HBase读写数据的详细流程及ROOT表/META表介绍
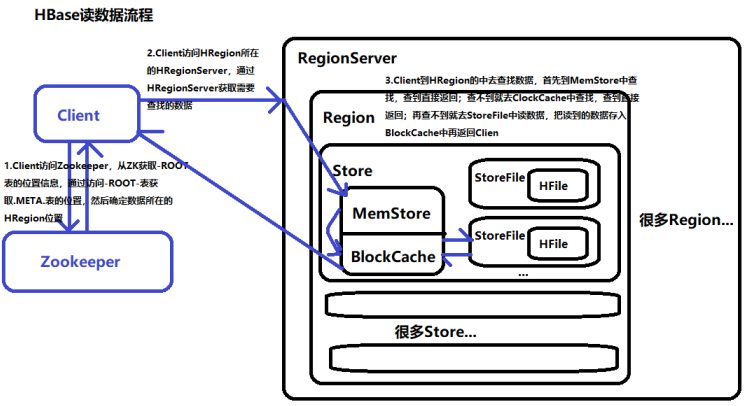
一、HBase读数据流程
1.Client访问Zookeeper,从ZK获取-ROOT-表的位置信息,通过访问-ROOT-表获取.META.表的位置,然后确定数据所在的HRegion位置;
2.Client访问HRegion所在的HRegionServer,通过HRegionServer获取需要查找的数据;
3.Client到HRegion的中去查找数据,首先到MemStore中查找,查到直接返回;查不到就去ClockCache中查找,查到直接返回;再查不到就去StoreFile中读数据,把读到的数据存入BlockCache中再返回Client。
如图:
二、HBase写数据流程
1.Client通过Zookeeper调度获取表的元数据信息;
2.Cilent通过rpc协议与RegionServer交互,通过-ROOT-表与.META.表找到对应的对应的Region;
3.将数据写入HLog日志中,如出现意外可以同通过HLog恢复信息;
4.将数据写入Region的MemStore中,当MemStore达到阈值开始溢写,将其中的数据Flush成一个StoreFile;
5.MemStore不断生成新的StoreFile,当StoreFile的数量到达阈值后会出发Compact合并操作,将多个StoreFile合并成一个StoreFile;
6.StoreFile文件会不断增大,当达到阈值后会出发Split操作,把当前的Region且分为两个新的Region。父Region会下线,两个子Region会被HMaster分配到相应的RegionServer。
图略、自己脑补一哈把~~
*********************************************************************************************
补充:1.由读写数据的流程可以发现,Region中的内存分为两块:MemStore(负责写数据)、BlockCache(负责读数据),这是HBase的一大特点——读写分离,这也是HBase读写速度极快的原因之一;
2.在HBase中,可以看出只有增添操作,所有的更新和删除都是在后续的Compact合并历程中进行的,这使得用户的写操作只有进入内存就可以立刻返回,实现了I/O的高性能。
*********************************************************************************************
三、-ROOT-表和.META.表的介绍
HBase用-ROOT-表记录.META.表的位置信息(即元数据信息),而.META.表记录了用户表Region的位置信息。
为了定位.META.表中各个Region的位置信息,把.META.表中所有Region的元数据保存在-ROOT-表中,最后由Zookeeper记录-Root-表的位置信息。
所以客户端Client要先访问ZK获取-ROOT-表的位置,然后访问-ROOT-表获取.META.表的位置,最后根据.META.表中的信息确定用户数据存放的位置。
HBase读写数据的详细流程及ROOT表/META表介绍的更多相关文章
- MapReduce从HBase读写数据简单示例
就用单词计数这个例子,需要统计的单词存在HBase中的word表,MapReduce执行的时候从word表读取数据,统计结束后将结果写入到HBase的stat表中. 1.在eclipse中建立一个ha ...
- 一条数据的HBase之旅,简明HBase入门教程-Write全流程
如果将上篇内容理解为一个冗长的"铺垫",那么,从本文开始,剧情才开始正式展开.本文基于提供的样例数据,介绍了写数据的接口,RowKey定义,数据在客户端的组装,数据路由,打包分发, ...
- 大数据学习路线分享-Hbase shell的基本操作完整流程
HBase的命令行工具,最简单的接口,适合HBase管理使用,可以使用shell命令来查询HBase中数据的详细情况.安装完HBase之后,启动hadoop集群(利用hdfs存储),启动zookeep ...
- HBase丢失数据的故障和原因分析
hbase的稳定性是近期社区的重要关注点,毕竟稳定的系统才能被推广开来,这里有几次稳定性故障和大家分享. 第一次生产故障的现象及原因 现象: 1 hbase发现无法写入 2 通过hbc ...
- HBase读写的几种方式(二)spark篇
1. HBase读写的方式概况 主要分为: 纯Java API读写HBase的方式: Spark读写HBase的方式: Flink读写HBase的方式: HBase通过Phoenix读写的方式: 第一 ...
- 【转帖】HBase读写的几种方式(二)spark篇
HBase读写的几种方式(二)spark篇 https://www.cnblogs.com/swordfall/p/10517177.html 分类: HBase undefined 1. HBase ...
- <HBase><读写><LSM>
Overview HBase中的一个big table,首先会按行划分成一些region(这些region之间是有序的,由startkey保证),每个region分配到不同的节点进行存储.因此,reg ...
- Hbase写数据,存数据,读数据的详细过程
Client写入 -> 存入MemStore,一直到MemStore满 -> Flush成一个StoreFile,直至增长到一定阈值 -> 出发Compact合并操作 -> 多 ...
- 大数据查询——HBase读写设计与实践
导语:本文介绍的项目主要解决 check 和 opinion2 张历史数据表(历史数据是指当业务发生过程中的完整中间流程和结果数据)的在线查询.原实现基于 Oracle 提供存储查询服务,随着数据量的 ...
随机推荐
- vue打包项目后使用-webkit-line-clamp: 2;这个属性不生效?
在项目中要实现多行省略,-webkit-line-clamp: 2;打包后不生效,使用下面的方法: word-break: break-all; text-overflow: ellipsis; di ...
- swift 学习- 13 -- 下标
// 下标 可以定义在 类, 结构体, 和 枚举 中, 是访问集合, 列表或 序列中元素的快捷方式, 可以使用下标的索引, 设置 和 获取值, 而不需要再调用对应的存取方法, 举例来说, 用下标访问一 ...
- PID控制器开发笔记之九:基于前馈补偿的PID控制器的实现
对于一般的时滞系统来说,设定值的变动会产生较大的滞后才能反映在被控变量上,从而产生合理的调节.而前馈控制系统是根据扰动或给定值的变化按补偿原理来工作的控制系统,其特点是当扰动产生后,被控变量还未变化以 ...
- Ftp上传的方法
using System;using System.Collections.Generic;using System.IO;using System.Net;using System.Text; na ...
- sticky footer 模板
http://www.w3cplus.com/blog/tags/136.html http://www.w3cplus.com/css/css-sticky-foot-at-bottom-of-th ...
- RefineDet训练自己的数据
https://github.com/sfzhang15/RefineDet 1.编译安装 cp Makefile.config.example Makefile.config make all -j ...
- 10进制 VS 2进制
10进制 VS 2进制 时间限制: 1 Sec 内存限制: 32 MB 题目描述 样例输出 623 #include<stdio.h> #include<string.h> ...
- IP的计算
IP的计算 时间限制: 1 Sec 内存限制: 32 MB 位无符号整数来表示,一般用点分方式来显示,点将IP地址分成4个部分,每个部分为8位,表示成一个无符号整数(因此不需要用正号出现),如192 ...
- 官方版sublime Text3汉化和激活注册码
转载:https://www.cnblogs.com/chaonuanxi/p/9371837.html sublimeText3 很不错,前面几天下了vscore学习Node.js,感觉有点懵,今天 ...
- Ubuntu 更改屏幕分辨率
安装完Ubuntu后发现分辨率不合适,平时习惯了看小一点的文字,所以搜了一下修改屏幕分辨率的命令,具体操作如下: 1.先用 xrandr 命令查看一下当前系统支持的分辨率 wayde@wayde-Al ...