干货!4大实验项目,深度解析Tag在可观测性领域的最佳实践!
Opentelemetry协议,是CNCF(Cloud Native Computing Foundation-云原生计算基金会)定义的最新一代的可观测规范(目前还在孵化中),该规范定义了可观测性的三大支柱:metrics、trace、log(指标、链路、日志)。但是如果仅仅是将这三支柱的数据收集起来,而不进行关联,那所谓的可观测性与传统的监控工具(APM、日志、zabbix等)又有何区别,难道说仅仅是一套监控工具的集合吗?所以这里引申出一个很重要的观念:TAG(标签),例如前后端打通的triceID,在某种程度上也可以看做是一个tag,将指标链路日志进行初步关联的host也可以看做是一个tag,其他的例如项目、环境、版本号等等都是一个个的tag!总之,通过TAG可以实现数据的关联,以及更多的自定义的可观测性玩法,就显得尤为重要。DF目前架构中所有的可观测项均支持tag的设置,理论上tag数量无上限。
举例:生活中常见的现象就是找工作或者hr招聘,招聘往往会有比较具体的要求,例如xx岗位,需要具备编程技能、计算机常识、本科学位、n年工作经验等等,这一个个要求就好比标签,只有满足标签的人才有可能得到这个岗位,那在IT系统里,就可以是,xx服务器上,跑了xx应用,xx数据库,xxnginx,环境是xx环境,负责人是xxx,当出现问题时,如果标签足够多,很快速的就可以知道哪台服务器有问题,具体影响了哪些业务,哪些应用组件,谁在负责相关的组件,这样就可以快速找到专业对口人员进行修复及弥补,从而提升解决问题的效率。
此文将利用DF从四个示例对tag的可拓展性及可玩性进行试验:
实验一:给服务器进行分组
背景:企业内部往往存在多个项目组或者事业部,不同项目组或事业部在做自己的业务开发时,往往会用专属于自己的基础设施,如果从基础设施到应用都接入了DF进行可观测性,那除了通过分工作空间之外,还有什么方式可以进行项目资源的区分吗?当然有,df设计之初就想到了这种情况,默认的datakit的主配置文件中,有一个global_tag的标签,该标签就是从基础设施层面进行标签的设定,该基础设施上的其他组件,例如应用、数据库都会默认带上这个标签。
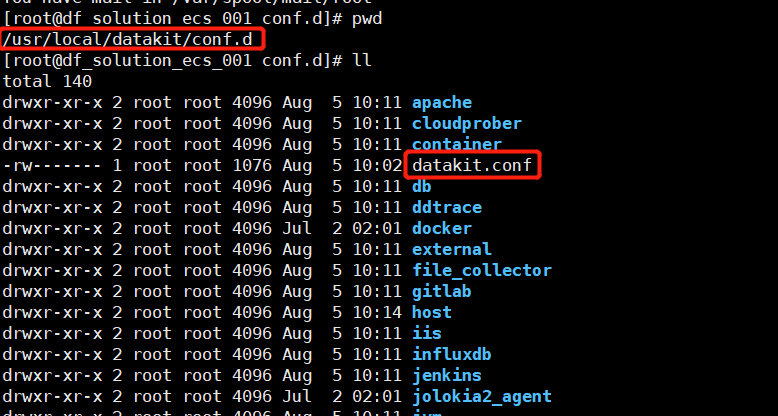
1、修改datakit-inputs,配置global_tag
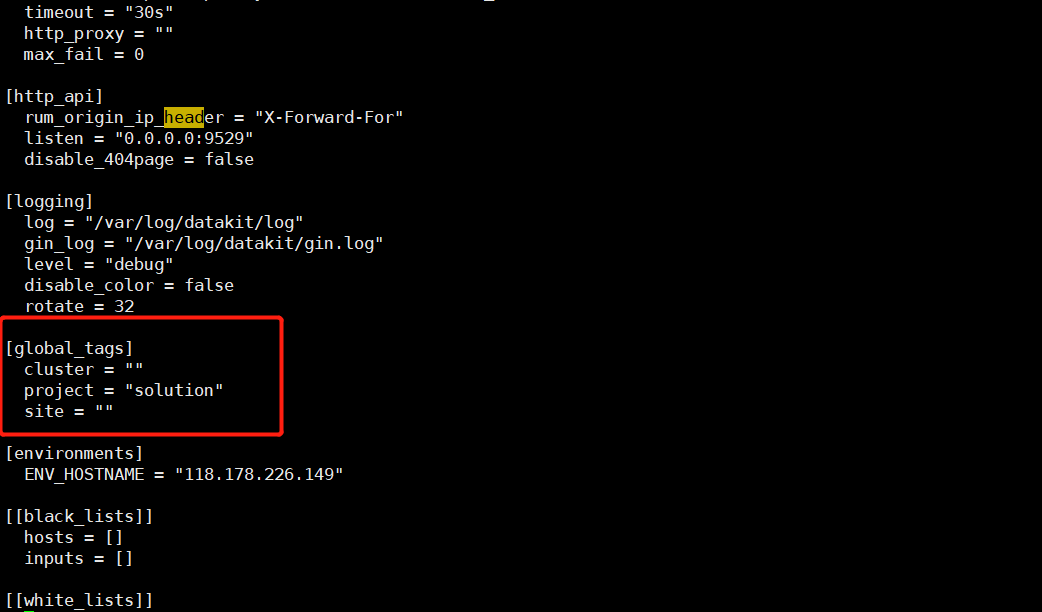
$ vim /usr/local/datakit/conf.d/datakit.conf # 在global_tags 中添加标签,除默认的三个外,还可添加其他标签 $ [global_tags]
$ cluster = ""
$ project = "solution"
$ site = ""
同理,可将所有相关主机的datakit都加上这个标签。
2、DF-查看服务器
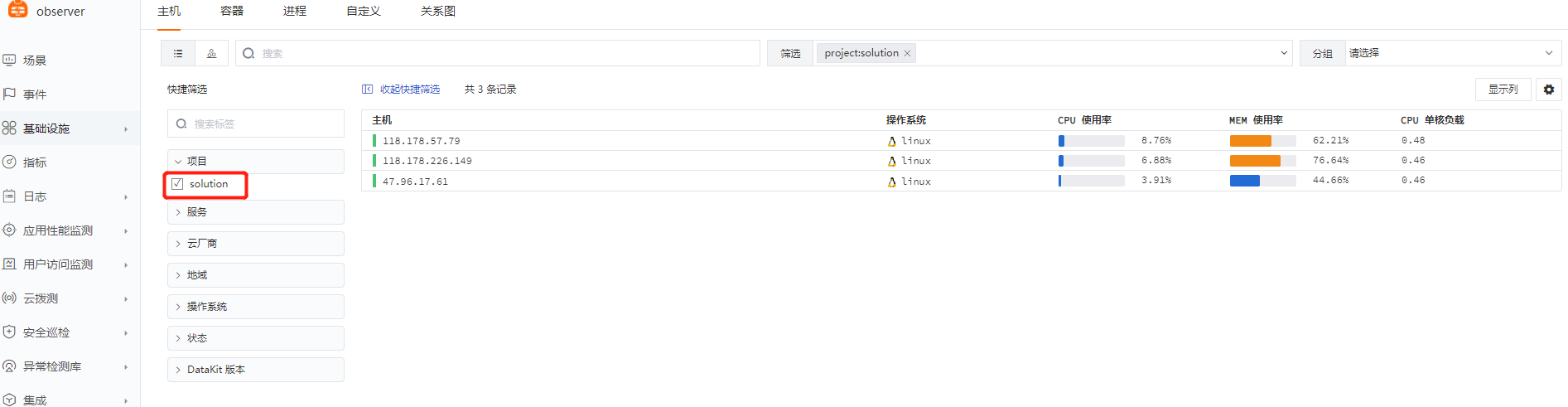
实验二:修改datakit识别的hostname
背景:datakit会默认采集主机层面的hostname,然后将识别到的hostname作为全局tag,将所有的指标、链路、日志、对象等数据进行关联,但是,在很多企业内部实际环境中,hostname是无规则的字符串,没有实际意义,而又因为hostname可能被用于连接应用或管理数据库等其他作用,企业内部无法评估更改hostname(将hostname变更为可识别的字符串)会带来怎样的隐患,所以不愿意变更hostname,为了避免风险,datakit内置的ENV_HOSTNAME就可以应对这种情况。
此方法生效后,新的hostname所在的主机数据会重新进行上传,原有hostname的主机数据将不再更新。
建议:如有更改hostname需要,最好在初次安装datakit时进行修改。
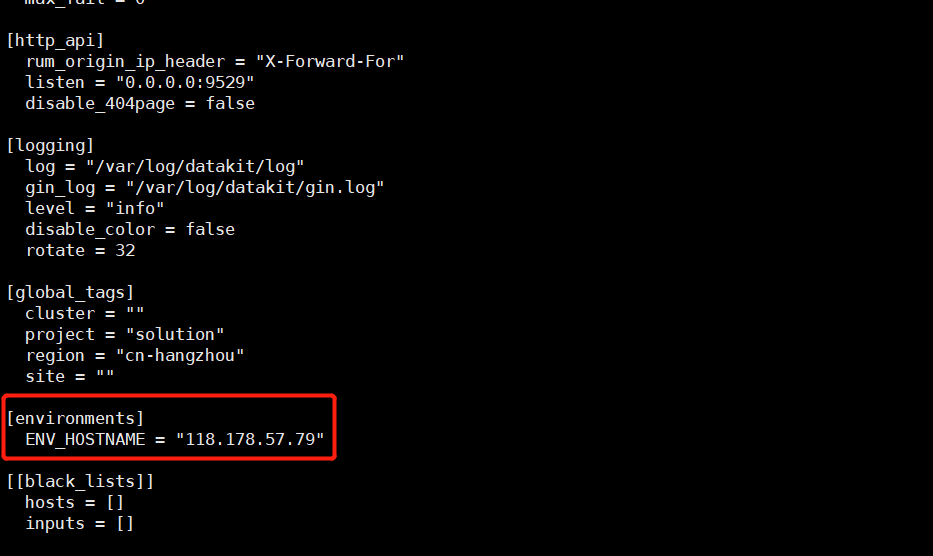
1、修改datakit-inputs,配置[environments]
$ vim /usr/local/datakit/conf.d/datakit.conf # 在[environments]中修改ENV_HOSTNAME,改成方便识别的hostname [environments]
ENV_HOSTNAME = "118.178.57.79"

2、DF-对比更改前后的数据
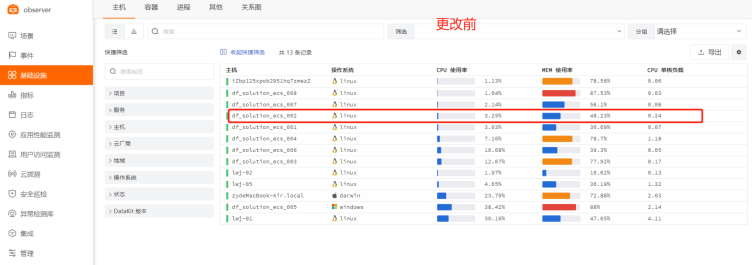
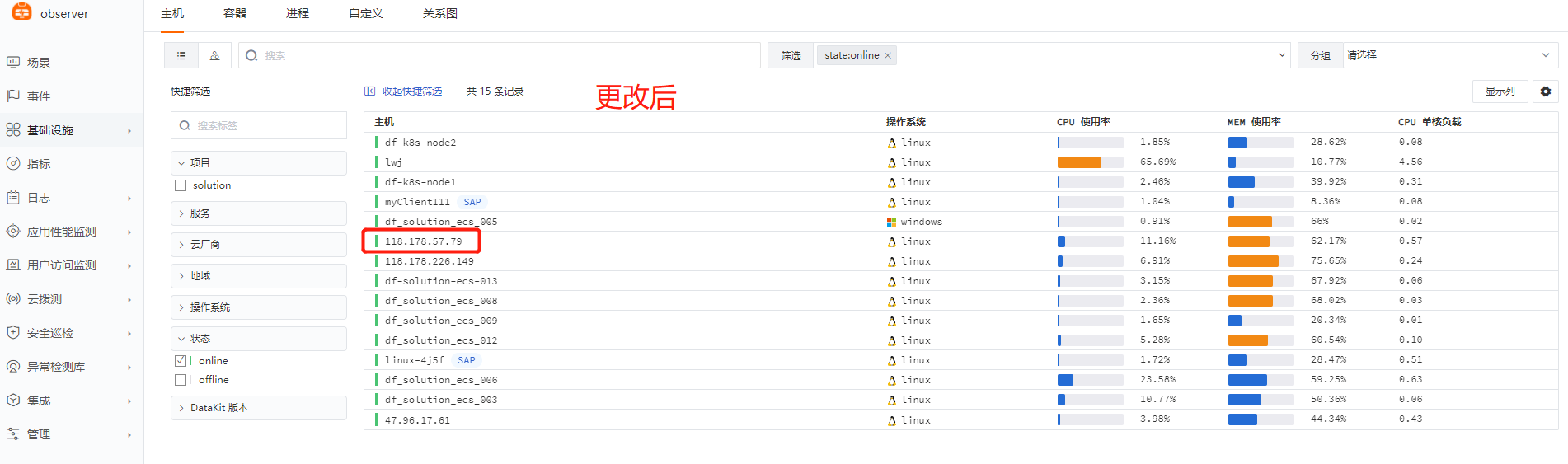
实验三:Nginx日志统计分服务进行数据展示
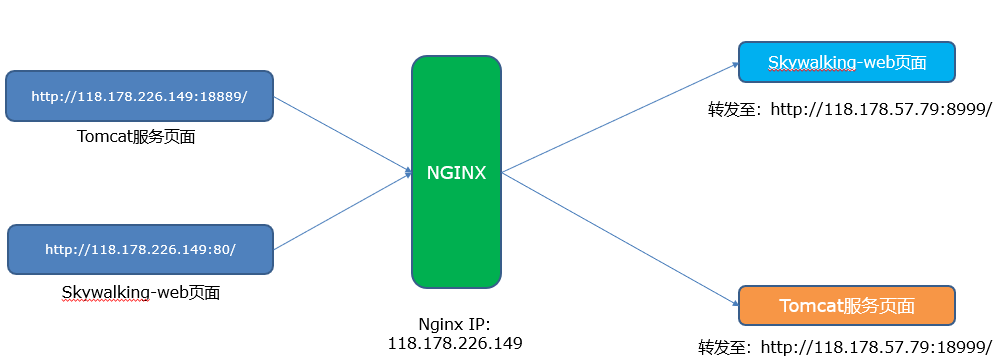
背景:企业内部的nginx,一般担负着域名转发或者服务转发的作用,往往nginx所对应的域名会将前端请求转发至后端多个不同的子域名或者多个不同端口的服务,也有可能nginx直接会承载着多个域名服务,针对这种情况,统一化的nginx监控根本无法满足,那df是如何解决这种问题的呢?
场景:nginx对外暴露18889跟80端口,分别转发至内网服务器118.178.57.79的8999及18999端口。
需求:分别统计nginx18889及80两个端口对应服务的数据,例如PV、UV、请求错误数量等数据。
前置条件:nginx的80及18889的访问日志已分别配置到不同的目录(或者配置成不同的日志文件名称)
|
80端口日志目录 |
/var/log/nginx/80/ |
|
18889端口日志目录 |
/var/log/nginx/18999/ |
1、配置nginx自身指标监控
详细配置参考[nginx可观测性最佳实践] https://www.yuque.com/dataflux/bp/nginx
开启nginx.conf自身性能指标统计模块
查看nginx的http_stub_status_module模块是否已打开
(此示例已打开)

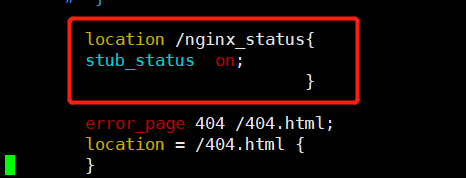
在Nginx.conf中增添nginx_status的location转发
$ cd /etc/nginx
//nginx路径根据实际情况而定
$ vim nginx.conf $ server{
listen 80;
server_name localhost;
//端口可自定义 location /nginx_status {
stub_status on;
allow 127.0.0.1;
deny all;
} }

检查该模块是否已正常开通:
linux环境:curl http://127.0.0.1/nginx_status
会出现如下数据:
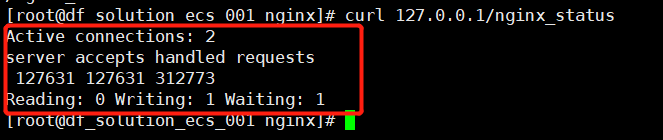
如已开通,可执行 nginx -t查看nginx状态。

接下来执行 nginx -s reload重新加载nginx
Datakit中开启nginx.inputs:
$ cd /usr/local/datakit/conf.d/nginx/
$ cp nginx.conf.sample nginx.conf
$ vim nginx.conf
#修改如下内容
[[inputs.nginx]]
url = http://localhost/nginx_status
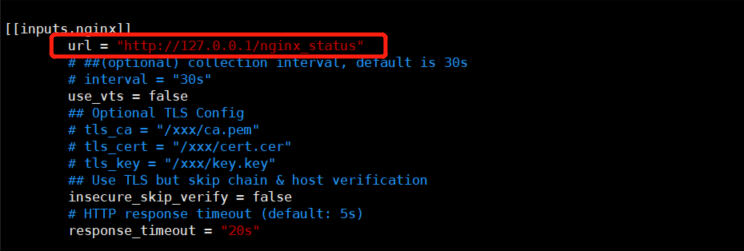
保存nginx.conf文件后重启datakit
$ service datakit restart
2、分别配置配置80及18889服务对应的日志监控
$ cd /usr/local/datakit/conf.d/log/
$ cp logging.conf.sample nginx80.conf $ vim nginx80.conf ## 修改log路径为正确的应用日志的路径
## source 、service 、pipeline 为必填字段,可以直接用应用名称,用以区分不同的日志名称
## 添加tag dominname ## 修改如下内容:
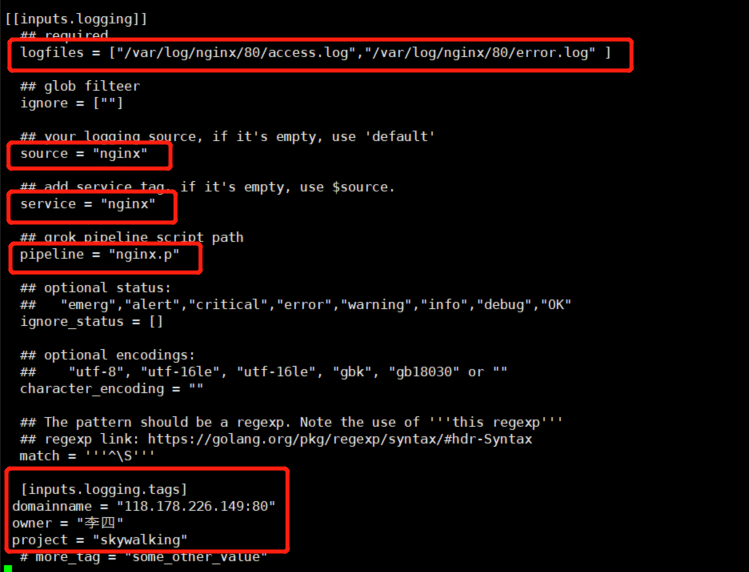
[[inputs.logging]] logfiles = ["/var/log/nginx/80/access.log","/var/log/nginx/80/error.log" ] source = "nginx" service = "nginx" pipeline = "nginx.p" [inputs.logging.tags] domainname = "118.178.226.149:80"
$ cd /usr/local/datakit/conf.d/log/
$ cp logging.conf.sample nginx18889.conf
$ vim nginx18889.conf ## 修改log路径为正确的应用日志的路径
## source 、service 、pipeline 为必填字段,可以直接用应用名称,用以区分不同的日志名称
## 添加tag dominname ## 修改如下内容:
[[inputs.logging]] logfiles = ["/var/log/nginx/18889/access.log","/var/log/nginx/18889/error.log" ] source = "nginx" service = "nginx" pipeline = "nginx.p" [inputs.logging.tags] domainname = "118.178.226.149:18889"
3、配置自定义视图(通过tag区分域名)
创建步骤参考[创建场景及视图] https://www.yuque.com/dataflux/bp/sample1#IVN7h
步骤:登录DF—>场景—>新建场景—>新建空白场景—>系统视图(创建NGINX)
重点:在系统模板上修改nginx视图相关配置
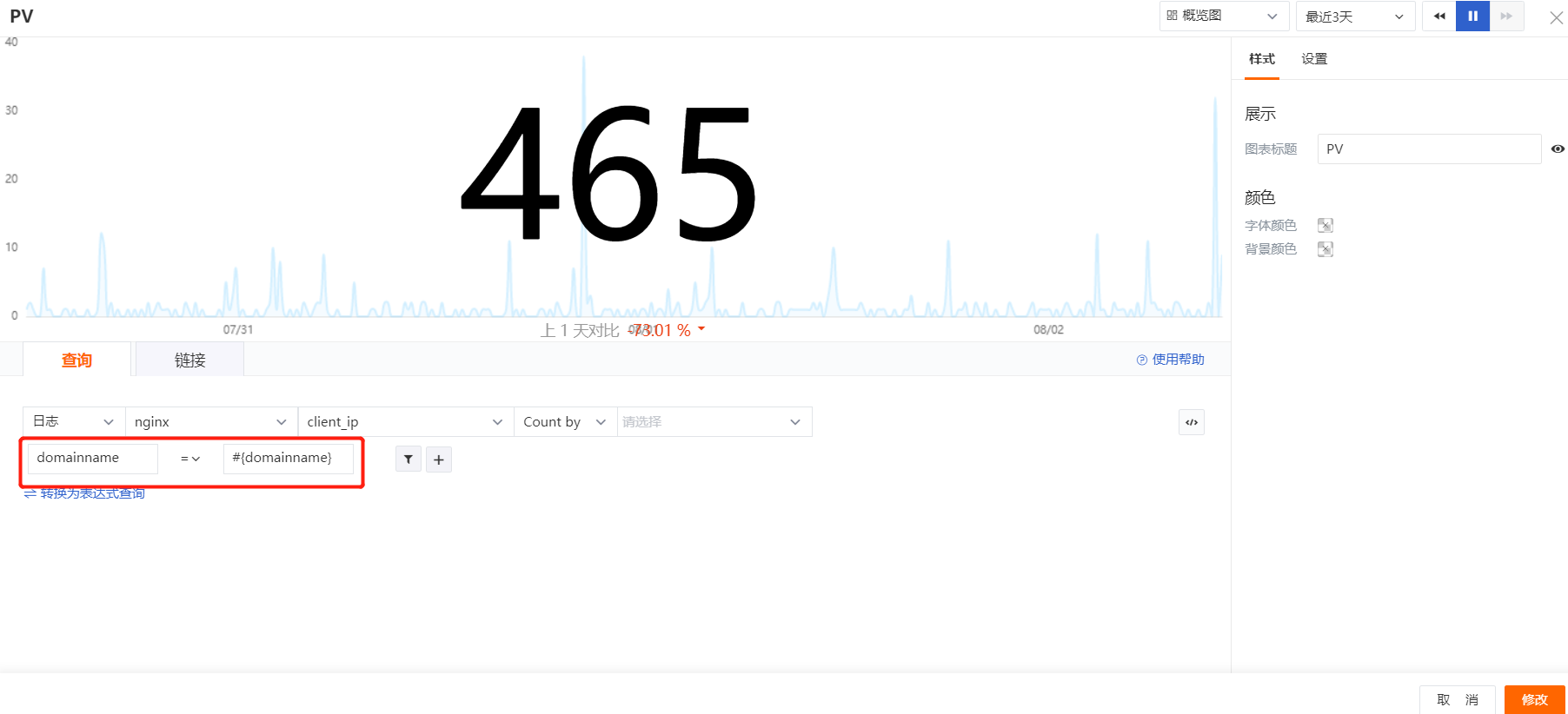
1、进入视图编辑状态,点击修改视图变量,添加视图变量
L::nginx:(distinct(`domainname`)){host='#{host}'}
注释:继承nginx指标中的host,在L(日志)中查询nginx日志中不同的domainname

2、修改具体视图的参数

4、df-分服务数据展示
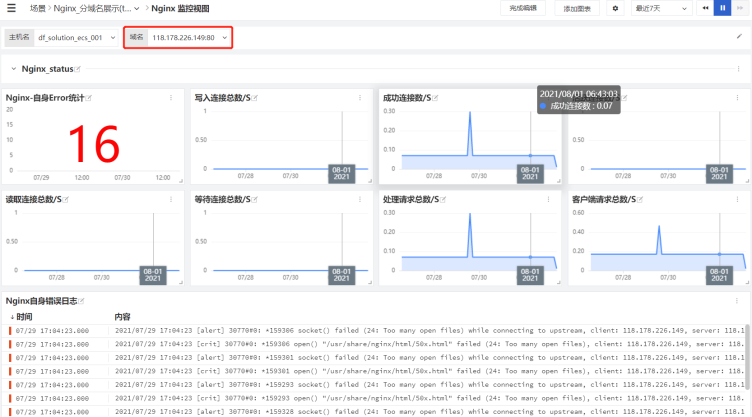
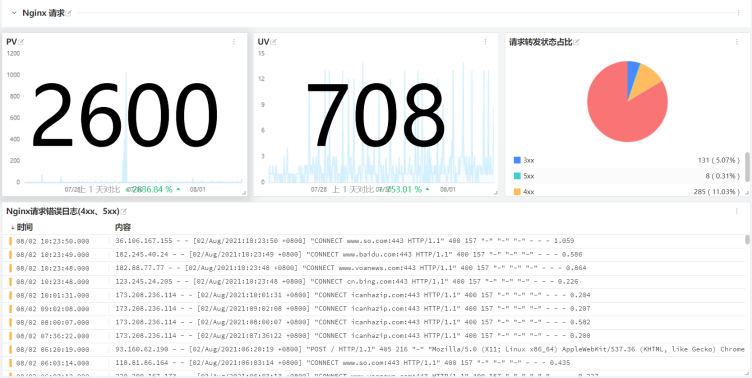
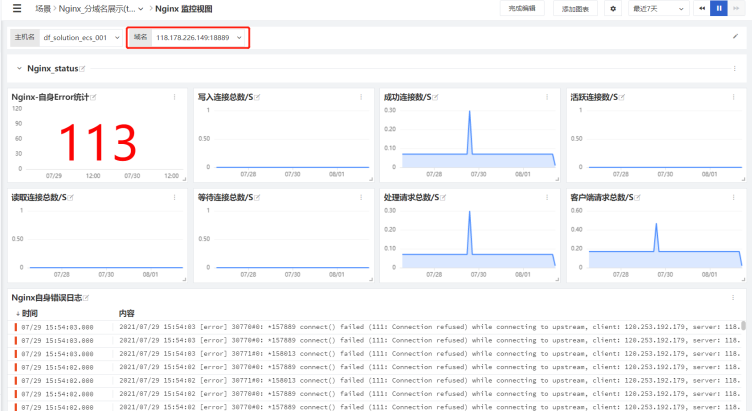
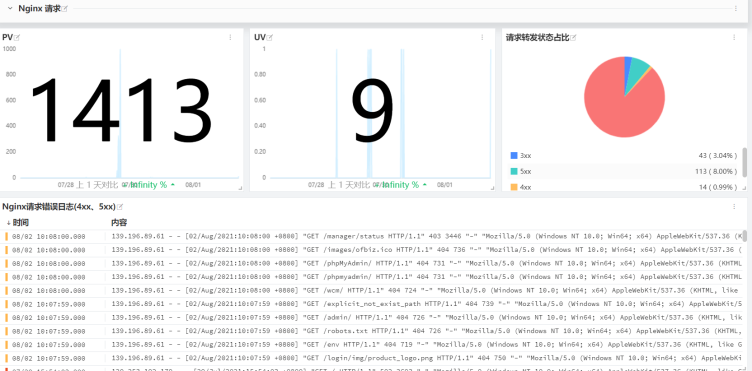
同理:可以通过打不同的tag,用以区分不同的project、不同的负责人、不同的业务模块、不同的环境等等等等,tag具体的能力取决于你的想象空间。
实验四:通过tag确认服务具体owner,进行告警通知
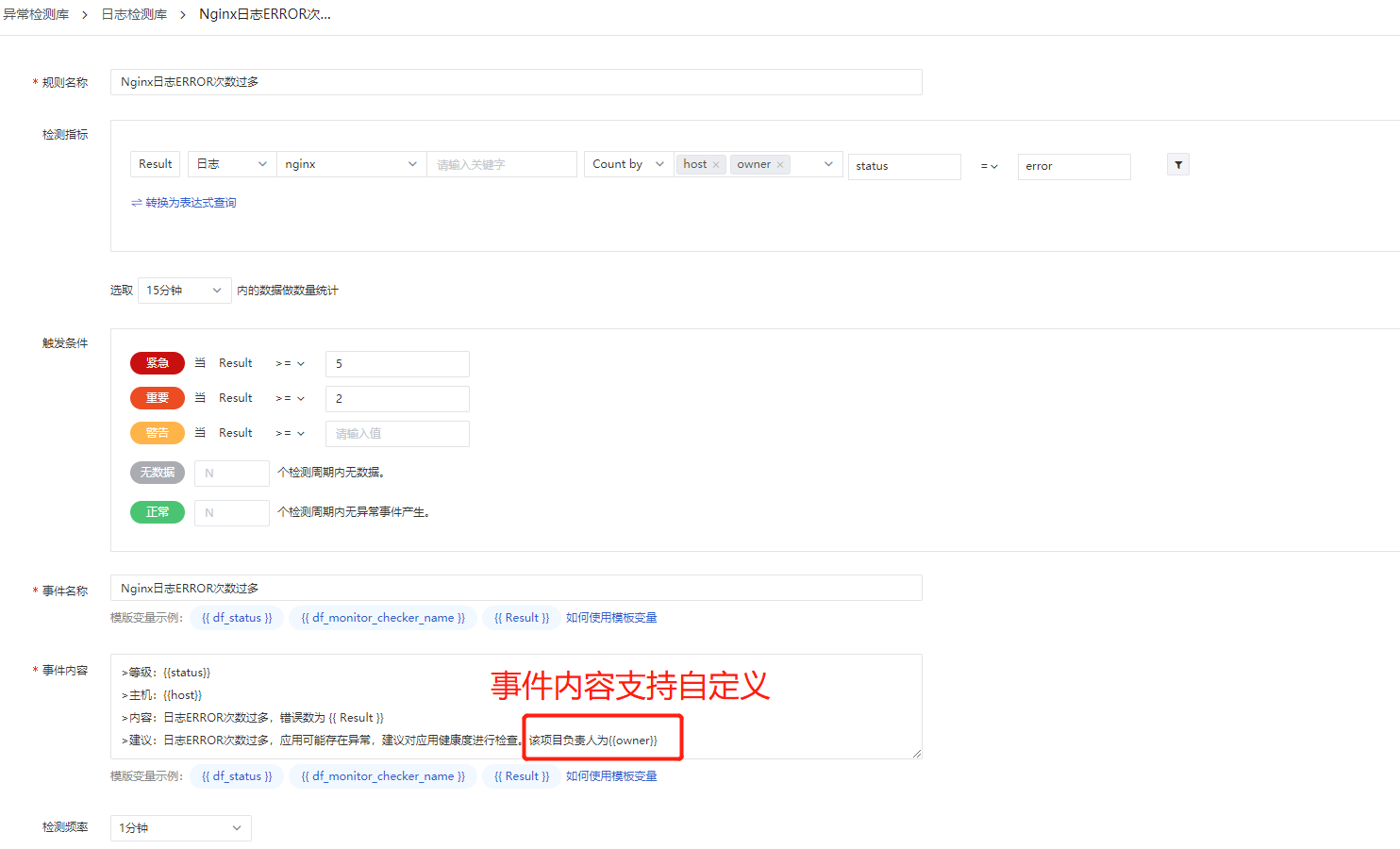
背景:企业内部随着企业业务的发展,微服务、容器被大量使用,服务组件越来越多,相应的开发及运维人员也越来越多,每个人的分工也越来越细,当业务系统或IT系统出现故障,最佳的告警实践就是可以直接指定相关负责人员,从而提高告警闭环的效率,这种方式常用的方式是告警只发送给相关的人员,或者是jira指派工单,那DF是怎么操作的呢?DF中只需要在具体的可观测inputs中添加tag(理论上支持无上限的tag数量),例如在nginx-inputs中添加自定义tag,owner = "xxx",然后在异常检测中将owner设置为变量,异常检测就可以自动识别该字段并发送至钉钉或企业微信群,效果如下:
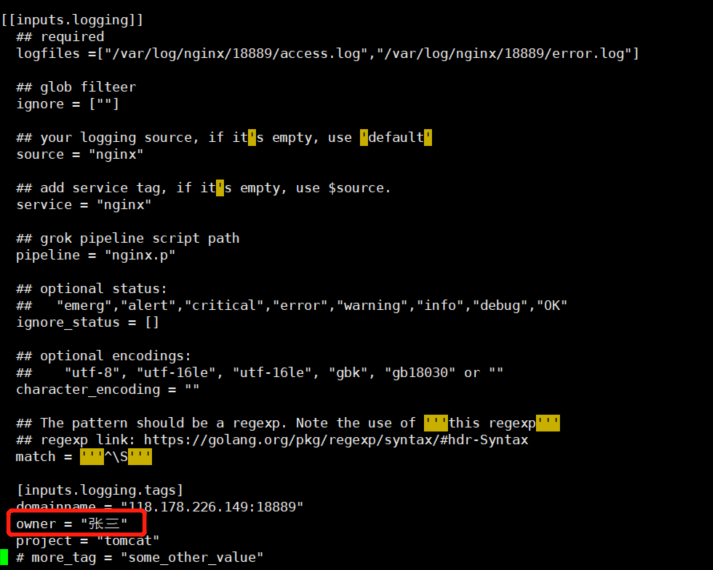
例如在上述的nginx自定义日志中进行添加:
1、在inputs中添加tag
2、配置异常检测
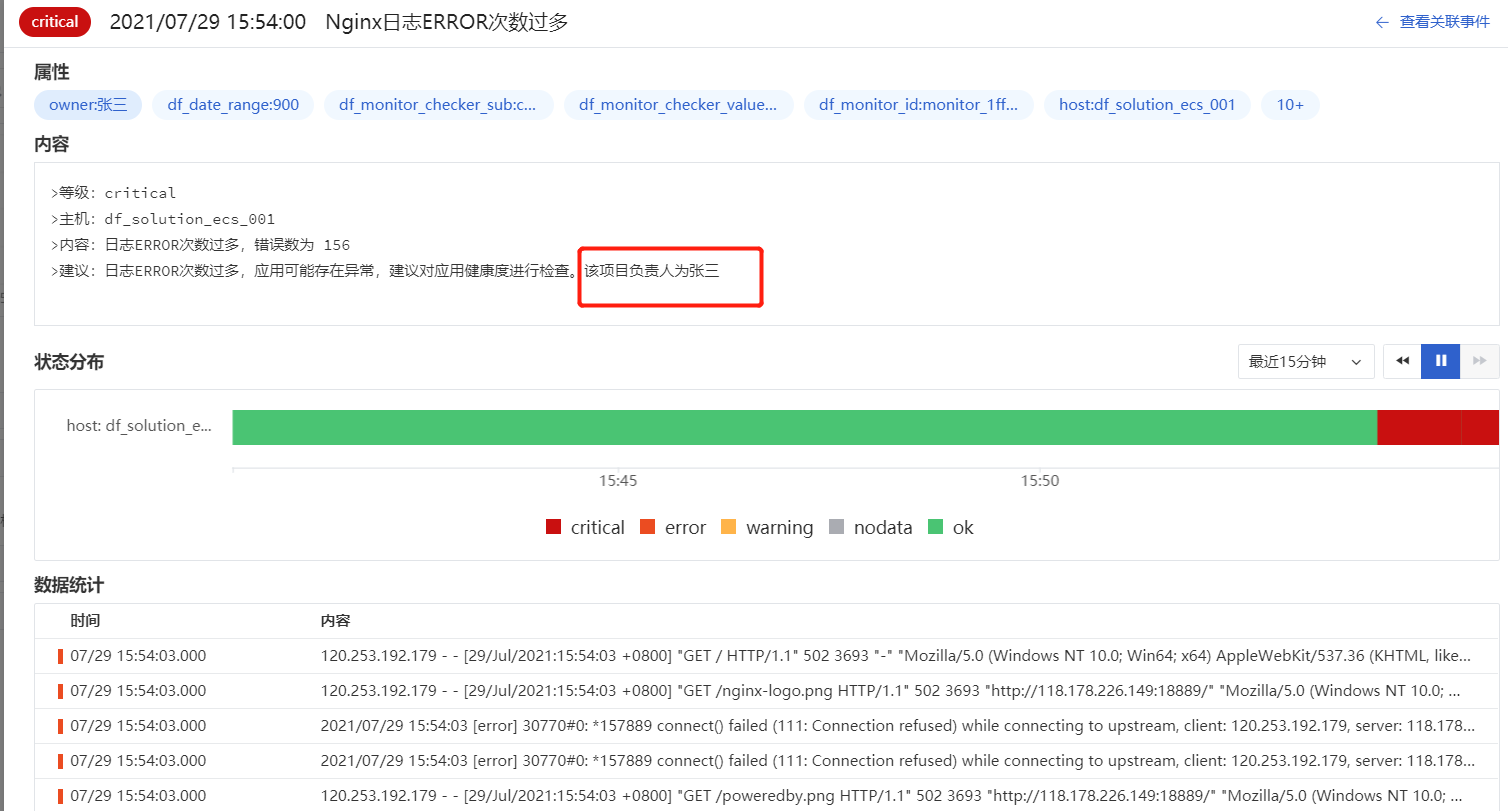
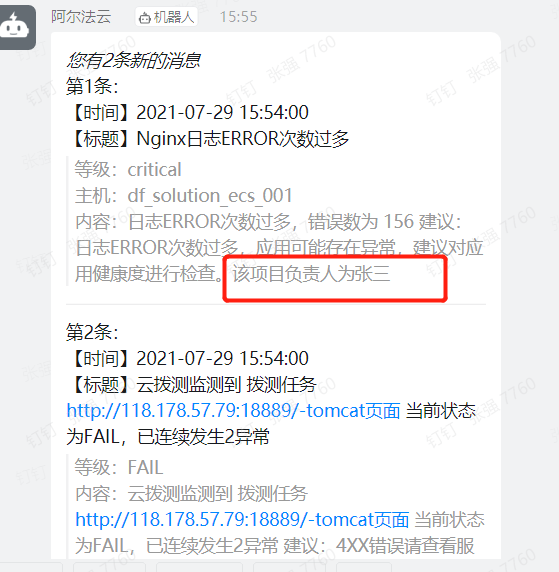
3、触发告警,查看告警事件

干货!4大实验项目,深度解析Tag在可观测性领域的最佳实践!的更多相关文章
- DDD实战进阶第一波(八):开发一般业务的大健康行业直销系统(业务逻辑条件判断最佳实践)
这篇文章其实是大健康行业直销系统的番外篇,主要给大家讲讲如何在领域逻辑中,有效的处理业务逻辑条件判断的最佳实践问题. 大家都知道,聚合根.实体和值对象这些领域对象都自身处理自己的业务逻辑.在业务处理过 ...
- 微服务电商项目发布重大更新,打造Spring Cloud最佳实践!
Spring Cloud实战电商项目mall-swarm地址:转发+关注 私信我获取地址 系统架构图 系统架构图 项目组织结构 mall├── mall-common-- 工具类及通用代码模块├─ ...
- 华为全栈AI技术干货深度解析,解锁企业AI开发“秘籍”
摘要:针对企业AI开发应用中面临的痛点和难点,为大家带来从实践出发帮助企业构建成熟高效的AI开发流程解决方案. 在数字化转型浪潮席卷全球的今天,AI技术已经成为行业公认的升级重点,正在越来越多的领域为 ...
- 深度解析开发项目之 05 - 解决textField编辑之后点击其他内容改变的问题
深度解析开发项目之 05 - 解决textField编辑之后点击其他内容改变的问题 问题的解决: 只需要给HeadeVIew加上这句代码
- 深度解析开发项目之 03 - enum的使用
深度解析开发项目之 03 - enum的使用 01 - 在#import和@interface之间定义typedef enum 注意: 默认是0,1,2,3 02 - 定义可以操作的数据类型的属性 0 ...
- 深度解析开发项目之 02 - 使用VTMagic实现左右滑动的列表页
深度解析开发项目之 02 - 使用VTMagic实现左右滑动的列表页 实现效果: 01 - 导入头文件 02 - 遵守代理协议 03 - 声明控制器的属性 04 - 设置声明属性的frame 05 - ...
- 深度解析开发项目之 01 - SVProgressHUD用法
深度解析开发项目之 01 - SVProgressHUD用法 首先来到工程的pch文件中 01 - 导入头文件 02 - 定义宏 03 - 项目中的使用 3.1 - SVHUD_Normal: 3. ...
- Kafka深度解析
本文转发自Jason’s Blog,原文链接 http://www.jasongj.com/2015/01/02/Kafka深度解析 背景介绍 Kafka简介 Kafka是一种分布式的,基于发布/订阅 ...
- Unity加载模块深度解析(Shader)
作者:张鑫链接:https://zhuanlan.zhihu.com/p/21949663来源:知乎著作权归作者所有.商业转载请联系作者获得授权,非商业转载请注明出处. 接上一篇 加载模块深度解析(二 ...
随机推荐
- python 10篇 操作mysql
一.操作数据库 使用pip install pymysql,安装pymysql模块,使用此模块连接MySQL数据库并操作数据库. import pymysql host = 'ip地址' # 链接的主 ...
- noip模拟26[肾炎黄·酱累黄·换莫黄]
\(noip模拟26\;solutions\) 这个题我做的确实是得心应手,为啥呢,因为前两次考试太难了 T1非常的简单,只不过我忘记了一个定理, T2就是一个小小的线段树,虽然吧我曾经说过我再也不写 ...
- 配置软ISCSI存储
说明:这里是Linux服务综合搭建文章的一部分,本文可以作为单独使用RedHat Enterprise Linux 7搭建软ISCSI的参考. 注意:这里所有的标题都是根据主要的文章(Linux基础服 ...
- shell脚本(11)-流程控制case
一.case介绍 生产环境下,遇到要根据不同的状况执行不同的预案的情况,首先根据可能出现的情况写出对应预案,根据出现的情况来加载不同的预案 特点:根据给予的不同的代码块 二.case语法 case 变 ...
- Supervisord 远程命令执行漏洞(CVE-2017-11610)
漏洞影响范围: Supervisor version 3.1.2至Supervisor version 3.3.2 poc 地址.https://github.com/vulhub/vulhub/tr ...
- Dubbo 实现一个Load Balance (用于灰度发布)
Dubbo 可以实现的扩展很多, 官方文档在这: https://dubbo.apache.org/zh/docs/v2.7/dev/impls/ (太简单了....) 下面我们实现一个Load Ba ...
- SQL SERVER获取表在哪些存储过程中使用过
1.获取某张表在哪些存储过程中使用到 select distinct object_name(id) from syscomments where id in (select object_id fr ...
- 记录21.07.24 —— Vue的组件与路由
VUE组件 作用:复用性 创建组件的三种方式 第一种:使用extends搭配component方法 第二种:直接使用component方法 只有用vue声明且命名的才称之为创建组件 注意:templa ...
- OpenGL学习笔记(五)变换
目录 变换 向量 向量的运算 向量与标量运算 向量取反 向量加减 求向量长度 向量的单位化 向量相乘 点乘(Dot Product) 叉乘 矩阵 矩阵的加减 矩阵的数乘 矩阵相乘 矩阵与向量相乘 与单 ...
- oracle控制用户权限命令
ORACLE控制用户权限: 首先使用系统中的拥有DBA权限的账号(system)登录: 一.创建用户: 1.DBA使用creater user语句创建用户: --创建登录用户名为:user01,密码为 ...