ELK集群之grafana(8)


Grafana的安装和读取ES数据
模拟es数据产生sjgtest.py
import time
import datetime
from elasticsearch import Elasticsearch
es = Elasticsearch(['http://elastic:sjgpwd@192.168.238.90:9200', 'http://elastic:sjgpwd@192.168.238.92:9200'])
for i in range(10000):
curtime=datetime.datetime.utcnow().isoformat()
body = {"name": "sjg{0}".format(i), "@timestamp": curtime, "sjgcount": i}
es.index(index='sjg', body=body)
time.sleep(1)
print('insert {0}'.format(i)) Kibana创建sjg索引查看 Grafana安装
yum localinstall grafana-6.7.2-1.x86_64.rpm -y 启动Grafana
systemctl restart grafana-server
访问:端口是3000,默认是admin/admin,密码需要更改
汉化https://github.com/tghfly/grafana-chinese
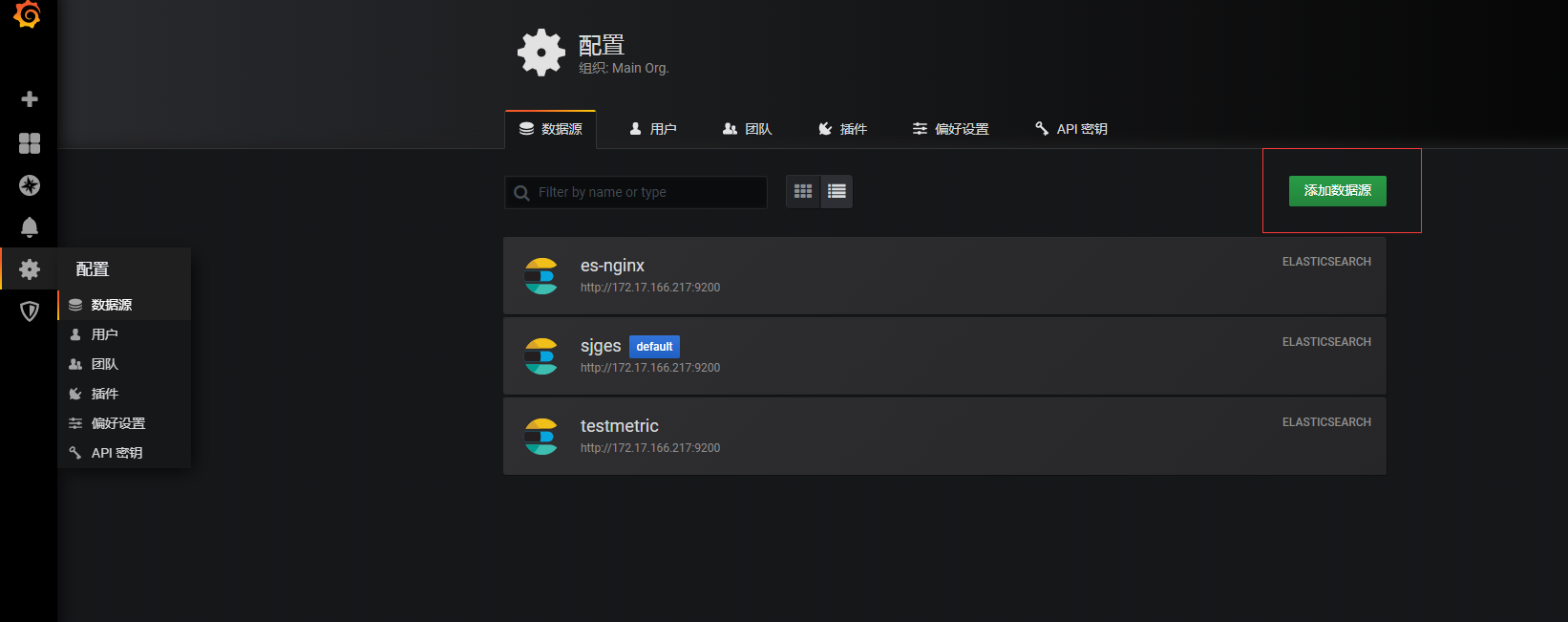
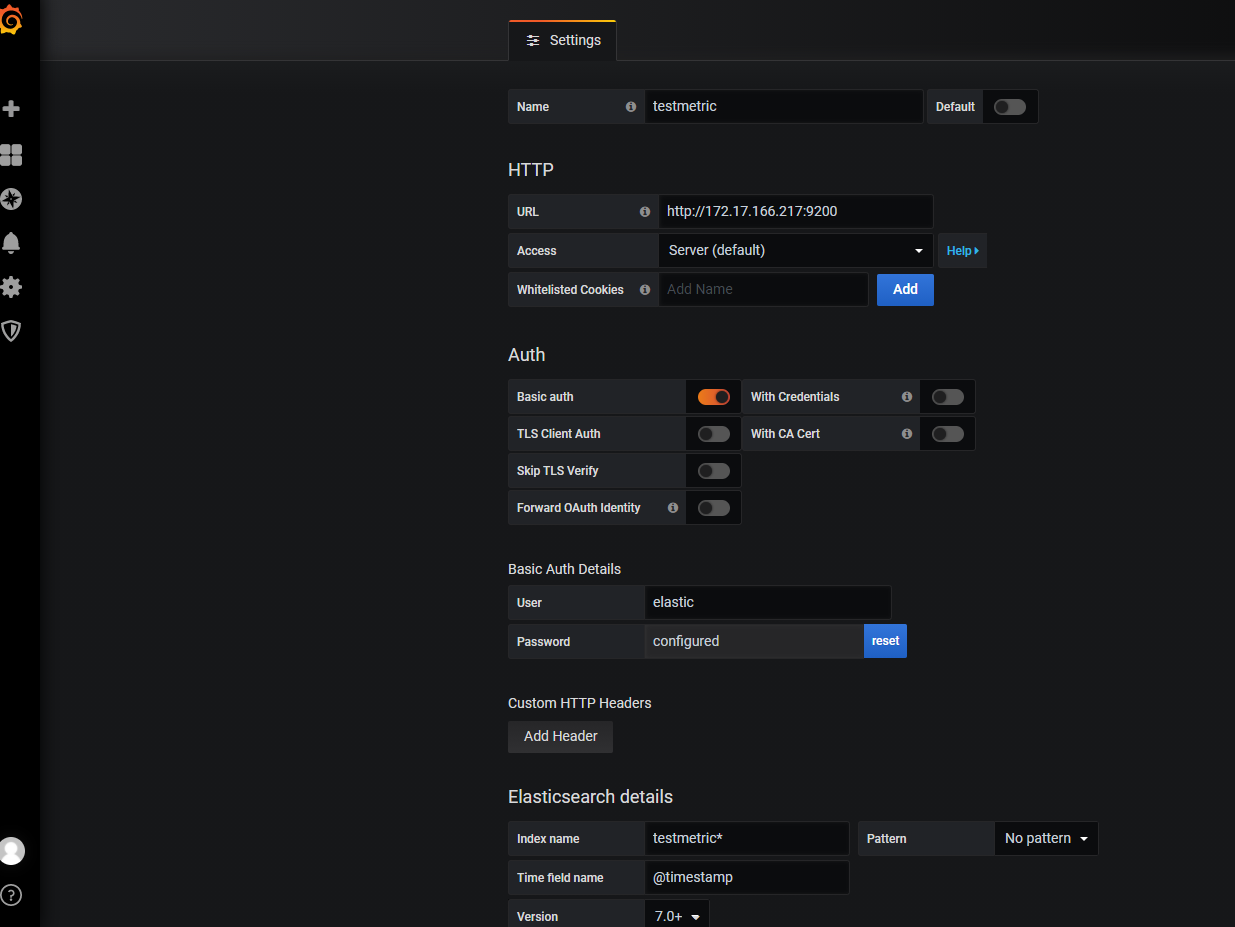
Grafana添加数据源sjges
url: http://192.168.238.90:9200
选择基础认证
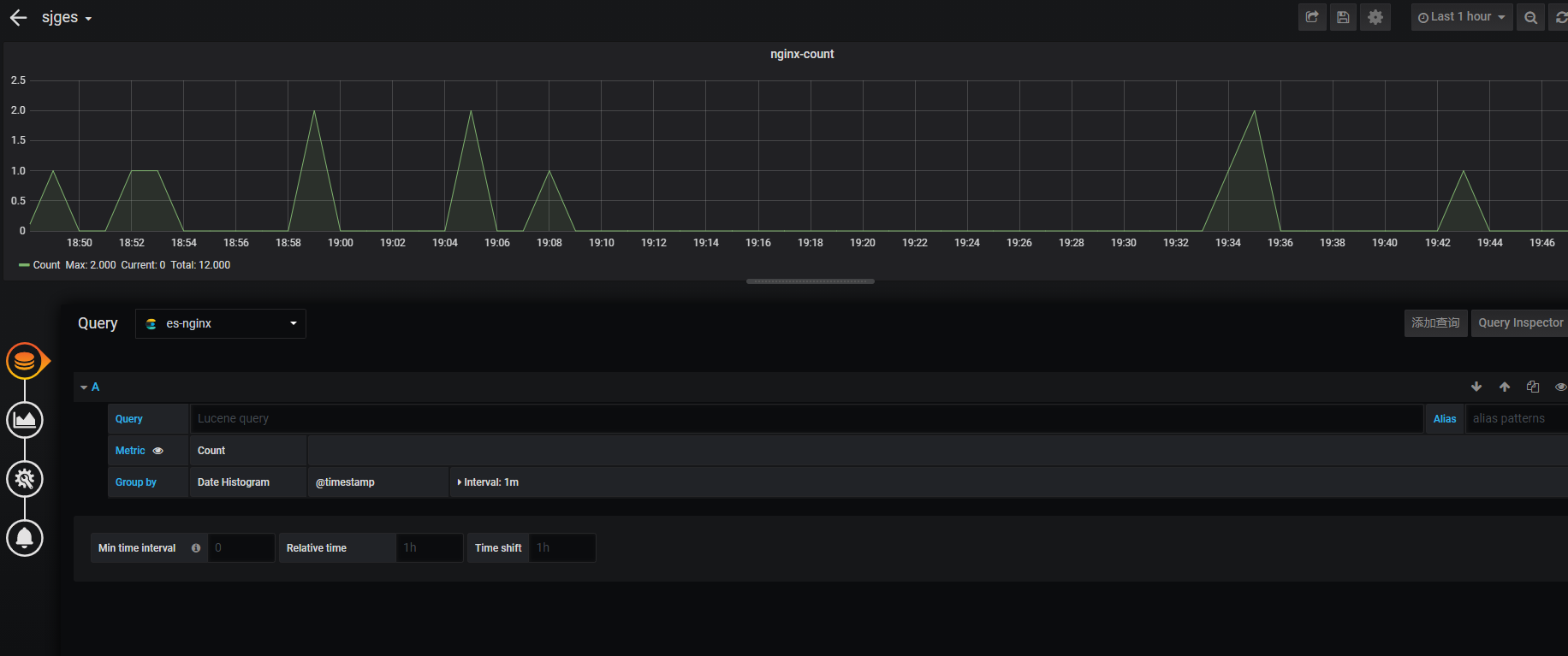
索引和时间配置 最简单的count图创建
Grafana的安装和读取ES数据
启动Grafana
systemctl restart grafana-server
访问:端口是3000,默认是admin/admin,密码需要更改
汉化https://github.com/tghfly/grafana-chinese
Grafana添加数据源sjges
url: http://192.168.238.90:9200
选择基础认证
索引和时间配置
添加数据源
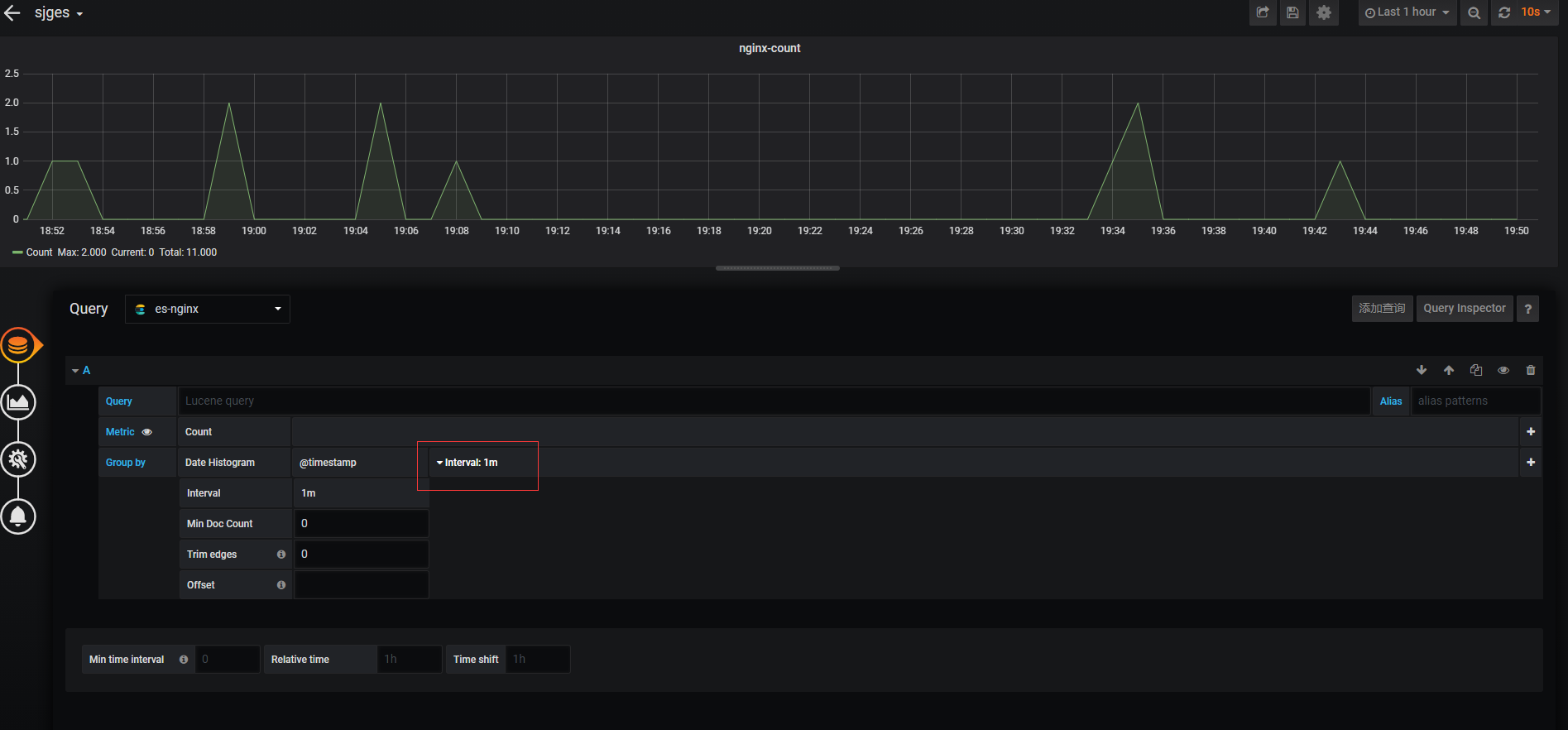
最简单的count图创建
添加绘制饼图工具:
psutil工具安装
yum install gcc python3-devel -y
pip3 install psutil==5.7.0 -i https://mirrors.aliyun.com/pypi/simple/
Grafana多维度展示Nginx日志分析-线图
logstash配置
input {
beats {
host => '0.0.0.0'
port => 5044
}
}
filter {
json {
source => "message"
remove_field => ["message"]
}
}
output {
elasticsearch {
hosts => ["http://192.168.238.90:9200", "http://192.168.238.92:9200"]
user => "elastic"
password => "sjgpwd"
index => "sjgjson-%{+YYYY.MM.dd}"
}
} filebeat配置
filebeat.inputs:
- type: log
tail_files: true
backoff: "1s"
paths:
- /var/log/nginx/access.json.log processors:
- drop_fields:
fields: ["agent","ecs","log","input"] output:
logstash:
hosts: ["192.168.238.90:5044"] 数据模拟
while true;do curl 172.17.166.172/sjg666; curl 172.17.166.172/sjg; curl 127.0.0.1; sleep 5; done
while true;do curl 172.17.166.172/sjg666; curl 172.17.166.172/sjg; curl 39.106.69.56; sleep 5; done
Grafana多维度展示Nginx日志分析-线图
Grafana展现-线图
- 每分钟日志量展现Kibana上有
- IP分布查看term remove_addr_keyword
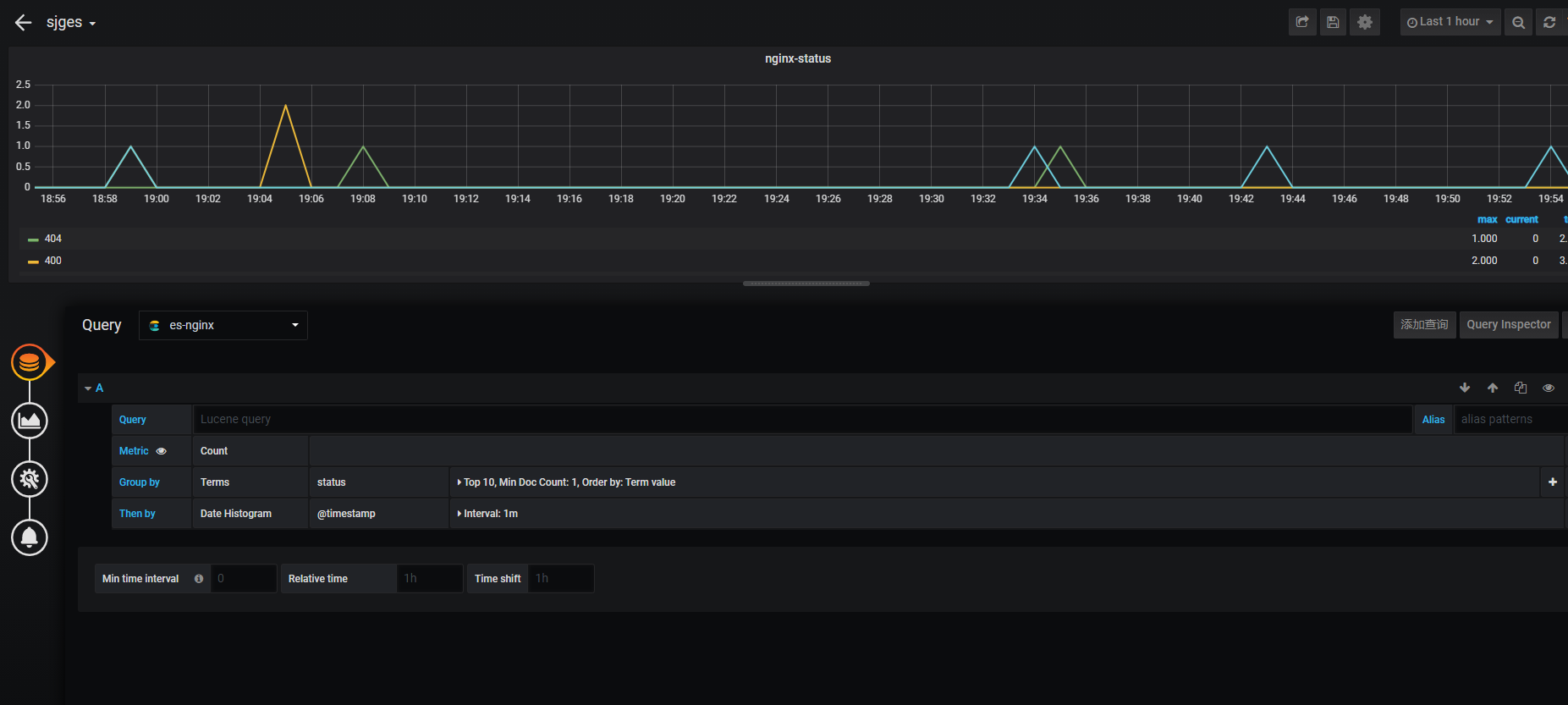
- 状态码分布查看
- 请求分布查看
每分钟日志量展现
IP分布查看term remove_addr_keywor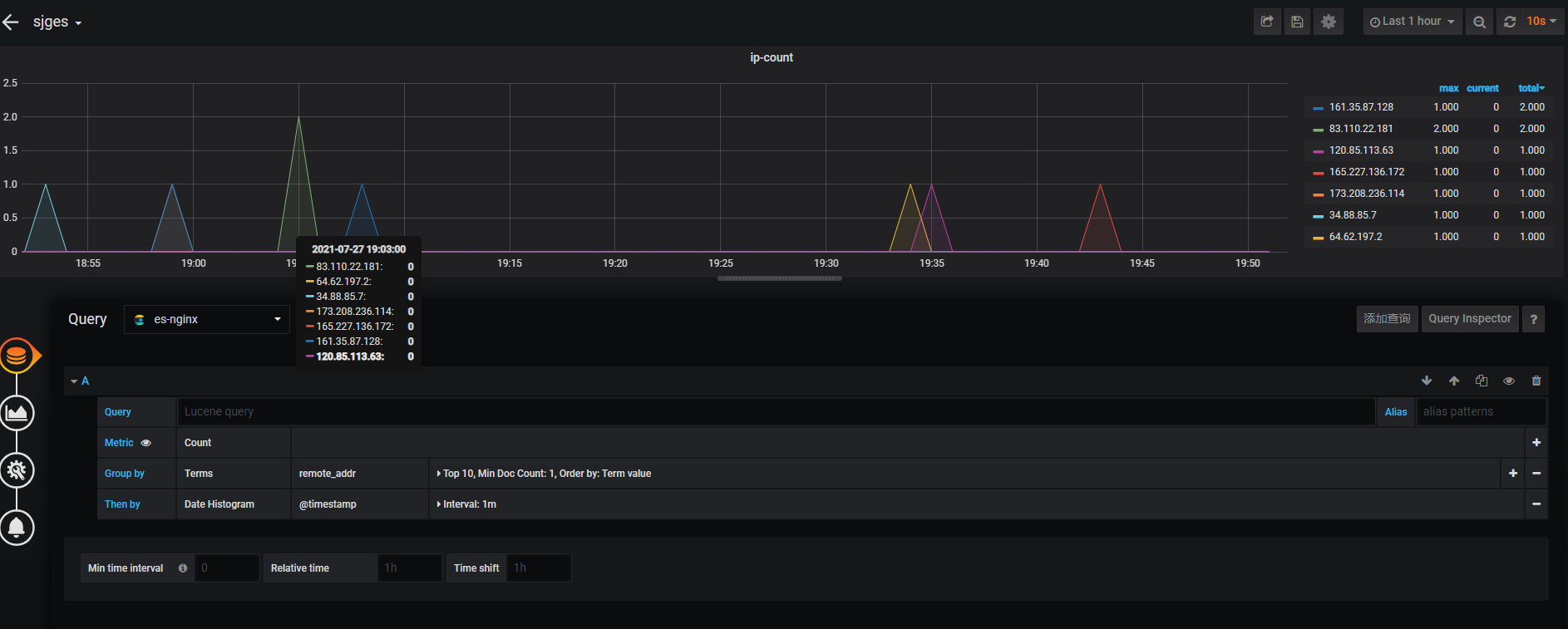
 可选单位 排序方式 展现方式等 以addr进行分组
可选单位 排序方式 展现方式等 以addr进行分组
状态码分布查看
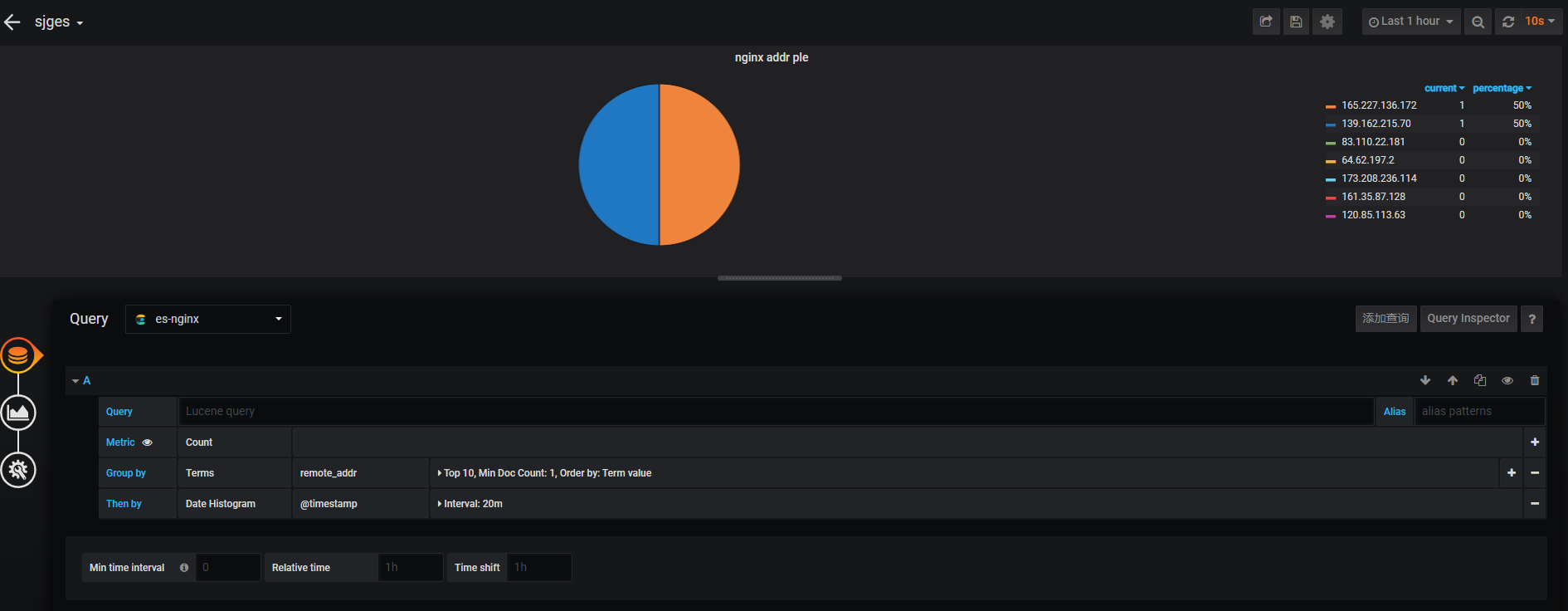
##饼图可选显示样式
请求分布查看

Grafana多维度展示metricbeat采集信息
metricbeat采集系统信息
cpu load
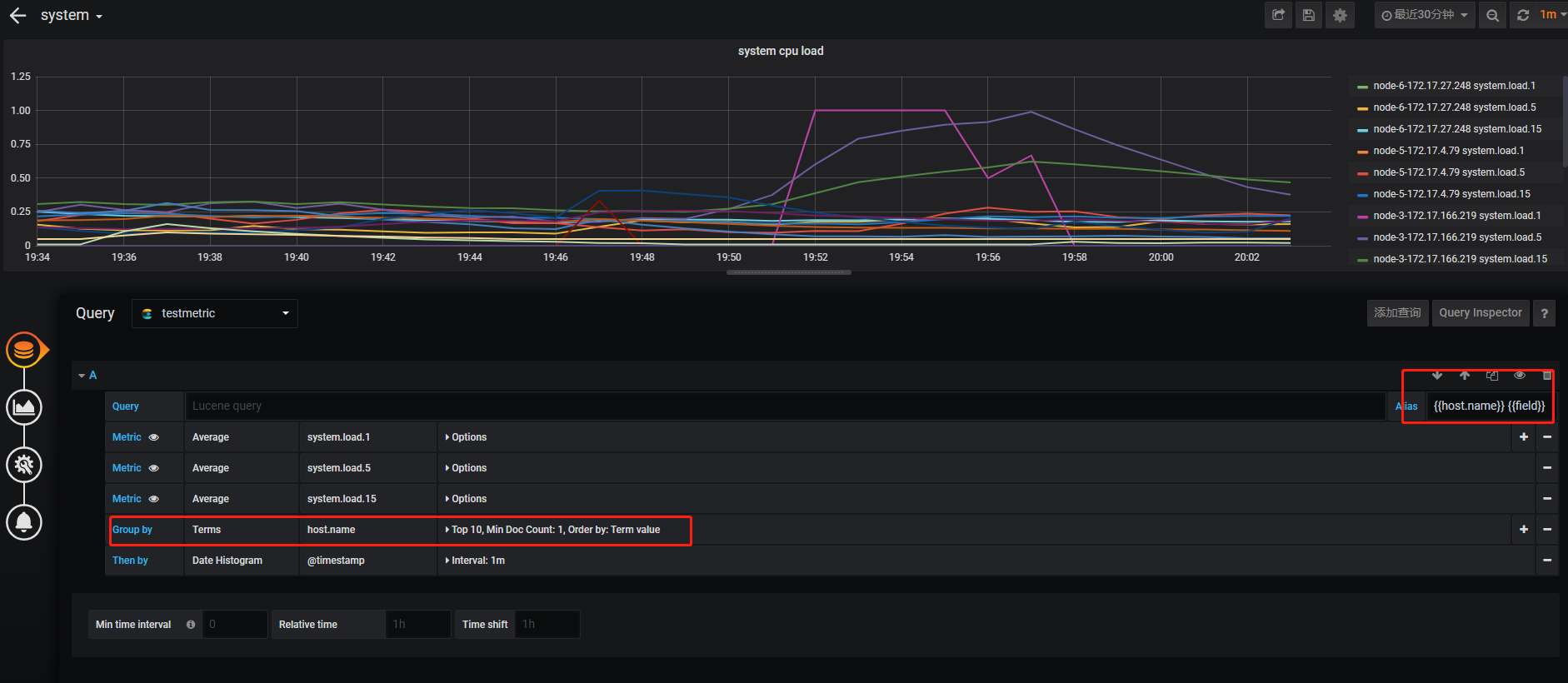
##以hostname分组,显示load1,load5,load15 展示信息输出hostname及field(采集的值的type)
cpu 负载

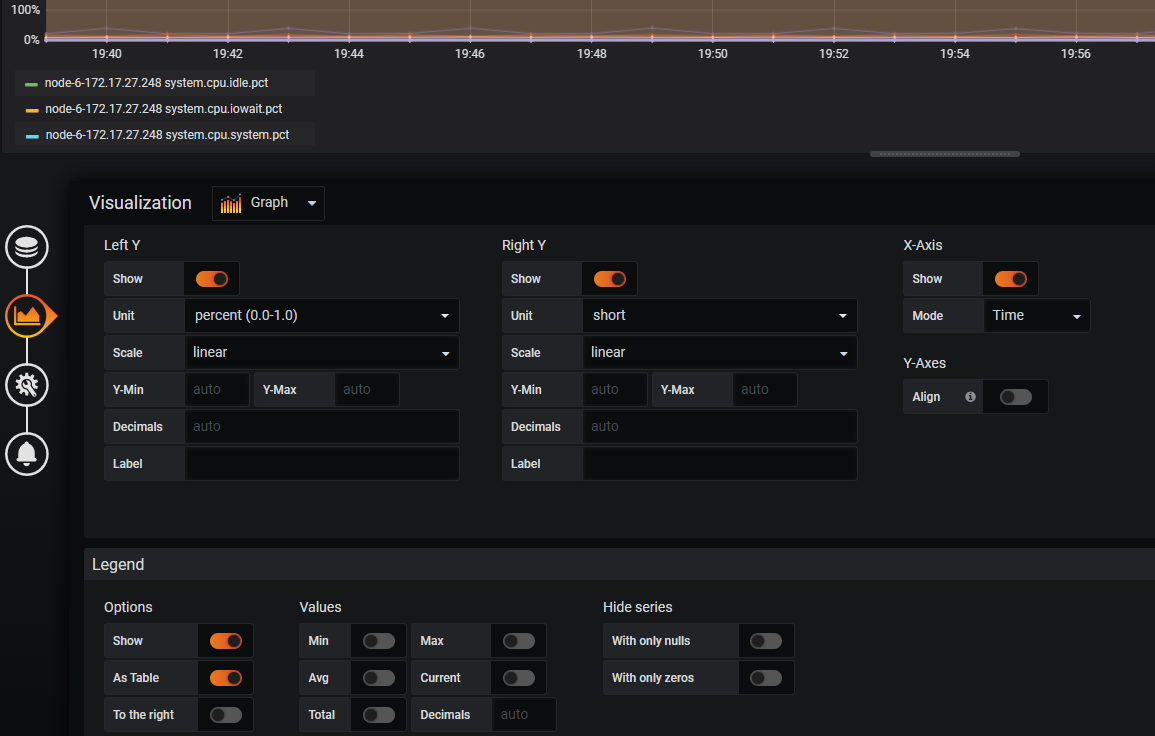 #选择百分比单位
#选择百分比单位
磁盘使用率

内存使用率

流量情况
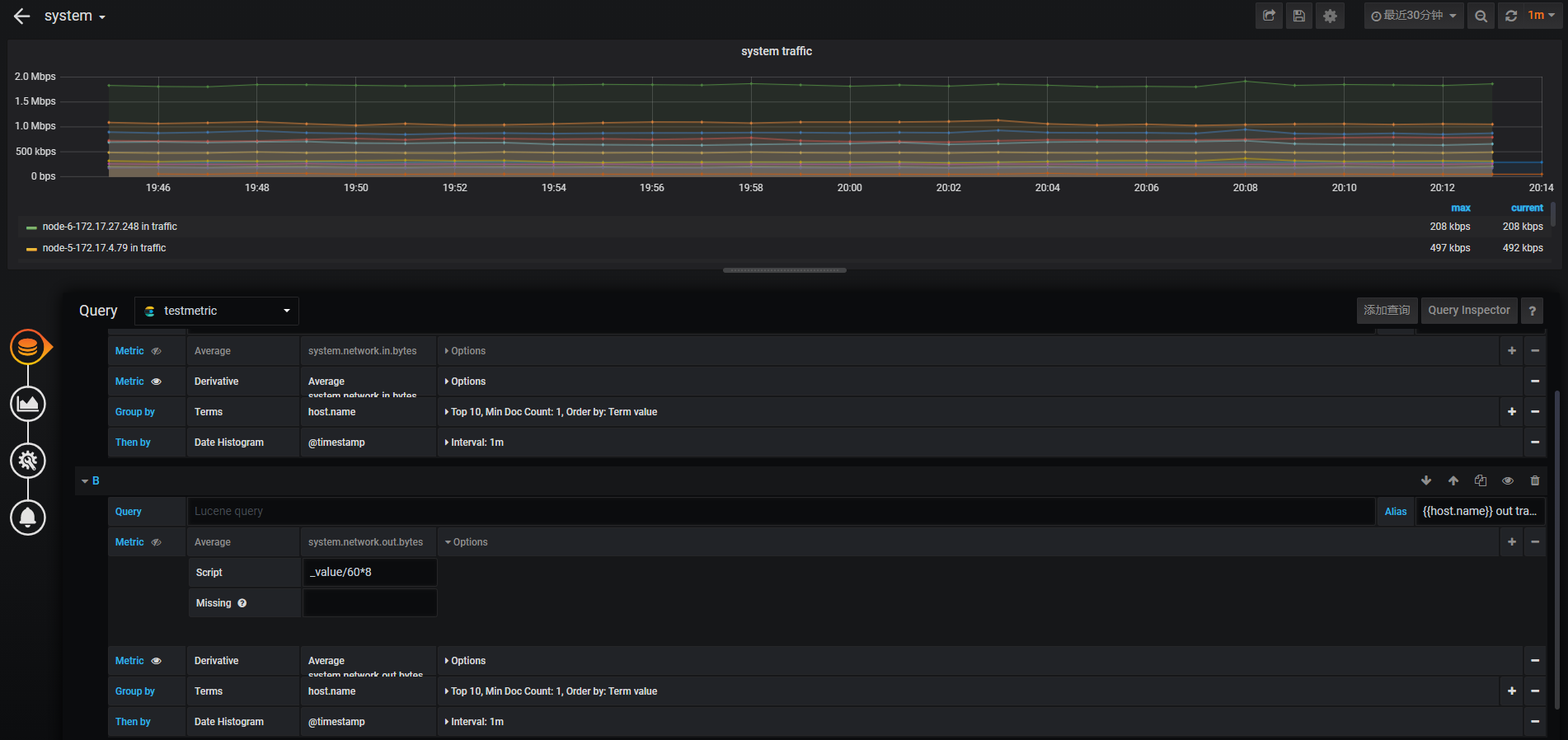
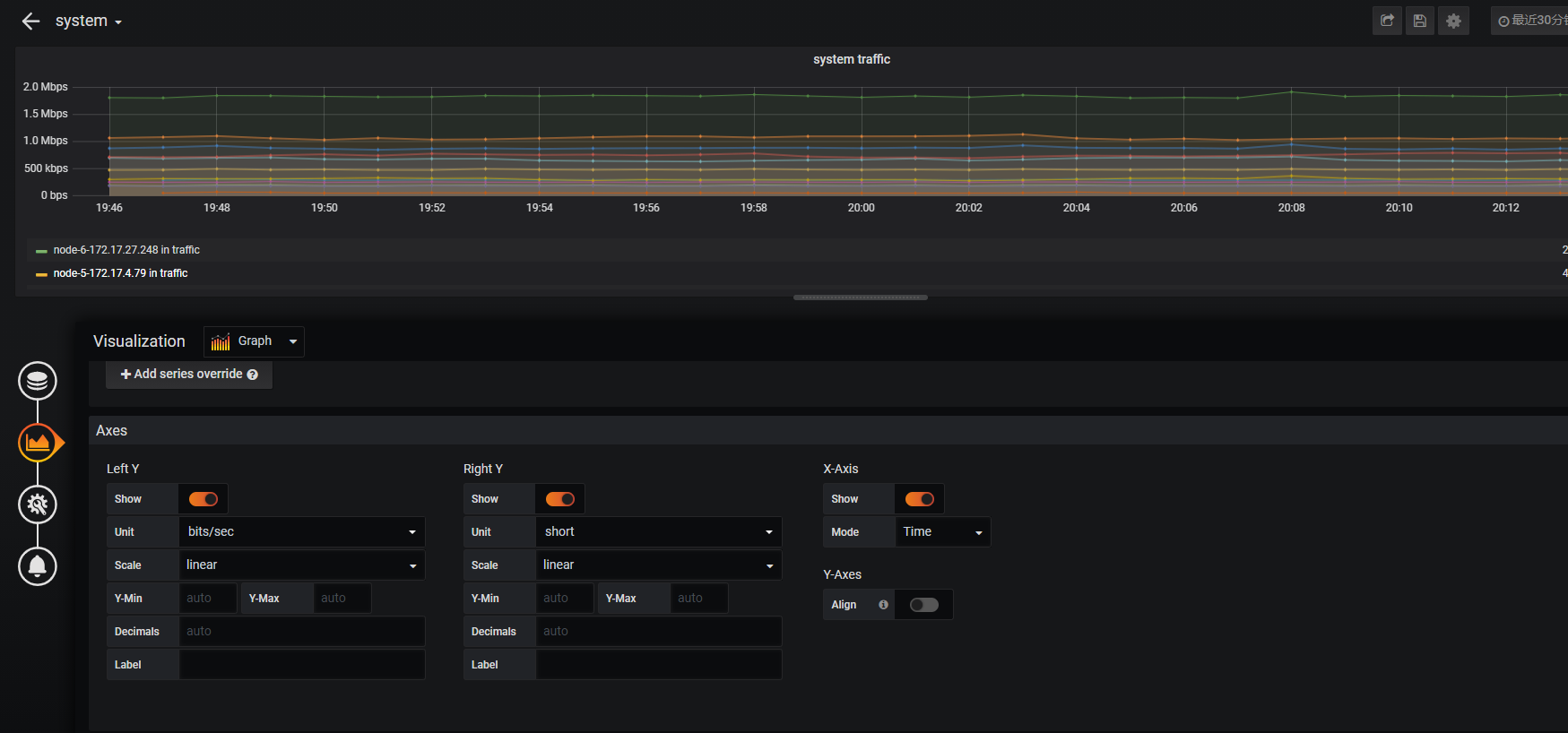
#采集为1分钟总带宽值单位bit,所以要/60等于每秒平均带宽*8字节等于1kb。第二次采集到的值为总值的平均值所以要去减去前一次的平均值。展示的为前一次总消耗量的平均值与后一次总平均量的差值。
nginx每秒访问平均值
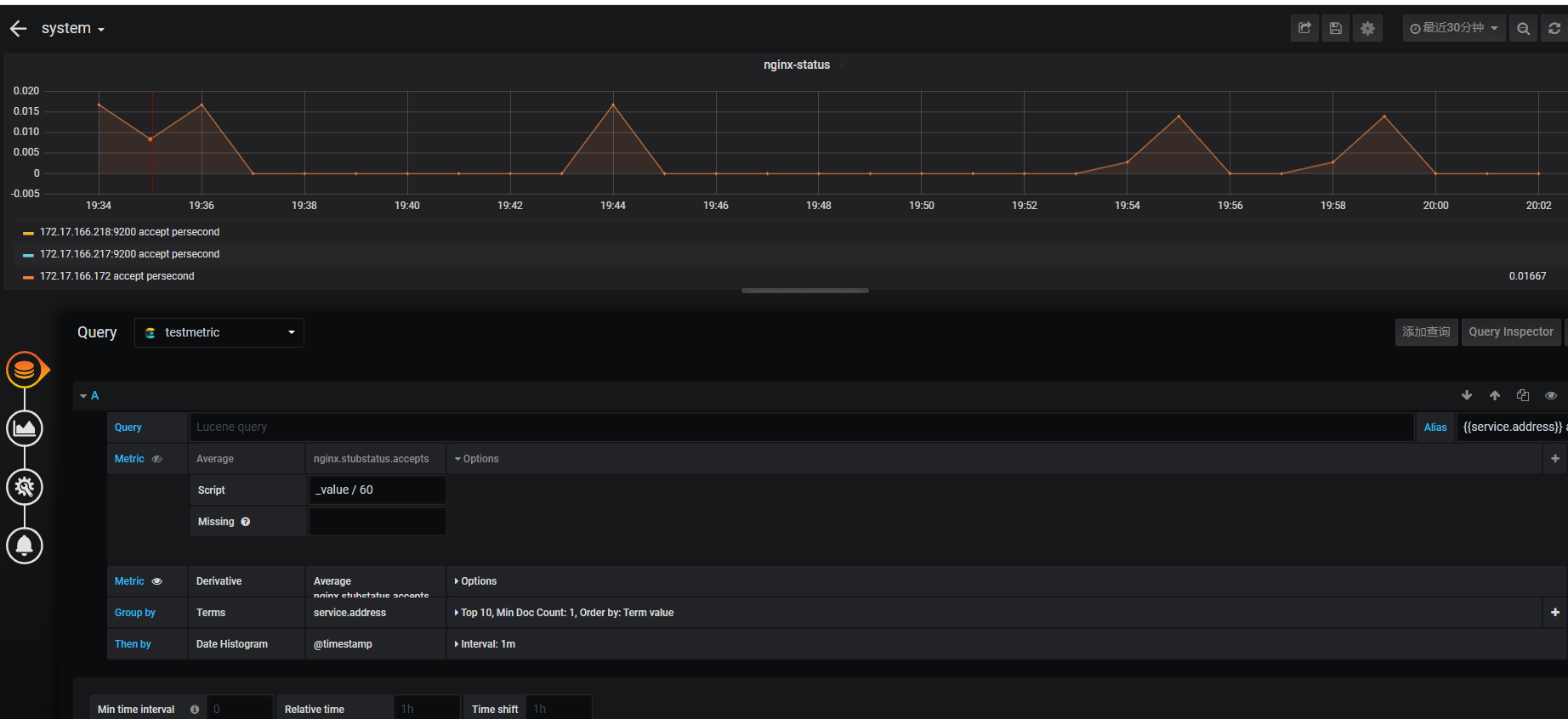
nginx与采集流量类似 都是总的值/60 后一次与前一次结果平均的差为当前nginx访问平均值
ELK集群之grafana(8)的更多相关文章
- Centos7中ELK集群安装流程
Centos7中ELK集群安装流程 说明:三个版本必须相同,这里安装5.1版. 一.安装Elasticsearch5.1 hostnamectl set-hostname elk vim /e ...
- ansible playbook部署ELK集群系统
一.介绍 总共4台机器,分别为 192.168.1.99 192.168.1.100 192.168.1.210 192.168.1.211 服务所在机器为: redis:192.168.1.211 ...
- Kibana安装(图文详解)(多节点的ELK集群安装在一个节点就好)
对于Kibana ,我们知道,是Elasticsearch/Logstash/Kibana的必不可少成员. 前提: Elasticsearch-2.4.3的下载(图文详解) Elasticsearch ...
- elk集群配置配置文件中节点数配多少
配置elk集群时,遇到,elasticsearch配置文件中的一个配置discovery.zen.minimum_master_nodes: 2.这里是三配的2 看到某一位的解释是这样:为了避免脑裂, ...
- Filebeat-1.3.1安装和设置(图文详解)(多节点的ELK集群安装在一个节点就好)(以Console Output为例)
前期博客 Filebeat的下载(图文讲解) 前提 Elasticsearch-2.4.3的下载(图文详解) Elasticsearch-2.4.3的单节点安装(多种方式图文详解) Elasticse ...
- 通过docker搭建ELK集群
单机ELK,另外两台服务器分别有一个elasticsearch节点,这样形成一个3节点的ES集群. 可以先尝试单独搭建es集群或单机ELK https://www.cnblogs.com/lz0925 ...
- ELK集群搭建
基于5台虚拟机,搭建ELK集群. 方案: 1. ELK是日志分析平台,而不是一款软件,是一整套解决方案,是三个软件产品的首字母缩写,ELK分别代表: Elasticsearch:负责日志检索和储存 L ...
- 搭建ELK 集群 rpm安装
上次是使用docker搭建的ELK,三个软件都跑在一台机器的一个docker中,这个就当是测试环境吧. 下面开始搭建正式环境下的ELK集群. 三台服务器 A:logstash B:Elasticsea ...
- ELK集群部署实例(转)
转载自:http://blog.51cto.com/ckl893/1772287,感谢原博. 一.ELK说明 二.架构图 三.规划说明 四.安装部署nginx+logstash 五.安装部署redis ...
随机推荐
- Jmeter系列(13)- 数据库操作之JDBC Connection Configuration配置元件、JDBC Request取样器
Jmeter常见操作数据库场景 准备.制造测试数据 获取.查询测试数据 数据库数据作为参数引用 清理测试环境.删除过程数据 数据库压测 Jmeter操作数据库环境准备 已经安装好的数据库,比如MySq ...
- 微信小程序 创建自己的第一个小程序
* 成为微信公众平台的开发者 注册 https://mp.weixin.qq.com * 登录 https://open.weixin.qq.com/ * 开发者工具下载 https://develo ...
- phpQuery
以下资料均来自官方文档,官方文档地址:https://code.google.com/archive/p/phpquery/wikis 基础 示例 phpQuery::newDocumentFileX ...
- Python3入门系列之-----json与字典转换
json JSON(JavaScript Object Notation) 是一种轻量级的数据交换格式,易于人阅读和编写 JSON 函数 使用 JSON 函数需要导入 json 库:import js ...
- apiserver源码分析——启动流程
前言 apiserver是k8s控制面的一个组件,在众多组件中唯一一个对接etcd,对外暴露http服务的形式为k8s中各种资源提供增删改查等服务.它是RESTful风格,每个资源的URI都会形如 / ...
- BurpSuite 功能概览
简介 写作思想:相比较具体介绍某个功能的用法.会更加侧重于介绍 Burp 提供哪些功能.这样好处是在比较复杂的测试场景,如果Burp 刚好提供对应的功能,就不用花费精力造轮子了. 而需要掌握具体操作方 ...
- 树上DFS序在换根时的变化规律
其中\(12324215\)为循环链表,可用双倍空间存(如图)
- 题解 [HNOI2016]大数
题目传送门 题目大意 给出一个\(n\)个数的字符串,有\(m\)次查询,对于该串的子串\([l,r]\)有多少个子串满足是固定素数\(p\)的倍数. 思路 其实很简单,但是一开始想偏了...果然还是 ...
- bzoj5210最大连通子块和 (动态dp+卡常好题)
卡了一晚上,经历了被卡空间,被卡T,被卡数组等一堆惨惨的事情之后,终于在各位大爹的帮助下过了这个题qwqqq (全网都没有用矩阵转移的动态dp,让我很慌张) 首先,我们先考虑一个比较基础的\(dp\) ...
- 洛谷4455 [CQOI2018]社交网络 (有向图矩阵树定理)(学习笔记)
sro_ptx_orz qwq算是一个套路的记录 对于一个有向图来说 如果你要求一个外向生成树的话,那么如果存在一个\(u\rightarrow v\)的边 那么\(a[u][v]--,a[v][v] ...