学习小计: Kaggle Learn Embeddings
Embedding表示map f: X(高维) -> Y(低维),减小数据维度,方便计算+提高准确率。
参看Kaggle Learn:https://www.kaggle.com/learn/embeddings
官方DNN示例:
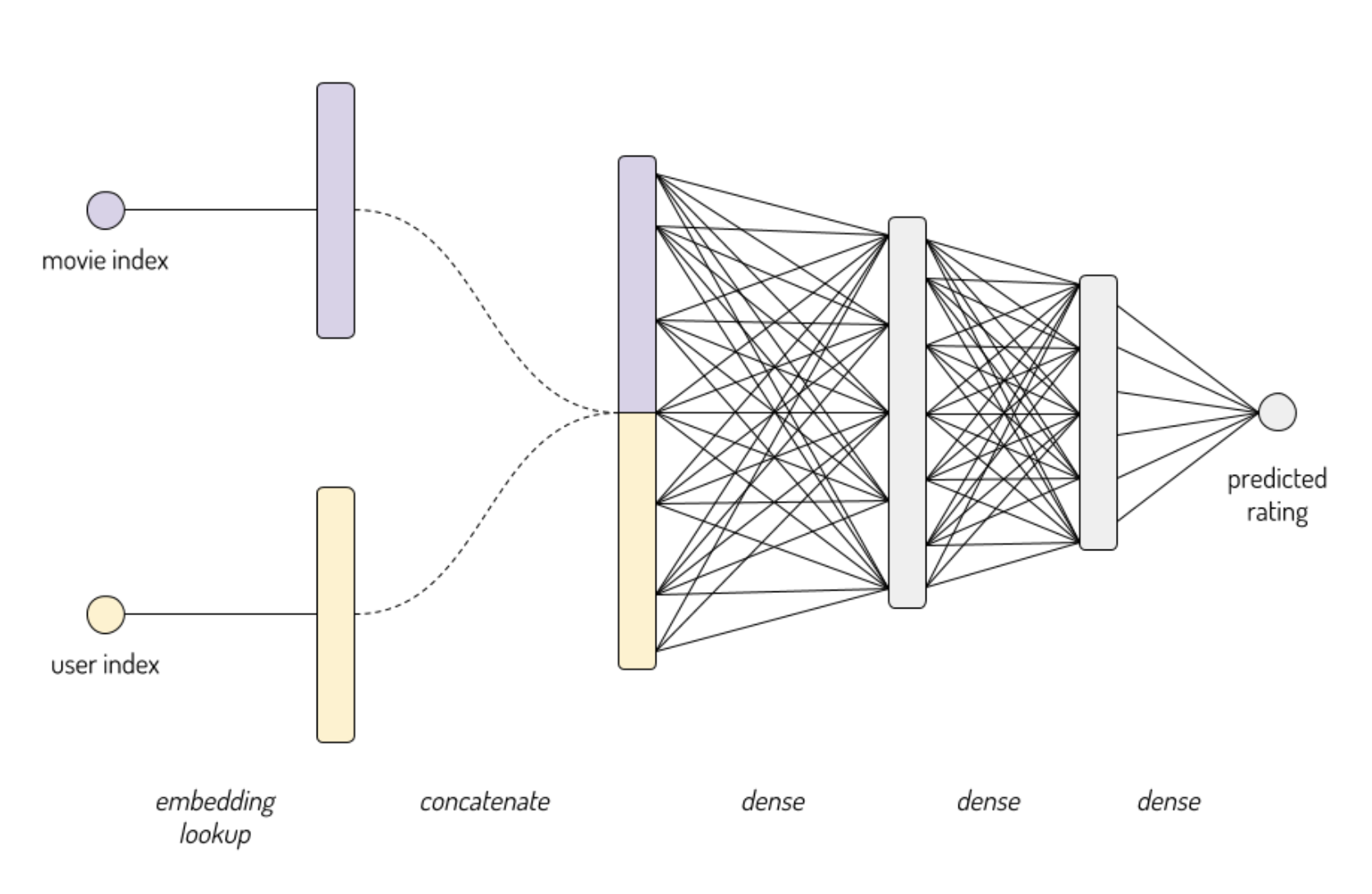
user_id_input = keras.Input(shape=(1,), name='user_id')
movie_id_input = keras.Input(shape=(1,), name='movie_id')
user_embedded = keras.layers.Embedding(df.userId.max()+1, user_embedding_size,
input_length=1, name='user_embedding')(user_id_input)
movie_embedded = keras.layers.Embedding(df.movieId.max()+1, movie_embedding_size,
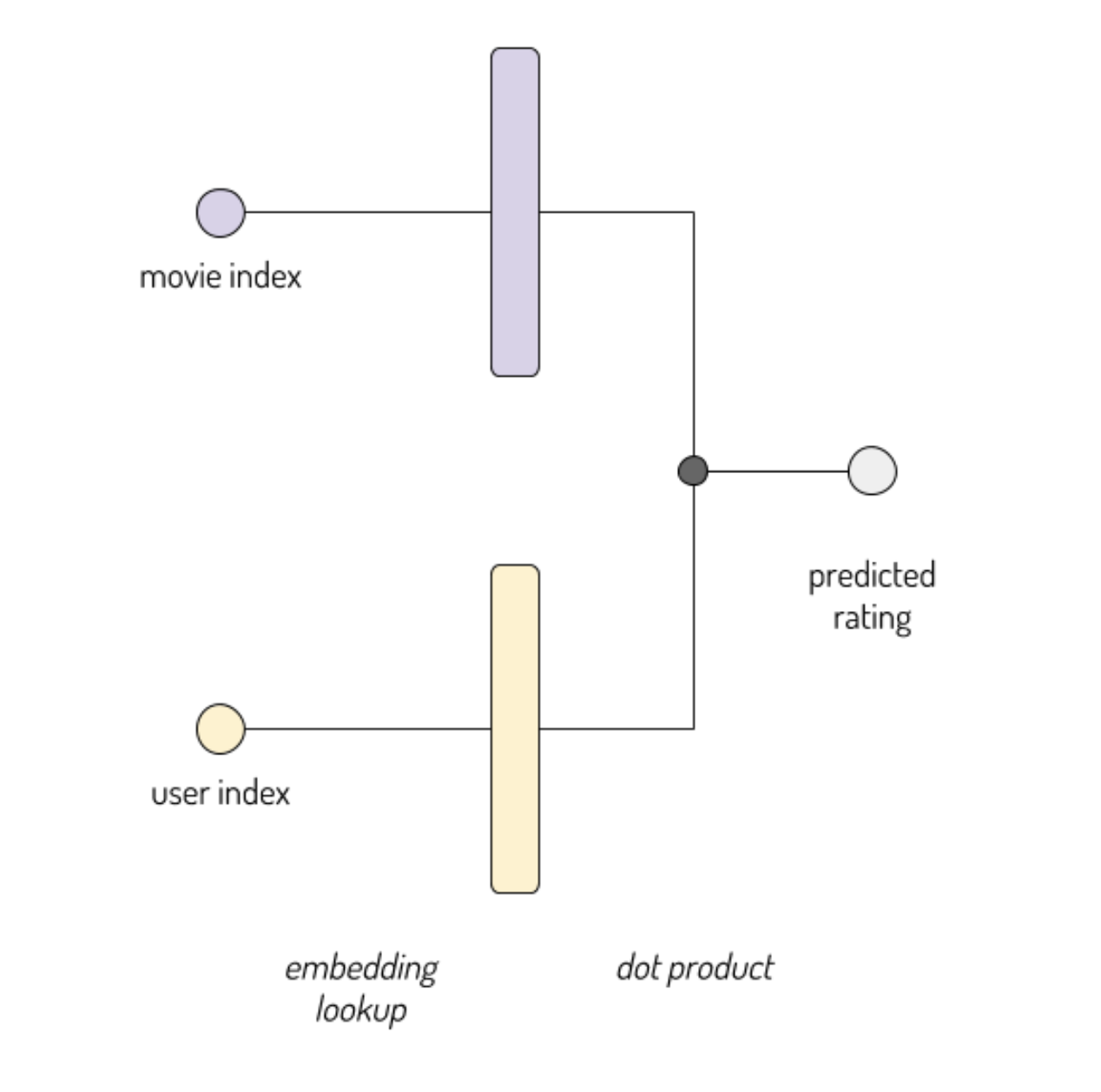
movie_embedding_size = user_embedding_size = 8 # Each instance consists of two inputs: a single user id, and a single movie id
user_id_input = keras.Input(shape=(1,), name='user_id')
movie_id_input = keras.Input(shape=(1,), name='movie_id')
user_embedded = keras.layers.Embedding(df.userId.max()+1, user_embedding_size,
input_length=1, name='user_embedding')(user_id_input)
movie_embedded = keras.layers.Embedding(df.movieId.max()+1, movie_embedding_size,
input_length=1, name='movie_embedding')(movie_id_input) dotted = keras.layers.Dot(2)([user_embedded, movie_embedded])
out = keras.layers.Flatten()(dotted)
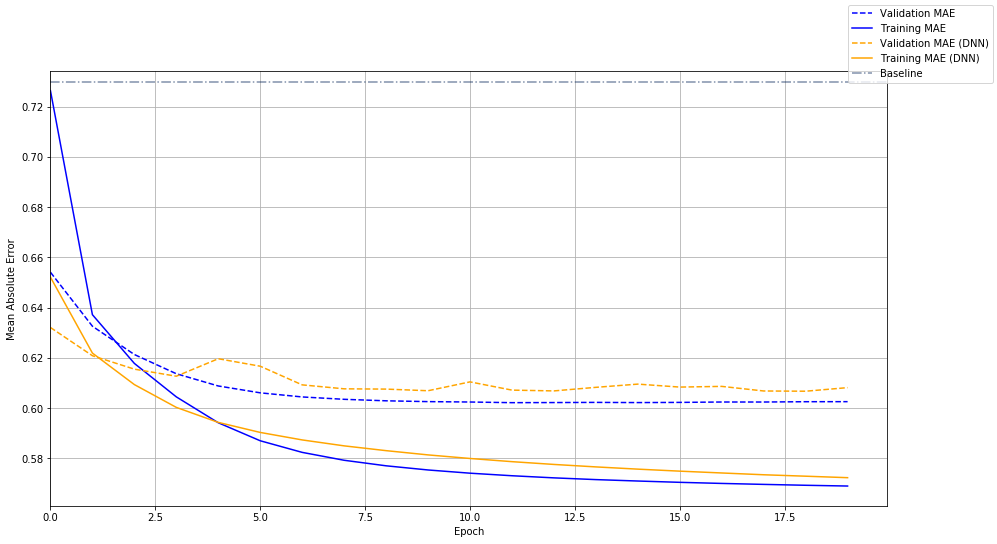
两种类型对比如下,简单模型(蓝色)的表现也相当好,两个模型都有明显的过拟合。
虽源于词向量模型,但是对于电影评价,电影向量模型仍然很实用。
可用于计算电影(或单词)的相似度,支持语义计算(+-),例如可用于求解如下问题:
‘Cars 2’:‘Brave’== '?':‘Pocahontas’,解释,‘Cars 2’相对于‘Brave’就如'?'相对于‘Pocahontas’,求电影'?'最佳匹配。
方程组:
Cars 2 = Brave + X
'?' = Pocahontas + X
解方程得到:
'?' = Pocahontas + (Cars 2 - Brave)
Scripts关键语句:
kv.most_similar(
['Pocahontas', 'Cars 2'],
negative = ['Brave']
)
Visualizing Embeddings With t-SNE,参考Kaggle Learn:https://www.kaggle.com/colinmorris/visualizing-embeddings-with-t-sne
t-SNE是一种降维算法,一种数据探索和可视化技术,常用于高维数据可视化(降维到2D)
全称:随机邻近嵌入stochastic neighborhood embedding
其基本原理,参考:https://blog.csdn.net/scythe666/article/details/79203239, https://www.analyticsvidhya.com/blog/2017/01/t-sne-implementation-r-python/
学习小计: Kaggle Learn Embeddings的更多相关文章
- 学习小计: Kaggle Learn Time Series Modeling
ARIMA模型,参数含义参考:https://www.cnblogs.com/bradleon/p/6827109.html from statsmodels.tsa.arima_model impo ...
- Miller-Rabin素数测试学习小计
1.Miller-Rabin是干啥的?它是用来检测一个数字(一般是很大的数字)是不是素数: 2.Miller-Rabin算法基于的两个定理: (1)费尔马小定理:如果p是一个素数,且0<a< ...
- js正则学习小计
//元字符 {} () ^ $ . ? + //预定义字符 \d \D \w \W \s \S //量词 {n,m} {n} {n,} + ? * //贪婪和惰性 //反向引用 //分组 //候选 / ...
- ES6学习小计
1.增加了for of语法,对应C#里的foreach,注意ES5中的 for in只会传递0,1,2.....序号,并且是字符for-of循环语句通过方法调用来遍历各种集合.数组.Maps对象.Se ...
- kvm学习小计
1.Kvm安装 安装方法两种方式,一种是直接下载源码编译安装,一种是直接使用yum install kvm/apt-get install kvm,这部分就不详细说明了,我使用的是第二种方法,待后 续 ...
- Docker学习小计
1.自动下载并且创建容器 Now verify that the installation has worked by downloading the ubuntu image and launchi ...
- Jquery学习小计
实时监听输入框值变化 首先创建Jquery.fn扩展 jQuery.fn.extend({ inputChange: function(callback){ if($.support.leadingW ...
- Python学习小计
1.初学Python最好选择2.7版本,因为大部分Python书籍的示例代码是基于这个版本的 2.Python安装可以参考百度经验完成 如果在电脑上同时安装2个版本,则CMD启动时只需要: py -2 ...
- R学习小计
安装R扩展包:install.packages("FKF")http://www.douban.com/note/243004605/1.输入数据 l读入有分隔符数据:A<- ...
随机推荐
- 【洛谷P1281 书的复制】二分+动态规划
分析 两个做法,一个DP,一个是二分. 二分:也就是二分枚举每个人分到的东西. DP:区间DP F[I][J]表示前i本书分给j个人用的最短时间 由于每一次j的状态由比j小的状态得出,所以要先枚举j, ...
- 【排序+模拟】魔法照片 luogu-1583
题目描述 一共有n(n≤20000)个人(以1--n编号)向佳佳要照片,而佳佳只能把照片给其中的k个人.佳佳按照与他们的关系好坏的程度给每个人赋予了一个初始权值W[i].然后将初始权值从大到小进行排序 ...
- nodejs 文本逐行读写功能的实现
利用nodejs实现:逐行读写(从一个文件逐行复制到另外一个文件):逐行读取.处理和写入(读取一行,处理后,写入另一个文件) 1.所需要的模块: fs,os,readline 2.具体实现: a. 功 ...
- mac上安装brew----笔记
一.mac 终端下,执行以下命令,即可安装brew: 介绍brew:是Mac下的一款包管理工具brew [brew install 软件],类似与centos里面的 yum[yum install 软 ...
- phpmyadmin error:#2002 - 服务器没有响应 (或者本地 MySQL 服务器的套接字没有正确配置)
1. 将 "phpMyAdmin/libraries"文件夹下的config.default.php文件中的$cfg['Servers'][$i]['host'] = 'local ...
- Couchdb 垂直权限绕过漏洞(CVE-2017-12635)
影响版本:小于 1.7.0 以及 小于 2.1.1 首先,发送如下数据包: 修改数据包 { "type": "user", "name": ...
- centos linux下配置固定ip,方便xshell连接
如何给centos linux设置固定ip地址,设置Linux系统的固定IP地址 首先wmware打开虚拟机 打开xshell6连接虚拟机(比较方便,这里默认设置过Linux的ip,只是不固定,每次打 ...
- 如何读懂Framework源码?如何从应用深入到Framework?
如何读懂Framework源码? 首先,我也是一个应用层开发者,我想大部分有"如何读懂Framework源码?"这个疑问的,应该大都是应用层开发. 那对于我们来讲,读源码最大的问题 ...
- Redisson实战-BloomFilter
1. 简介 布隆过滤器是防止缓存穿透的方案之一.布隆过滤器主要是解决大规模数据下不需要精确过滤的业务场景,如检查垃圾邮件地址,爬虫URL地址去重, 解决缓存穿透问题等. 布隆过滤器:在一个存在一定数量 ...
- Install Redmine Server with Bitnami Installer
Download bitnami installer: bitnami-redmine-2.4.1-1-linux-installer.run $ chmod 755 bitnami...instal ...