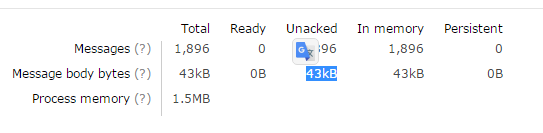
查看控制台,发现已经被吃掉了43KB的内存,所以,在试用过程中,一定要保证消息确认在任何情况下都可以发出,否则即使消费者处理完成,RabbitMQ也不会把消息在内存中清除,在该消费者断开连接之后,还会把消息转发给其他消费者重新处理,将引发难以预计的问题
4.消息的持久化
现在,消费者宕机已经无法影响到我们的消息了,但如果RabbitMQ重启了,消息依然会丢失。所幸的是,RabbitMQ提供了持久化的机制,将内存中的消息持久化到硬盘上,即使重启RabbitMQ,消息也不会丢失。但是,仍然有一个非常短暂的时间窗口(RabbitMQ收到消息还没来得及存到硬盘上)会导致消息丢失,如果需要严格的控制,可以参考官方文档
要使用RabbitMQ的消息持久化,在声明队列时设置一个参数即可

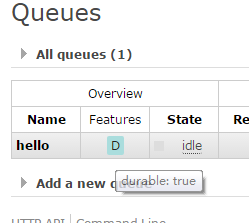
注意,RabbitMQ不允许对一个已经存在的队列用不同的参数重新声明,对于试图这么做的程序,会报错,所以,改动之前代码之前,要在控制台中把原来的队列删除
重新声明队列后,发现Durable为true
重启RabbitMQ
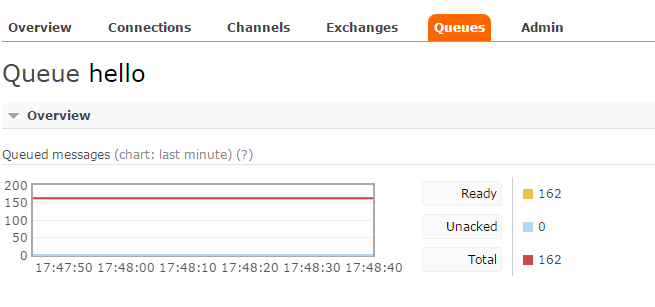
队列的消息没有丢失
5.结束语
这一章介绍了RabbitMQ消息的确认和持久化,后面将会继续深入介绍RabbitMQ的其他特性
http://www.cnblogs.com/4----/p/6526033.html
RabbitMQ防止消息丢失的更多相关文章
- RabbitMQ:消息丢失 | 消息重复 | 消息积压的原因+解决方案+网上学不到的使用心得
前言 首先说一点,企业中最常用的实际上既不是RocketMQ,也不是Kafka,而是RabbitMQ. RocketMQ很强大,但主要是阿里推广自己的云产品而开源出来的一款消息队列,其实中小企业用Ro ...
- 解决RabbitMQ消息丢失问题和保证消息可靠性(一)
原文链接(作者一个人):https://juejin.im/post/5d468591f265da03b810427e 工作中经常用到消息中间件来解决系统间的解耦问题或者高并发消峰问题,但是消息的可靠 ...
- RabbitMQ延迟消息:死信队列 | 延迟插件 | 二合一用法+踩坑手记+最佳使用心得
前言 前段时间写过一篇: # RabbitMQ:消息丢失 | 消息重复 | 消息积压的原因+解决方案+网上学不到的使用心得 很多人加了我好友,说很喜欢这篇文章,也问了我一些问题. 因为最近工作比较忙, ...
- rabbitmq 重复ACK导致消息丢失
rabbitmq 重复确认导致消息丢失 背景 rabbitmq 在应用场景中,大多采用工作队列 work-queue的模式. 在一个常见的工作队列模式中,消费者 worker 将不断的轮询从队列中拉取 ...
- RabbitMQ,为应对消息从发送到消费,各个环节消息丢失的解决方案
1.发送方 为保证消息到达exchange,在这个过程中不丢失. 用事务或者发送方确认机制 见<RabbitMQ实战指南>4.8节 2.为保证消息不会因为到达exchange后 ...
- 如何保证RabbitMQ的消息不丢失及其背后的原理
一.消息为什么丢失 RabbitMQ默认情况下的交换机和队列以及消息是非持久化的,也就是说在服务器重启或者宕机恢复后,之前创建的交换机和队列都将不复存在,之前未消费的消息也就消失不见了.原因在于每个队 ...
- RabbitMQ消息丢失问题和保证消息可靠性-消费端不丢消息和HA(二)
继续上篇文章解决RabbitMQ消息丢失问题和保证消息可靠性(一) 未完成部分,我们聊聊MQ Server端的高可用和消费端如何保证消息不丢的问题? 回归上篇的内容,我们知道消息从生产端到服务端,为了 ...
- RabbitMq如何确保消息不丢失
上篇写了掌握Rabbitmq几个重要概念,从一条消息说起,这篇来总结关于消息丢失让人头痛的事情.网络故障.服务器重启.硬盘损坏等都会导致消息的丢失.消息从生产到消费主要结果以下几个阶段如下图. ①生产 ...
- 如何处理RabbitMQ 消息堆积和消息丢失问题
消息堆积 解决方案: 增加消费者或后台相关组件的吞吐能力 增加消费的多线程处理 根据不同的业务实现不同的丢弃任务,选择不同的策略淘汰任务 默认情况下,RabbitMQ消费者为单线程串行消费,设置并行消 ...
随机推荐
- Python PEP-8编码风格指南中文版
#PEP 8 – Python编码风格指南 PEP: 8 Title: Style Guide for Python Code Author: Guido van Rossum , Barry War ...
- AndroidNDK开发中使用CMake编译JNI
虽然一直在做NDK的开发工作,但是由于项目比较久远,都是使用Makefile进行底层编译,对于目前AndroidStudio官方提供的CMake编译方式并不是很了解,现在学习下这种已经不算新潮的新方式 ...
- Debian9安装vim和vim无法右键鼠标粘贴解决方法
问题描述: Debian9有时候安装的时候没有vim,在centos用习惯了vim 1.Debian安装vim: root@kvm1:/etc/network# apt-get install vim ...
- echo '1'.print(2)+3; 的输出结果为什么是511
今天看到一道有趣的题目,如上所示.结果为什么会是511呢? 这个结果的计算分为三步来理解: 首先计算的是 右边print(2)+3,这个你可以直接理解成print(2+3),得到的结果是5.而prin ...
- python——函数之生成器
1 生成器函数的含义 生成器是一个返回可以迭代对象的函数,它是一个特殊的迭代器,但迭代器的抽象层级更高且比较复杂需要实现很多方法.相较迭代器而言,生成器简单使用. 2 生成器的创建方式 2.1 ...
- 【工具大道】UML的点点滴滴
本文地址 点击关注微信公众号 wenyuqinghuai 分享提纲: 1. 概述 2. UML类图 3. UML时序图 4. 参考资料 1.概述 1.1)百度百科: 又称统 ...
- 【Linux基础】VI命令模式下大小写转换
[开始位置] ---- 可以指定开始的位置,默认是光标的当前位置 gu ---- 把选择范围全部小写 gU ---- 把选择范围全部大写 [结束位置] ---- 可以跟着类似的w,6G,gg等定位到错 ...
- MVC四大筛选器—ExceptionFilter
该筛选器是在系统出现异常时触发,可以对抛出的异常进行处理.所有的ExceptionFilter筛选器都是实现自IExceptionFilter接口 public interface IExceptio ...
- C. Lorenzo Von Matterhorn LCA
C. Lorenzo Von Matterhorn time limit per test 1 second memory limit per test 256 megabytes input sta ...
- CF817F MEX Queries
嘟嘟嘟 这题一直在我的某谷任务计划里,不知为啥一直没做. 现在看起来很水啊,就是离散化+线段树.可能是当时没想明白怎么离散化吧. 就是先把算有区间端点都离线下来,然后把\(l - 1, l, l + ...