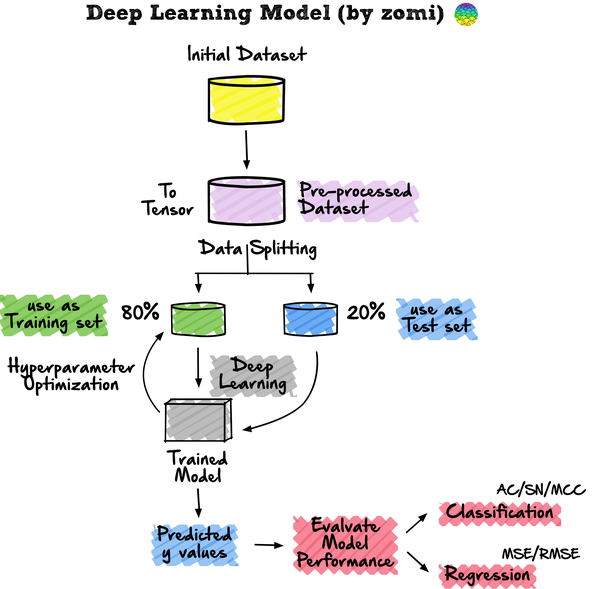
AI系统——机器学习和深度学习算法流程
- 终于考上人工智能的研究僧啦,不知道机器学习和深度学习有啥区别,感觉一切都是深度学习
- 挖槽,听说学长已经调了10个月的参数准备发有2000亿参数的T9开天霹雳模型,我要调参发T10准备拿个Best Paper

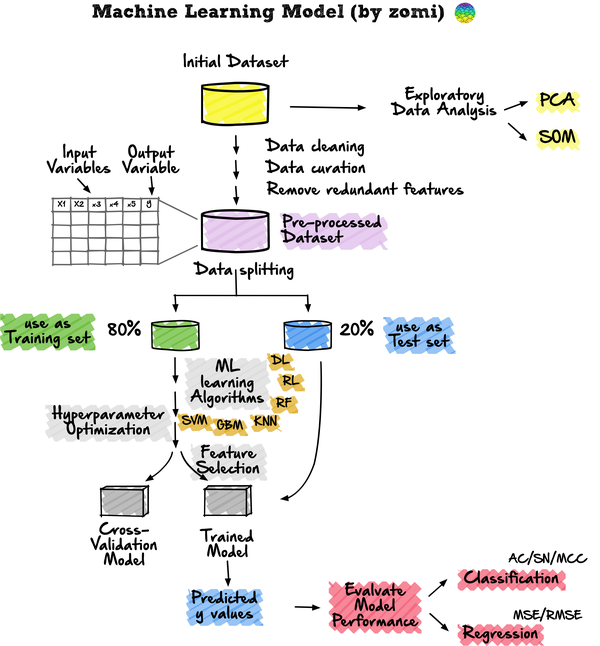
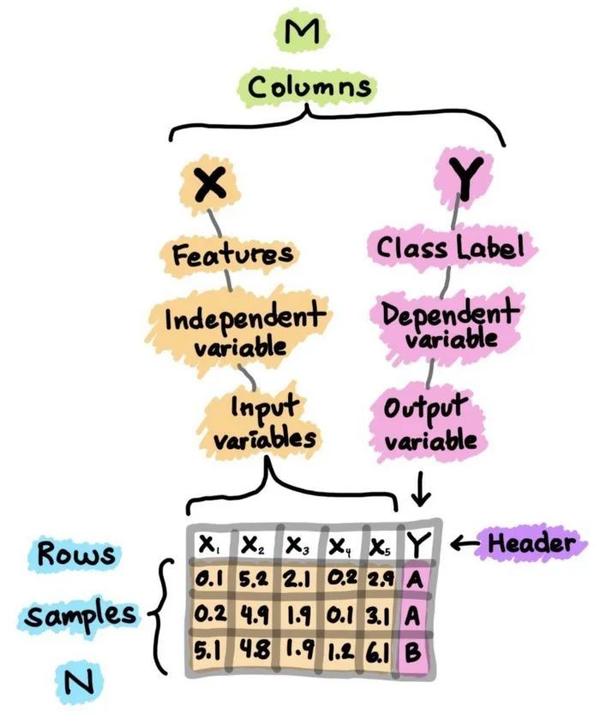
探索性数据分析方法简单来说就是去了解数据,分析数据,搞清楚数据的分布。主要注重数据的真实分布,强调数据的可视化,使分析者能一目了然看出数据中隐含的规律,从而得到启发,以此帮助分析者找到适合数据的模型。
- 描述性统计:平均数、中位数、模式、标准差。
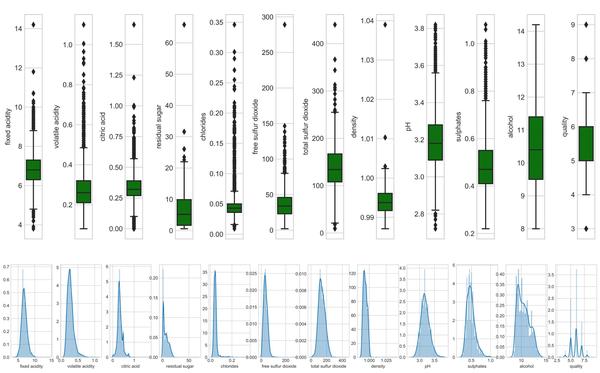
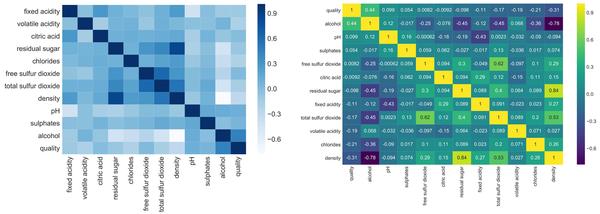
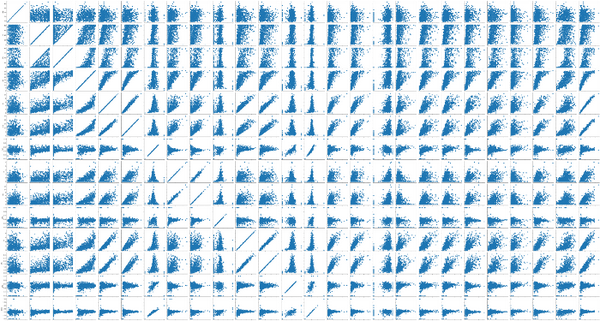
- 数据可视化:热力图(辨别特征内部相关性)、箱形图(可视化群体差异)、散点图(可视化特征之间的相关性)、主成分分析(可视化数据集中呈现的聚类分布)等。
- 数据整形:对数据进行透视、分组、过滤等。
例如对图像进行resize成统一的大小或者分辨率。
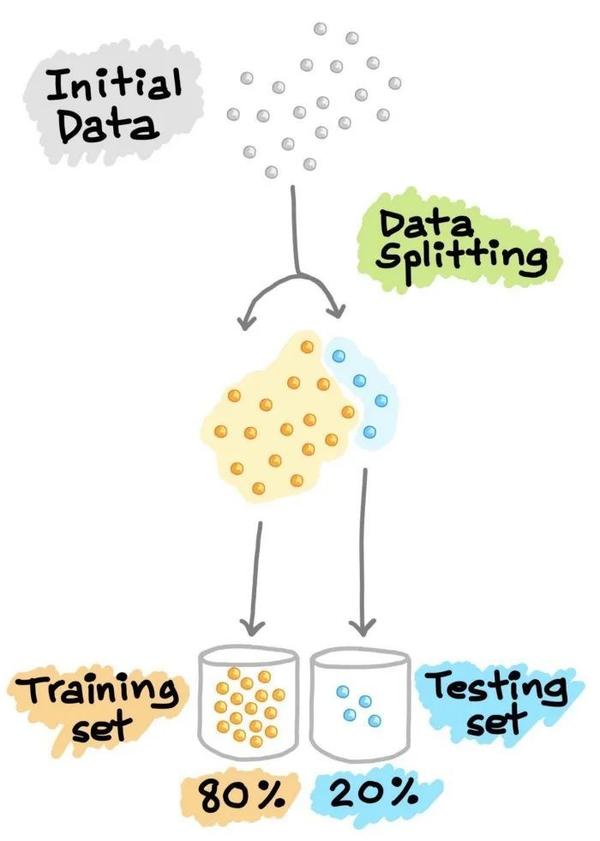
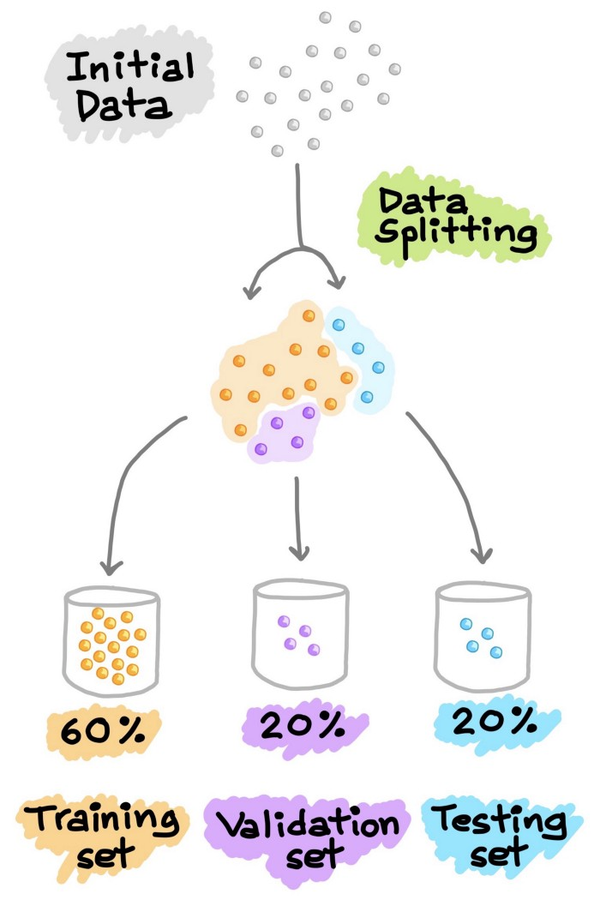
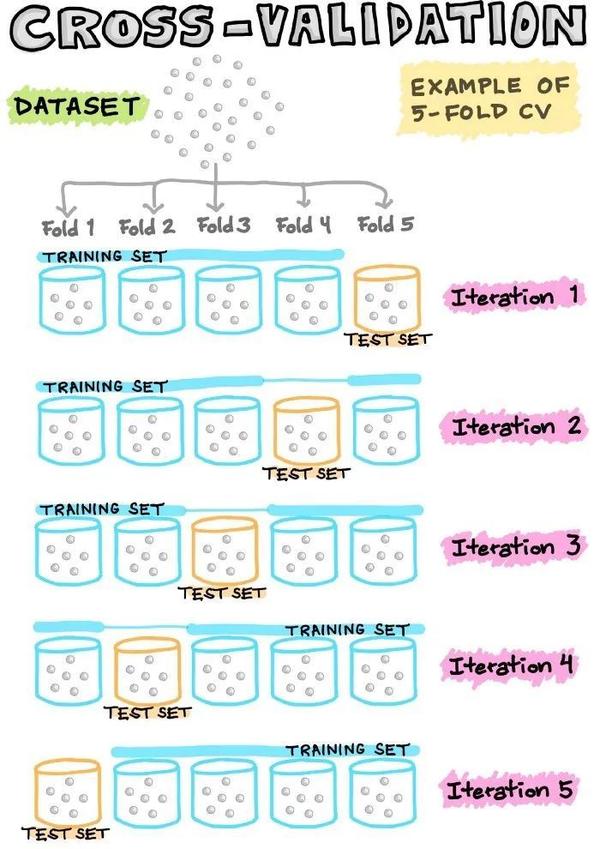
这种交叉验证的方法在机器学习流程中被广泛的使用,但是深度学习中使用得比较少哈。
- 监督学习:是一种机器学习任务,建立输入X和输出Y变量之间的数学(映射)关系。这样的(X、Y)对构成了用于建立模型的标签数据,以便学习如何从输入中预测输出。
- 无监督学习:是一种只利用输入X变量的机器学习任务。X变量是未标记的数据,学习算法在建模时使用的是数据的固有结构。
- 强化学习:是一种决定下一步行动方案的机器学习任务,它通过试错学习(trial and error learning)来实现这一目标,努力使reward回报最大化。
以随机森林为例。在使用randomForest时,通常会对两个常见的超参数进行优化,其中包括mtry和ntree参数。mtry(maxfeatures)代表在每次分裂时作为候选变量随机采样的变量数量,而ntree(nestimators)代表要生长的树的数量。
- [1] https://github.com/dataprofessor/infographic
- [2] 陈仲铭. 《深度学习:原理与实践》.[M]
AI系统——机器学习和深度学习算法流程的更多相关文章
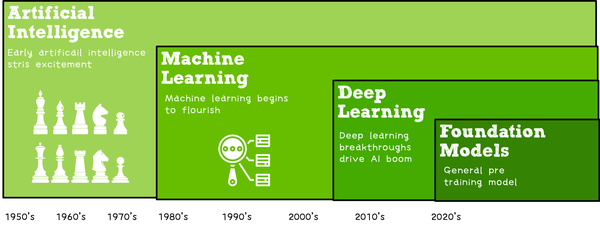
- 一张图看懂AI、机器学习和深度学习的区别
AI(人工智能)是未来,是科幻小说,是我们日常生活的一部分.所有论断都是正确的,只是要看你所谈到的AI到底是什么. 例如,当谷歌DeepMind开发的AlphaGo程序打败韩国职业围棋高手Lee Se ...
- AI、机器学习、深度学习、神经网络
1.AI:人工智能(Artificial Intelligence) 2.机器学习:(Machine Learning, ML) 3.深度学习:Deep Learning 人工功能的实现是让机器自己学 ...
- 认识:人工智能AI 机器学习 ML 深度学习DL
人工智能 人工智能(Artificial Intelligence),英文缩写为AI.它是研究.开发用于模拟.延伸和扩展人的智能的理论.方法.技术及应用系统的一门新的技术科学. 人工智能是对人的意识. ...
- 机器学习、深度学习以及人工智能正在快速演进(ML、DL、AI)
机器学习.深度学习以及人工智能正在快速演进 机器学习.深度学习和人工智能(ML.DL和AI)是彼此相关的概念,他们正在改变不知多少行业,改变其自身管理模式,同时改变做出决策的方式.显然,ML.DL和A ...
- [AI开发]一个例子说明机器学习和深度学习的关系
深度学习现在这么火热,大部分人都会有‘那么它与机器学习有什么关系?’这样的疑问,网上比较它们的文章也比较多,如果有机器学习相关经验,或者做过类似数据分析.挖掘之类的人看完那些文章可能很容易理解,无非就 ...
- 【AI in 美团】深度学习在OCR中的应用
AI(人工智能)技术已经广泛应用于美团的众多业务,从美团App到大众点评App,从外卖到打车出行,从旅游到婚庆亲子,美团数百名最优秀的算法工程师正致力于将AI技术应用于搜索.推荐.广告.风控.智能调度 ...
- 近200篇机器学习&深度学习资料分享
编者按:本文收集了百来篇关于机器学习和深度学习的资料,含各种文档,视频,源码等.并且原文也会不定期的更新.望看到文章的朋友能够学到很多其它. <Brief History of Machine ...
- AI安全初探——利用深度学习检测DNS隐蔽通道
AI安全初探——利用深度学习检测DNS隐蔽通道 目录 AI安全初探——利用深度学习检测DNS隐蔽通道 1.DNS 隐蔽通道简介 2. 算法前的准备工作——数据采集 3. 利用深度学习进行DNS隐蔽通道 ...
- 【AI in 美团】深度学习在文本领域的应用
背景 近几年以深度学习技术为核心的人工智能得到广泛的关注,无论是学术界还是工业界,它们都把深度学习作为研究应用的焦点.而深度学习技术突飞猛进的发展离不开海量数据的积累.计算能力的提升和算法模型的改进. ...
随机推荐
- MySQL查询数据库表空间大小
一.查询所有数据库占用空间大小 SELECT TABLE_SCHEMA, CONCAT( TRUNCATE(SUM(data_length) / 1024 / 1024, 2), ' MB' ) AS ...
- mysql的MVCC多版本并发控制机制
MVCC多版本并发控制机制 全英文名:Multi-Version Concurrency Control MVCC不会通过加锁互斥来保证隔离性,避免频繁的加锁互斥. 而在串行化隔离级别为了保证较高的隔 ...
- LuoguB2101 计算矩阵边缘元素之和 题解
Content 给定一个 \(m\times n\) 的矩阵,求矩阵边缘元素之和. 数据范围:\(1\leqslant m,n\leqslant 100\). Solution 对于新手来说,看到这题 ...
- CF173A Rock-Paper-Scissors 题解
Content 有 \(2\) 个人在玩石头剪刀布,已知他们的出手都有一定的规律,求 \(n\) 局之后两个人各输了几局. 数据范围:\(1\leqslant n\leqslant 2\times 1 ...
- 反射hasattr; getattr; setattr; delattr
hasattr(obj,name_str):#判断一个对象obj里面是否有对应的name_str字符串的方法,返回True或者Falsegetattr(obj,name_str):#根据字符串去获取对 ...
- qt5读取所有本机IP
说明 需要添加 network模块 本文介绍的函数将读取所有本机IP,包括 ipv4和ipv6 本文演示版本 qt5.14 头文件 #include <QHostAddress> #inc ...
- 【LeetCode】1042. Flower Planting With No Adjacent 解题报告(Python & C++)
作者: 负雪明烛 id: fuxuemingzhu 个人博客: http://fuxuemingzhu.cn/ 目录 题目描述 题目大意 解题方法 图 日期 题目地址:https://leetcode ...
- RXD and math
RXD and math 题目链接 思路 \(u\)函数是莫比乌斯函数,这个不影响做题,这个式子算的是\([1,n^k]\)中能够写成\(a*b^2\)的数的个数,\(u(a)!=0\).然后我们可以 ...
- 1235 - Coin Change (IV)
1235 - Coin Change (IV) PDF (English) Statistics Forum Time Limit: 1 second(s) Memory Limit: 32 M ...
- Windows 11实现直播,VLC超简单实现捕获、串流、播放
上一篇文章说了搭建Nginx的rtmp服务.实现直播功能 期间发现一个更便捷的工具 VLC media play,官方下载:https://www.videolan.org 1.傻瓜式安装,略过 2. ...