Dapper, Ef core, Freesql 插入大量数据性能比较(一)
需求:导入9999行数据时Dapper, Ef core, Freesql 谁的性能更优,是如何执行的,级联增加谁性能更佳。
确认方法:sql server 的 sys.dm_exec_query_stats
SELECT TOP 1000 (select [text] from sys.dm_exec_sql_text(QS.sql_handle)) as '数据库语句',
QS.execution_count AS '执行次数',
QS.total_elapsed_time AS '耗时',
QS.total_logical_reads AS '逻辑读取次数',
QS.total_logical_writes AS '逻辑写入次数',
QS.total_physical_reads AS '物理读取次数',
QS.creation_time AS '执行时间',
*
FROM sys.dm_exec_query_stats QS
WHERE QS.creation_time > '2021-04-11 09:42:30'
准备:创建表
CREATE TABLE [dbo].[TestAddSortByXXXX](
[Id] [int] IDENTITY(1,1) NOT NULL,
[No] [int] NULL,
[Col1] [nvarchar](50) NULL,
[Col2] [nvarchar](50) NULL,
[Col3] [nvarchar](50) NULL,
[Col4] [nvarchar](50) NULL,
[Col5] [nvarchar](50) NULL,
[Col6] [nvarchar](50) NULL,
[Col7] [nvarchar](50) NULL,
[Col8] [nvarchar](50) NULL,
[Col9] [nvarchar](50) NULL,
[Col10] [nvarchar](50) NULL,
CONSTRAINT [PK_TestAddSortByXXXX] PRIMARY KEY CLUSTERED
(
[Id] ASC
)WITH (PAD_INDEX = OFF, STATISTICS_NORECOMPUTE = OFF, IGNORE_DUP_KEY = OFF, ALLOW_ROW_LOCKS = ON, ALLOW_PAGE_LOCKS = ON) ON [PRIMARY]
) ON [PRIMARY]
GO
CREATE TABLE [dbo].[TestAddSortByXXXXSub](
[Id] [int] IDENTITY(1,1) NOT NULL,
[Id2] [int] NULL,
[Col1] [nvarchar](50) NULL,
[Col2] [nvarchar](50) NULL,
[Col3] [nvarchar](50) NULL,
[Col4] [nvarchar](50) NULL,
[Col5] [nvarchar](50) NULL,
[Col6] [nvarchar](50) NULL,
[Col7] [nvarchar](50) NULL,
[Col8] [nvarchar](50) NULL,
[Col9] [nvarchar](50) NULL,
[Col10] [nvarchar](50) NULL,
CONSTRAINT [PK_TestAddSortByXXXXSub] PRIMARY KEY CLUSTERED
(
[Id] ASC
)WITH (PAD_INDEX = OFF, STATISTICS_NORECOMPUTE = OFF, IGNORE_DUP_KEY = OFF, ALLOW_ROW_LOCKS = ON, ALLOW_PAGE_LOCKS = ON) ON [PRIMARY]
) ON [PRIMARY]
构建9999行数据
List<Entity> datas = new List<Entity>();
for (int i = 0; i < 9999; i++)
{
var item = new Entity
{
No = i + 1,
Col1 = Guid.NewGuid().ToString("N"),
Col2 = Guid.NewGuid().ToString("N"),
Col3 = Guid.NewGuid().ToString("N"),
Col4 = Guid.NewGuid().ToString("N"),
Col5 = Guid.NewGuid().ToString("N"),
Col6 = Guid.NewGuid().ToString("N"),
Col7 = Guid.NewGuid().ToString("N"),
Col8 = Guid.NewGuid().ToString("N"),
Col9 = Guid.NewGuid().ToString("N"),
Col10 = Guid.NewGuid().ToString("N"),
};
datas.Add(item);
}
Dapper:
static void AddDataByDapper(List<Entity> datas)
{
int r = 0;
Stopwatch sw = new Stopwatch();
sw.Start();
using (var conn = new SqlConnection(connString))
{
conn.Open();
string sql = "insert into TestAddSortByDapper([No], Col1, Col2, Col3, Col4, Col5, Col6, Col7, Col8, Col9, Col10) values(@No, @Col1, @Col2, @Col3, @Col4, @Col5, @Col6, @Col7, @Col8, @Col9, @Col10);";
r = conn.Execute(sql, datas);
}
sw.Stop();
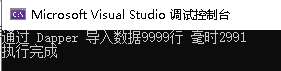
Console.WriteLine($"通过 Dapper 导入数据{r}行 毫时{sw.ElapsedMilliseconds}");
}
执行结果总结

-- 数据库实际执行数据
(@Col1 nvarchar(4000),@Col10 nvarchar(4000),...)
insert into TestAddSortByDapper([No], Col1, Col2, Col3, Col4, Col5, Col6, Col7, Col8, Col9, Col10)
values(@No, @Col1, @Col2, @Col3, @Col4, @Col5, @Col6, @Col7, @Col8, @Col9, @Col10);
从结果我们可以看到,dapper使用的是 insert into table () values () 方式循环执行9999次,代码总耗时3-4秒。
EfCore:
static void AddDataByEfCore(List<Entity> datas)
{
int r1 = 0;
Stopwatch sw = new Stopwatch();
sw.Start();
using (var db = new TestContext())
{
db.Entity.AddRange(datas);
r1 = db.SaveChanges();
}
sw.Stop();
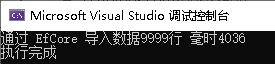
Console.WriteLine($"通过 EfCore 导入数据{r1}行 毫时{sw.ElapsedMilliseconds}");
}
[Table("TestAddSortByEfCore")]
public class Entity
{
public int Id { get; set; }
public int No { get; set; }
public string Col1 { get; set; }
public string Col2 { get; set; }
public string Col3 { get; set; }
public string Col4 { get; set; }
public string Col5 { get; set; }
public string Col6 { get; set; }
public string Col7 { get; set; }
public string Col8 { get; set; }
public string Col9 { get; set; }
public string Col10 { get; set; }
}
执行结果总结

(@p0 nvarchar(4000),@p1 nvarchar(4000),...,@p460 nvarchar(4000),@p461 int)
SET NOCOUNT ON;
DECLARE @inserted0 TABLE ([Id] int, [_Position] [int]);
MERGE [TestAddSortByEfCore] USING (
VALUES (@p0, @p1, @p2, @p3, @p4, @p5, @p6, @p7, @p8, @p9, @p10, 0),..., (@p451, @p452, @p453, @p454, @p455, @p456, @p457, @p458, @p459, @p460, @p461, 41)
) AS i ([Col1], [Col10], [Col2], [Col3], [Col4], [Col5], [Col6], [Col7], [Col8], [Col9], [No], _Position) ON 1=0
WHEN NOT MATCHED THEN
INSERT ([Col1], [Col10], [Col2], [Col3], [Col4], [Col5], [Col6], [Col7], [Col8], [Col9], [No])
VALUES (i.[Col1], i.[Col10], i.[Col2], i.[Col3], i.[Col4], i.[Col5], i.[Col6], i.[Col7], i.[Col8], i.[Col9], i.[No])
OUTPUT INSERTED.[Id], i._Position INTO @inserted0;
SELECT [t].[Id] FROM [TestAddSortByEfCore] t INNER JOIN @inserted0 i ON ([t].[Id] = [i].[Id]) ORDER BY [i].[_Position];
从结果我们可以看到,EfCore使用的是 Merge 方式增加数据,但数据库变量最多定义462个,所以每次只能增加42行数据,执行了238+3次,但最大的疑问是执行了两次,而且插入表数据顺序错了(估计是EfCore代码上使用了Parallel.For方法,有懂的朋友能否解答一下),代码总耗时4-5秒。
Freesql:
static void AddDataByEfCore(List<Entity> datas)
{
int r1 = 0;
Stopwatch sw = new Stopwatch();
sw.Start();
using (var db = new TestContext())
{
db.Entity.AddRange(datas);
r1 = db.SaveChanges();
}
sw.Stop();
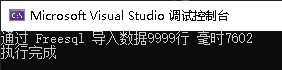
Console.WriteLine($"通过 EfCore 导入数据{r1}行 毫时{sw.ElapsedMilliseconds}");
}
[FreeSql.DataAnnotations.Table(Name = "TestAddSortByFreesql", DisableSyncStructure = true)]
public class Entity
{
[FreeSql.DataAnnotations.Column(Name = "id", IsPrimary = true, IsIdentity = true)]
public int Id { get; set; }
public int No { get; set; }
public string Col1 { get; set; }
public string Col2 { get; set; }
public string Col3 { get; set; }
public string Col4 { get; set; }
public string Col5 { get; set; }
public string Col6 { get; set; }
public string Col7 { get; set; }
public string Col8 { get; set; }
public string Col9 { get; set; }
public string Col10 { get; set; }
}
执行结果总结

(@No_0 int,@Col1_0 nvarchar(32),...,@Col10_173 nvarchar(32))
INSERT INTO [TestAddSortByFreesql]([No], [Col1], [Col2], [Col3], [Col4], [Col5], [Col6], [Col7], [Col8], [Col9], [Col10])
VALUES(@No_0, @Col1_0, @Col2_0, @Col3_0, @Col4_0, @Col5_0, @Col6_0, @Col7_0, @Col8_0, @Col9_0, @Col10_0), ..., (@No_173, @Col1_173, @Col2_173, @Col3_173, @Col4_173, @Col5_173, @Col6_173, @Col7_173, @Col8_173, @Col9_173, @Col10_173)
从结果我们可以看到,freesql使用的是 insert into table () values (), () 方式循环执行,每次最多增加173行数据,代码总耗时7-8秒。
从目前结果来看,单表增加大量数据,时间上 Dapper > EfCore > Freesql。
ADO.NET SqlBulkCopy 复制(最优方案)
static void AddDataByBulkCopy(List<Entity> datas)
{
Stopwatch sw = new Stopwatch();
var dt = new DataTable();
dt.Columns.Add("No", typeof(int));
dt.Columns.Add("Col1", typeof(string));
dt.Columns.Add("Col2", typeof(string));
dt.Columns.Add("Col3", typeof(string));
dt.Columns.Add("Col4", typeof(string));
dt.Columns.Add("Col5", typeof(string));
dt.Columns.Add("Col6", typeof(string));
dt.Columns.Add("Col7", typeof(string));
dt.Columns.Add("Col8", typeof(string));
dt.Columns.Add("Col9", typeof(string));
dt.Columns.Add("Col10", typeof(string));
foreach (var item in datas)
{
var dr = dt.NewRow();
dr["No"] = item.No;
dr["Col1"] = item.Col1;
dr["Col2"] = item.Col2;
dr["Col3"] = item.Col3;
dr["Col4"] = item.Col4;
dr["Col5"] = item.Col5;
dr["Col6"] = item.Col6;
dr["Col7"] = item.Col7;
dr["Col8"] = item.Col8;
dr["Col9"] = item.Col9;
dr["Col10"] = item.Col10;
dt.Rows.Add(dr);
}
sw.Start();
using (SqlConnection cn = new SqlConnection(connString))
{
cn.Open();
using (SqlBulkCopy sqlBulkCopy = new SqlBulkCopy(cn))
{
sqlBulkCopy.BatchSize = dt.Rows.Count;
sqlBulkCopy.BulkCopyTimeout = 1800;
sqlBulkCopy.DestinationTableName = "TestAddSortByBulkCopy"; sqlBulkCopy.ColumnMappings.Add("No", "No");
sqlBulkCopy.ColumnMappings.Add("Col1", "Col1");
sqlBulkCopy.ColumnMappings.Add("Col2", "Col2");
sqlBulkCopy.ColumnMappings.Add("Col3", "Col3");
sqlBulkCopy.ColumnMappings.Add("Col4", "Col4");
sqlBulkCopy.ColumnMappings.Add("Col5", "Col5");
sqlBulkCopy.ColumnMappings.Add("Col6", "Col6");
sqlBulkCopy.ColumnMappings.Add("Col7", "Col7");
sqlBulkCopy.ColumnMappings.Add("Col8", "Col8");
sqlBulkCopy.ColumnMappings.Add("Col9", "Col9");
sqlBulkCopy.ColumnMappings.Add("Col10", "Col10");
sqlBulkCopy.WriteToServer(dt);
}
}
sw.Stop();
Console.WriteLine($"通过 BulkCopy 毫时{sw.ElapsedMilliseconds}");
}
执行结果总结
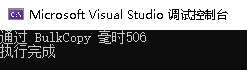
并没有在 sys.dm_exec_query_stats 上产生结果,但他的性能是最佳的。
下一篇,来看看级联操作上谁能更胜一筹。
Dapper, Ef core, Freesql 插入大量数据性能比较(一)的更多相关文章
- Dapper, Ef core, Freesql 插入大量数据性能比较(二)
在上一篇文章中,我们比较出单表插入9999行数据,Dapper > EfCore > Freesql.在本文中,我们来看看级联插入 构建9999行数据 List<Entity> ...
- c# 国内外ORM 框架 dapper efcore sqlsugar freesql hisql sqlserver数据常规插入测试性能对比
c# 国内外ORM 框架 dapper efcore sqlsugar freesql hisql sqlserver数据常规插入测试性能对比对比 在6.22 号发布了 c# sqlsugar,his ...
- EF Core利用Transaction对数据进行回滚保护
What? 首先,说一下什么是EF Core中的Transaction Transaction允许以原子方式处理多个数据库操作,如果事务已提交,则所有操作都应用于数据库,如果事务回滚,则没有任何操作应 ...
- EF Core 使用编译查询提高性能
今天,我将向您展示这些EF Core中一个很酷的功能,通过使用显式编译的查询,提高查询性能. 不过在介绍具体内容之前,需要说明一点,EF Core已经对表达式的编译使用了缓存:当您的代码需要重用以前执 ...
- Sqlite3插入大量数据性能优化
近期做的一个项目数据量很大.文本数据有30多M.这样就遇到一个问题.插入数据库时很慢. 这里记录下,优化方法很easy. 原文地址:http://blog.csdn.net/qqmcy/article ...
- 深入理解 EF Core:EF Core 读取数据时发生了什么?
阅读本文大概需要 11 分钟. 原文:https://bit.ly/2UMiDLb 作者:Jon P Smith 翻译:王亮 声明:我翻译技术文章不是逐句翻译的,而是根据我自己的理解来表述的.其中可能 ...
- 深入理解 EF Core:使用查询过滤器实现数据软删除
原文:https://bit.ly/2Cy3J5f 作者:Jon P Smith 翻译:王亮 声明:我翻译技术文章不是逐句翻译的,而是根据我自己的理解来表述的.其中可能会去除一些本人实在不知道如何组织 ...
- 【.NET 6】使用EF Core 访问Oracle+Mysql+PostgreSQL并进行简单增改操作与性能比较
前言 唠嗑一下.都在说去O或者开源,但是对于数据库选型来说,很多人却存在着误区.例如,去O,狭义上讲,是去Oracle数据库.但是从广义上来说,是去Oracle公司产品或者具有漂亮国垄断地位和需要商 ...
- ef core数据迁移的一点小感悟
ef core在针对mysql数据迁移的时候,有些时候没法迁移...有两种情况没法迁移,一种是因为efcore的bug问题导致没法迁移,这个在github上有个问题集,另外一种是对数据表进行较大幅度的 ...
随机推荐
- js in depth: Object & Function & prototype & __proto__ & constructor & classes inherit
js in depth: Object & Function & prototype & proto & constructor & classes inher ...
- uniapp设置不同的主题(Theme)
App.vue: <style lang="stylus"> @css { html { --primary: blue; --bg-image: url(https: ...
- c++ 动态解析PE导出表
测试环境是x86 main #include <iostream> #include <Windows.h> #include <TlHelp32.h> #incl ...
- 大胆预计SPC算力空投收益,月收益22.8%
此前,NGK官方公告表示,NGK算力持有者获得SPC的数量是根据200万枚SPC除以全网算力总量决定的. 举个例子,假设全网算力总量为500万,那么每个算力持有者如果持有一个算力,则可获得200万÷5 ...
- [转]ROS学习笔记十一:ROS中数据的记录与重放
本节主要介绍如何记录一个正在运行的ROS系统中的数据,然后在一个运行的系统中根据记录文件重新产生和记录时类似的运动情况.本例子还是以小海龟例程为例. 记录数据(创建一个bag文件) 首先运行小海龟例程 ...
- HBase ——Shell操作
HBase --Shell操作 Q:你觉得HBase是什么? A:一种结构化的分布式数据存储系统,它基于列来存储数据. 基于HBase,可以实现以廉价PC机器集群存储海量数据的分布式数据库的解决方案. ...
- TCP/IP协议学习-1.概述
目录 TCP/IP协议概述 分层 延伸知识 FTP例子 为什么需要网络层和传输层 TCP/IP的分层 封装 分用 总结 本文主要摘抄自书籍<TCP/IP详解卷一:协议>与TCP协议相关内容 ...
- 从客流统计到营销赋能,Re-ID加速实体商业数字化转型 | 爱分析洞见
2020年中国实体商业受到突发疫情的重大影响.以危机为契机,实体商业加速数字化转型,利用创新应用服务自身业务.在此阶段,基于Re-ID(Person Re-identification,即行人再识别) ...
- Linux速通08 网络原理及基础设置、软件包管理
使用 ifconfig命令来维护网络 # ifconfig 命令:显示所有正在启动的网卡的详细信息或设定系统中网卡的 IP地址 # 应用 ifconfig命令设定网卡的 IP地址: * 例:修改 et ...
- 技术基础 | 在Apache Cassandra中改变VNodes数量的影响
Apache Cassandra中num_tokens的默认值在4.0版本中将会有变化!这看起来好像只是在CHANGES.txt文件中做了个小小的改动,但实际上这个改动将会对集群的日常运维有着深远的影 ...