阅读笔记——长文本匹配《Matching Article Pairs with Graphical Decomposition and Convolutions》
论文题目:Matching Article Pairs with Graphical Decomposition and Convolutions
发表情况:ACL2019 腾讯PCG小组
模型简介
模型如图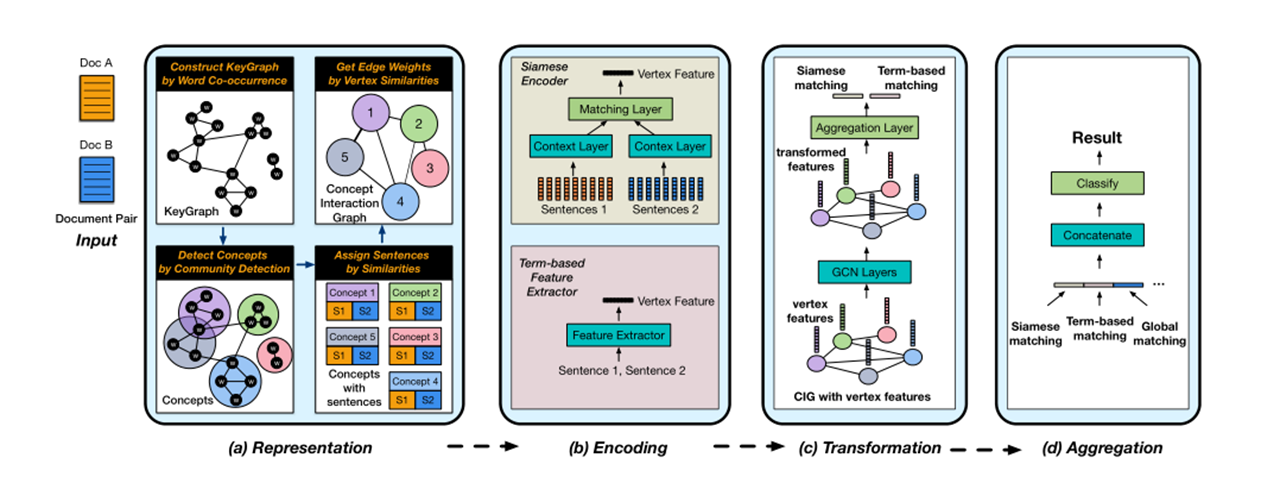
本文的工作是基于概念图 Concept Interac-tion Graph (CIG)来做的,关于CIG的详细解释可以参看腾讯发的另一篇论文:A User-Centered Concept Mining System for Query and Document Understanding at Tencent。
模型的输入是文档级别的,具体来说就是以一对粒度为文档级别的长文本。
1.KeyGraph构建
对于给定的文档D,首先利用TextRank来提取命名实体和关键字,然后根据找到的关键词构建共现图,如果两个关键字同时出现在同一句子中,我们将它们用边连接起来。
2.Concept检测(可选)
如果关键字的子集高度相关,则它们将在KeyGraph中形成紧密连接的子图,我们称之为概念。可以通过在构造的KeyGraph上应用社区检测算法来提取概念,这实际上是一个关键词聚类的过程,对于可能出现在多个概念中的关键词,使用度中心性来进行评分。但是这一步时可选择的,也可以直接用关键词来作为概念,但是匹配速度会有所减慢。
3.句子附加
对文档Da,Db的句子分别与各个概念计算余弦相似度(向量由TF-IDF表示),这样每个概念就得到分别对应文档Da,Db的两个句子集。与文档中任何概念都不匹配的句子将附加到不包含任何关键字的虚拟顶点。
4.边的构建
任意两个顶点之间的边权重,是由它们的句子集之间的TF-IDF相似度表示的。
5.节点匹配特征编码
对每个节点上的文本对(来自两篇文章的句子集合分别进行拼接)进行匹配,得到匹配特征。我们分别尝试了 Siamese Encoder 自动学习匹配特征:将两个句子集(序列的word embeddings)送入共享相同权重的上下文层将它们编码为两个上下文向量,CA(v),CB(V),然后通过公式\(mAB(v) = (|cA(v) − cB(v)|,cA(v) ◦ cB(v))\),得到节点特征;计算各种 term-based 特征来作为节点特征向量:TF-IDF余弦相似度,TF余弦相似度,BM25余弦相似度,1-gram的Jaccard相似度和Ochiai相似度,拼接\(m'AB(v)\),得到匹配向量\(x_{i}\)。
6.通过GCN进行节点特征的转化
GCN的输入为X与A,其中\(X=\left \{ x_{i} \right \}_{i=1}^{N}\),A是一个邻接矩阵,\(A_{ij}= w{_{ij}}\),对于GCN来说某一隐藏层可以表示为:\(f\left ( H^{(l)},A \right )=\sigma \left ( \hat{D}^{-\frac{1}{2}}\hat{A}\hat{D}^{-\frac{1}{2}}H^{(l)}W^{(l)}\right )\),\(\hat{A}\)是A加上一个单位矩阵得来的,\(\hat{D}\)是一个对角阵,\(\hat{D}_{ii}= \sum _{j}\hat{A}{_{ij}}\)。我们将最终经过GCN转化后的特征,整合成一个向量(这里采用了 mean aggregation),即获取最后一层中所有顶点的隐藏向量的平均值。
7.整合分类
在经过GCN层转化后,所得到的向量还可以拼接一些全局的特征,例如通过使用最新的语言模型(例如BERT)直接编码两个文档或直接计算它们term-based的相似度。但是论文实验部分证明这样的全局特征几乎无法给我们的方案带来更多好处,因为图形合并的匹配向量已经在我们的问题中充分表达了。我们将这些最终整合的特征向量,通过分类网络(例如多层感知器(MLP))进行计算,得到匹配分数。
结束
由于只是泛读了这篇文章,没有对实验和代码进行深入分析,想了解更多的可以去看原文。
相关链接:
论文地址:https://arxiv.org/abs/1802.07459
相关数据资源:https://github.com/BangLiu/ArticlePairMatching
阅读笔记——长文本匹配《Matching Article Pairs with Graphical Decomposition and Convolutions》的更多相关文章
- Deep Learning of Graph Matching 阅读笔记
Deep Learning of Graph Matching 阅读笔记 CVPR2018的一篇文章,主要提出了一种利用深度神经网络实现端到端图匹配(Graph Matching)的方法. 该篇文章理 ...
- text matching(文本匹配) 相关资料总结
最近工作上需要做句子语义去重相关的工作,本质上这是属于NLP中text matching(文本匹配)相关的内容.因此我花了一些时间整理了一些关于这个方向的资料,整理如下(也许会持续更新): BiMPM ...
- TextRCNN 文本分类 阅读笔记
TextRCNN 文本分类 阅读笔记 论文:recurrent convolutional neural networks for text classification 代码(tensorflow) ...
- 跨模态语义关联对齐检索-图像文本匹配(Image-Text Matching)
论文介绍:Negative-Aware Attention Framework for Image-Text Matching (基于负感知注意力的图文匹配,CVPR2022) 代码主页:https: ...
- Mongodb Manual阅读笔记:CH7 索引
7索引 Mongodb Manual阅读笔记:CH2 Mongodb CRUD 操作Mongodb Manual阅读笔记:CH3 数据模型(Data Models)Mongodb Manual阅读笔记 ...
- 《C#程序设计教程 -李春保》阅读笔记
<C#程序设计教程 -李春保>阅读笔记 ( 需注意程度:红>粗体>下划线,蓝色:我的疑问 ) 老师的引言 [师]对待一种新语言的关注点 数据类型定义(python不用定 ...
- Hadoop阅读笔记(二)——利用MapReduce求平均数和去重
前言:圣诞节来了,我怎么能虚度光阴呢?!依稀记得,那一年,大家互赠贺卡,短短几行字,字字融化在心里:那一年,大家在水果市场,寻找那些最能代表自己心意的苹果香蕉梨,摸着冰冷的水果外皮,内心早已滚烫.这一 ...
- CI框架源码阅读笔记3 全局函数Common.php
从本篇开始,将深入CI框架的内部,一步步去探索这个框架的实现.结构和设计. Common.php文件定义了一系列的全局函数(一般来说,全局函数具有最高的加载优先权,因此大多数的框架中BootStrap ...
- Mongodb Manual阅读笔记:CH8 复制集
8 复制 Mongodb Manual阅读笔记:CH2 Mongodb CRUD 操作Mongodb Manual阅读笔记:CH3 数据模型(Data Models)Mongodb Manual阅读笔 ...
随机推荐
- ZOJ 3778:Talented Chef(贪心?思维)
Talented Chef Time Limit: 2 Seconds Memory Limit: 65536 KB As we all know, Coach Gao is a talented c ...
- <数据结构>XDOJ.322关键路径长度
问题与解答 问题描述 计算AOE-网中关键路径的长度. 输入格式 输入数据第一行是一个正整数,表示图中的顶点个数n(顶点将分别按0,1,-,n-1进行编号),顶点数不超过100,其中0为源点,n-1为 ...
- Java初学者作业——编写Java程序,简单判断“王者荣耀”英雄收到攻击后是否死亡
返回本章节 返回作业目录 需求说明: 判断"王者荣耀"中英雄受到攻击后是否死亡? 计算"王者荣耀"中怪物攻击英雄的伤害,做出英雄死亡的判断. 如果英雄受到过量伤 ...
- FastStoneCapture屏幕截图软件
1.简介 FastStone Capture(FSCapture)是经典的屏幕截图软件, 可以捕捉全屏图像.活动窗口.任意指定截图形状, 而且还有图像编辑和屏幕录制功能, 还能支持屏幕放大镜和屏幕取色 ...
- JUC之多线程锁问题
多线程锁 8种问题锁状态: 该部分全部围绕的是以下内容并结合相应的例子:synchronized实现同步的基础:Java中每个对象都可以作为锁. 具体表现为以下三种形式:(之前只是简单的了解) 对于普 ...
- Sentry 企业级数据安全解决方案 - Relay 配置选项
Relay 的配置记录在文件 .relay/config.yml 中.要更改此位置,请将 --config 选项传递给任何 Relay 命令: ❯ ./relay run --config /path ...
- python自动化适应多接口的断言怎么做?
最近做的接口自动化,遇到了很多模块的接口,返回的断言不太相同,在放在unnitest单元测试框架+ddt数据驱动,做参数时,发现不能只通过一个方式进行断言,那么,要怎么做才能做到适配当前所有接口的断言 ...
- linux安全篇:禁止频繁访问的ip访问nginx
实验环境 版本:redhat6.5ip:172.16.1.100,172.16.10软件:nginx 172.16.1.10部署nginx [root@localhost tools]# lsngin ...
- spring boot 单元测试 --- 在测试类使用 javabean注解操作接口
1.依赖包 <dependency> <groupId>org.springframework.boot</groupId> <artifactId>s ...
- spring boot + spring security +JWT令牌 +前后端分离--- 心得
1.前言 观看这篇随笔需要有spring security基础. 心得: 1.生成token 的变化数据是用户名和权限拼接的字符串 ,其他的固定 2.生成的token是将登录通过的用户的权限拼接的字符 ...