Local Relation Networks for Image Recognition
概
一种特殊的卷积?
主要内容
CNN通过许许多多的filters进行模式匹配(a pattern matching process), 非常低效, 本文提出利用局部相关性来替代这些卷积层.
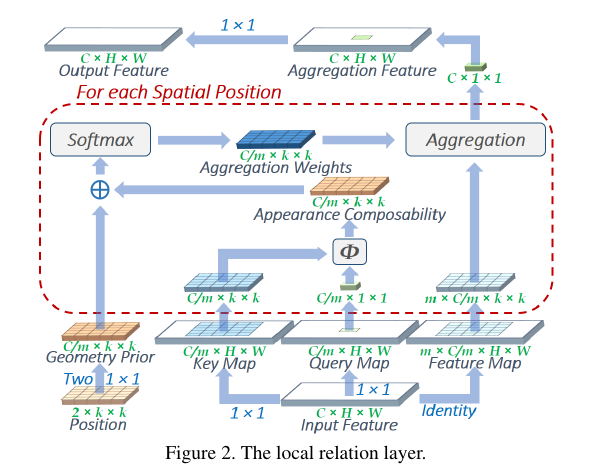
输入特征图\(X \in \mathbb{R}^{C \times H \times W}\);
特征图通过1x1的卷积(channel transformation layer)分别获得key map, query map, 二者的大小均为\(C/m \times H \times W\);
对于query map上的每一个点\(q_{p'}\), 计算其与kxk邻域内的点\(k_p\)间的relation:
\[w(p', p) = \mathrm{softmax}(\Phi(q_{p'}, k_p) + f_{\theta_g}(p - p')),
\]其中
\[\Phi(q_{p'}, k_p) = -(q_{p'}-k_q)^2,
\]\(f_{\theta_g}(p-p')\)是通过两层1x1卷积获得的\(C/m \times k \times k\), 反映了Geometry Prior, 实际上就是相对距离的度量.
注: 因为每个\(p\)都可以用\((h, w)\)来表示点的位置, 故途中的Position是两个通道的.
此时, 对于feature map中的任一点\(p\)都有了对应的\(w\), 通过此可以计算出一个对应的值, 于是可以得到\(C \times H \times W\)的新的特征图, 概特征图反应了点与其对应的kxk邻域内的点的相对关系. 需要注意的是, 图中是\(m \times C/m \times k \times k\)的形式呈现, 这是因为作者令每\(m\)个通道共享一个relation \(w\)(用于减少计算量), 等价于每个点会被作用\(C/ m\)个kernel, 故aggregation weights 是\(C/m\)个通道的.
最后, 再通过1x1的卷积将特征图转换为\(C'\times H \times W\)的输出, 图中应该是作者的笔误.
看起来整个网络的权重似乎很少啊, 都是1x1的卷积.
Local Relation Networks for Image Recognition的更多相关文章
- Paper Reading: Relation Networks for Object Detection
Relation Networks for Object Detection笔记 写在前面:关于这篇论文的背景知识,请参考我前面的两篇随笔(<关于目标检测>和<关于注意力机制> ...
- 【ML】Two-Stream Convolutional Networks for Action Recognition in Videos
Two-Stream Convolutional Networks for Action Recognition in Videos & Towards Good Practices for ...
- 目标检测--Spatial pyramid pooling in deep convolutional networks for visual recognition(PAMI, 2015)
Spatial pyramid pooling in deep convolutional networks for visual recognition 作者: Kaiming He, Xiangy ...
- Spatial Pyramid Pooling in Deep Convolutional Networks for Visual Recognition
Spatial Pyramid Pooling in Deep Convolutional Networks for Visual Recognition Kaiming He, Xiangyu Zh ...
- SPPNet论文翻译-空间金字塔池化Spatial Pyramid Pooling in Deep Convolutional Networks for Visual Recognition
http://www.dengfanxin.cn/?p=403 原文地址 我对物体检测的一篇重要著作SPPNet的论文的主要部分进行了翻译工作.SPPNet的初衷非常明晰,就是希望网络对输入的尺寸更加 ...
- Spatial-Temporal Relation Networks for Multi-Object Tracking
Spatial-Temporal Relation Networks for Multi-Object Tracking 2019-05-21 11:07:49 Paper: https://arxi ...
- 深度学习论文翻译解析(九):Spatial Pyramid Pooling in Deep Convolutional Networks for Visual Recognition
论文标题:Spatial Pyramid Pooling in Deep Convolutional Networks for Visual Recognition 标题翻译:用于视觉识别的深度卷积神 ...
- 论文阅读笔记二十五:Spatial Pyramid Pooling in Deep Convolutional Networks for Visual Recognition(SPPNet CVPR2014)
论文源址:https://arxiv.org/abs/1406.4729 tensorflow相关代码:https://github.com/peace195/sppnet 摘要 深度卷积网络需要输入 ...
- 卷积神经网络用于视觉识别Convolutional Neural Networks for Visual Recognition
Table of Contents: Architecture Overview ConvNet Layers Convolutional Layer Pooling Layer Normalizat ...
随机推荐
- OpenStack——云平台部署
一.配置网络 准备:安装两台最小化的CentOS7.2的虚拟机,分别添加两张网卡,分别为仅主机模式和NAT模式,并且计算节点设置为4G运行内存,50G硬盘 1.控制节点--配置网络 控制节点第一个网卡 ...
- Rational Rose的安装及使用教程(包括菜单命令解释、操作向导说明、快捷命令说明)
一.安装教程 我安装时用的是镜像文件,所以安装前需要辅助软件来处理镜像文件.我用到的是UltraISO.UltraISO中文名叫软碟通 是一款功能强大而又方便实用的光盘映像文件的制作/编辑/转换工具, ...
- [PE]结构分析与代码实现
PE结构浅析 知识导向: 程序最开始是存放在磁盘上的,运行程序首先需要申请4GB的内存,将程序从磁盘copy到内存,但不是直接复制,而是进行拉伸处理. 这也就是为什么会有一个文件中地址和一个Virtu ...
- jenkins之授权和权限管理
#:创建角色,给角色授权,然后创建用户,将用户加入到角色(前提先安装插件) #:先将之前的卸载掉 #:然后重启服务,在可选插件搜索Role #:装完重启服务 root@ubuntu:~# system ...
- Linux学习 - 关机重启退出命令
一.shutdown 1 功能 关机.重启操作 2 语法 shutdown [-chr] [时间选项] -h 关机 -r 重启 -c 取消前一个关机命令 二.halt.poweroff(关机) 三 ...
- 【编程思想】【设计模式】【结构模式Structural】门面模式/外观模式Facade
Python版 https://github.com/faif/python-patterns/blob/master/structural/facade.py #!/usr/bin/env pyth ...
- Java-如何合理的设置线程池大小
想要合理配置线程池线程数的大小,需要分析任务的类型,任务类型不同,线程池大小配置也不同. 配置线程池的大小可根据以下几个维度进行分析来配置合理的线程数: 任务性质可分为:CPU密集型任务,IO密集型任 ...
- 5、Redis五大基本数据类型——String类型
一.Redis支持数据类型简介 Redis支持五种数据类型:string(字符串),hash(哈希),list(列表),set(集合)及zset(sorted set:有序集合). 二.String类 ...
- java JDK8 时间处理
目录 时间格式化 LocalDate:年月日 LocalTime:时分秒毫秒 LocalDateTime:年月日时分秒 Instant:纳秒时间戳 Duration:两时间间隔 Duration:处理 ...
- ☕【Java深层系列】「技术盲区」让我们一起去挑战一下如何读取一个较大或者超大的文件数据!
Java的文件IO流处理方式 Java MappedByteBuffer & FileChannel & RandomAccessFile & FileXXXputStream ...