阅读笔记——长文本匹配《Matching Article Pairs with Graphical Decomposition and Convolutions》
论文题目:Matching Article Pairs with Graphical Decomposition and Convolutions
发表情况:ACL2019 腾讯PCG小组
模型简介
模型如图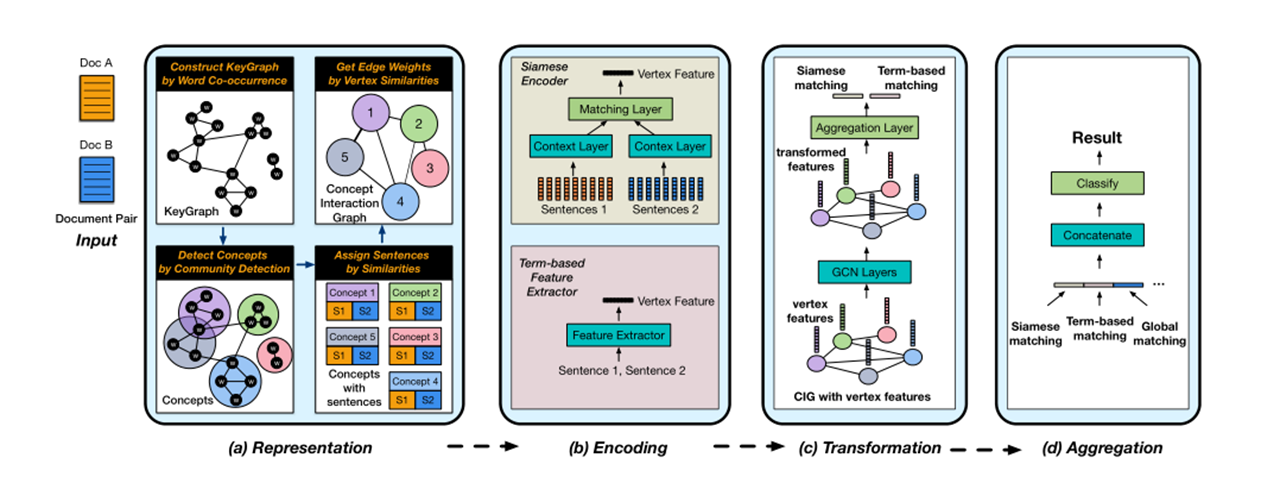
本文的工作是基于概念图 Concept Interac-tion Graph (CIG)来做的,关于CIG的详细解释可以参看腾讯发的另一篇论文:A User-Centered Concept Mining System for Query and Document Understanding at Tencent。
模型的输入是文档级别的,具体来说就是以一对粒度为文档级别的长文本。
1.KeyGraph构建
对于给定的文档D,首先利用TextRank来提取命名实体和关键字,然后根据找到的关键词构建共现图,如果两个关键字同时出现在同一句子中,我们将它们用边连接起来。
2.Concept检测(可选)
如果关键字的子集高度相关,则它们将在KeyGraph中形成紧密连接的子图,我们称之为概念。可以通过在构造的KeyGraph上应用社区检测算法来提取概念,这实际上是一个关键词聚类的过程,对于可能出现在多个概念中的关键词,使用度中心性来进行评分。但是这一步时可选择的,也可以直接用关键词来作为概念,但是匹配速度会有所减慢。
3.句子附加
对文档Da,Db的句子分别与各个概念计算余弦相似度(向量由TF-IDF表示),这样每个概念就得到分别对应文档Da,Db的两个句子集。与文档中任何概念都不匹配的句子将附加到不包含任何关键字的虚拟顶点。
4.边的构建
任意两个顶点之间的边权重,是由它们的句子集之间的TF-IDF相似度表示的。
5.节点匹配特征编码
对每个节点上的文本对(来自两篇文章的句子集合分别进行拼接)进行匹配,得到匹配特征。我们分别尝试了 Siamese Encoder 自动学习匹配特征:将两个句子集(序列的word embeddings)送入共享相同权重的上下文层将它们编码为两个上下文向量,CA(v),CB(V),然后通过公式\(mAB(v) = (|cA(v) − cB(v)|,cA(v) ◦ cB(v))\),得到节点特征;计算各种 term-based 特征来作为节点特征向量:TF-IDF余弦相似度,TF余弦相似度,BM25余弦相似度,1-gram的Jaccard相似度和Ochiai相似度,拼接\(m'AB(v)\),得到匹配向量\(x_{i}\)。
6.通过GCN进行节点特征的转化
GCN的输入为X与A,其中\(X=\left \{ x_{i} \right \}_{i=1}^{N}\),A是一个邻接矩阵,\(A_{ij}= w{_{ij}}\),对于GCN来说某一隐藏层可以表示为:\(f\left ( H^{(l)},A \right )=\sigma \left ( \hat{D}^{-\frac{1}{2}}\hat{A}\hat{D}^{-\frac{1}{2}}H^{(l)}W^{(l)}\right )\),\(\hat{A}\)是A加上一个单位矩阵得来的,\(\hat{D}\)是一个对角阵,\(\hat{D}_{ii}= \sum _{j}\hat{A}{_{ij}}\)。我们将最终经过GCN转化后的特征,整合成一个向量(这里采用了 mean aggregation),即获取最后一层中所有顶点的隐藏向量的平均值。
7.整合分类
在经过GCN层转化后,所得到的向量还可以拼接一些全局的特征,例如通过使用最新的语言模型(例如BERT)直接编码两个文档或直接计算它们term-based的相似度。但是论文实验部分证明这样的全局特征几乎无法给我们的方案带来更多好处,因为图形合并的匹配向量已经在我们的问题中充分表达了。我们将这些最终整合的特征向量,通过分类网络(例如多层感知器(MLP))进行计算,得到匹配分数。
结束
由于只是泛读了这篇文章,没有对实验和代码进行深入分析,想了解更多的可以去看原文。
相关链接:
论文地址:https://arxiv.org/abs/1802.07459
相关数据资源:https://github.com/BangLiu/ArticlePairMatching
阅读笔记——长文本匹配《Matching Article Pairs with Graphical Decomposition and Convolutions》的更多相关文章
- Deep Learning of Graph Matching 阅读笔记
Deep Learning of Graph Matching 阅读笔记 CVPR2018的一篇文章,主要提出了一种利用深度神经网络实现端到端图匹配(Graph Matching)的方法. 该篇文章理 ...
- text matching(文本匹配) 相关资料总结
最近工作上需要做句子语义去重相关的工作,本质上这是属于NLP中text matching(文本匹配)相关的内容.因此我花了一些时间整理了一些关于这个方向的资料,整理如下(也许会持续更新): BiMPM ...
- TextRCNN 文本分类 阅读笔记
TextRCNN 文本分类 阅读笔记 论文:recurrent convolutional neural networks for text classification 代码(tensorflow) ...
- 跨模态语义关联对齐检索-图像文本匹配(Image-Text Matching)
论文介绍:Negative-Aware Attention Framework for Image-Text Matching (基于负感知注意力的图文匹配,CVPR2022) 代码主页:https: ...
- Mongodb Manual阅读笔记:CH7 索引
7索引 Mongodb Manual阅读笔记:CH2 Mongodb CRUD 操作Mongodb Manual阅读笔记:CH3 数据模型(Data Models)Mongodb Manual阅读笔记 ...
- 《C#程序设计教程 -李春保》阅读笔记
<C#程序设计教程 -李春保>阅读笔记 ( 需注意程度:红>粗体>下划线,蓝色:我的疑问 ) 老师的引言 [师]对待一种新语言的关注点 数据类型定义(python不用定 ...
- Hadoop阅读笔记(二)——利用MapReduce求平均数和去重
前言:圣诞节来了,我怎么能虚度光阴呢?!依稀记得,那一年,大家互赠贺卡,短短几行字,字字融化在心里:那一年,大家在水果市场,寻找那些最能代表自己心意的苹果香蕉梨,摸着冰冷的水果外皮,内心早已滚烫.这一 ...
- CI框架源码阅读笔记3 全局函数Common.php
从本篇开始,将深入CI框架的内部,一步步去探索这个框架的实现.结构和设计. Common.php文件定义了一系列的全局函数(一般来说,全局函数具有最高的加载优先权,因此大多数的框架中BootStrap ...
- Mongodb Manual阅读笔记:CH8 复制集
8 复制 Mongodb Manual阅读笔记:CH2 Mongodb CRUD 操作Mongodb Manual阅读笔记:CH3 数据模型(Data Models)Mongodb Manual阅读笔 ...
随机推荐
- 【LeetCode】969. Pancake Sorting 解题报告(Python & C++)
作者: 负雪明烛 id: fuxuemingzhu 个人博客: http://fuxuemingzhu.cn/ 目录 题目描述 题目大意 解题方法 模拟法 日期 题目地址:https://leetco ...
- Back to Underworld(lightoj 1009)
1009 - Back to Underworld PDF (English) Statistics Forum Time Limit: 4 second(s) Memory Limit: 32 ...
- Codeforces 1076G Array Game 题解
目录 题目大意 做法 代码 不想写昨天晚上cf的比赛题目所以来写题解摸摸鱼 题目大意 有一个在长度为\(k\)的正整数序列\(b\)上进行的游戏,一开始一个棋子放在位置\(1\),假如当前棋子的位置为 ...
- Codeforces 450C:Jzzhu and Chocolate(贪心)
C. Jzzhu and Chocolate time limit per test: 1 seconds memory limit per test: 256 megabytes input: st ...
- React MobX 开始
MobX 用于状态管理,简单高效.本文将于 React 上介绍如何开始,包括了: 了解 MobX 概念 从零准备 React 应用 MobX React.FC 写法 MobX React.Compon ...
- mysql多条件过滤查询之mysq高级查询
一.什么是高级查询: ① 多条件的过滤查询 简单说,即拼接sql语句,在sql查询语句之后使用: where 条件1 and/or 条件2 and/or 条件3 - ② 分页查询 二.多条件过滤查询: ...
- Java:对一个对象序列化和反序列化的简单实现
名词解释 序列化:将Java对象转化成字节的过程 反序列化:将字节转化成Java对象的过程 字节:1字节(byte)= 8bit,bit就是计算机认识的二进制 序列化的作用 Java对象是在Java虚 ...
- TKE 用户故事 | 作业帮 Kubernetes 原生调度器优化实践
作者 吕亚霖,2019年加入作业帮,作业帮架构研发负责人,在作业帮期间主导了云原生架构演进.推动实施容器化改造.服务治理.GO微服务框架.DevOps的落地实践. 简介 调度系统的本质是为计算服务/任 ...
- MongoDB分片集群搭建及扩容
### 实验:分片集群搭建及扩容#### 实验目标及流程 * 目标:学习如何搭建一个两分片的分片集群 * 环境:3台Linux虚拟机器,4Core 8GB * 步骤: * 配置域名解析 * 准备分片目 ...
- centos8 yum安装nginx后启动不了nginx
起动报下列错误 移动到安装目录下起动报下列错误,说是端口被占用 输入journalctl -xe命令查看,发现如下: 这个是一个什么错误,度娘一下SElinux 输入sestatus查看下SElinu ...