PySpider爬取去哪儿攻略数据项目
1 创建项目
- 点击WEB中的Create创建项目

- 填入相关项目名和其实爬取URL
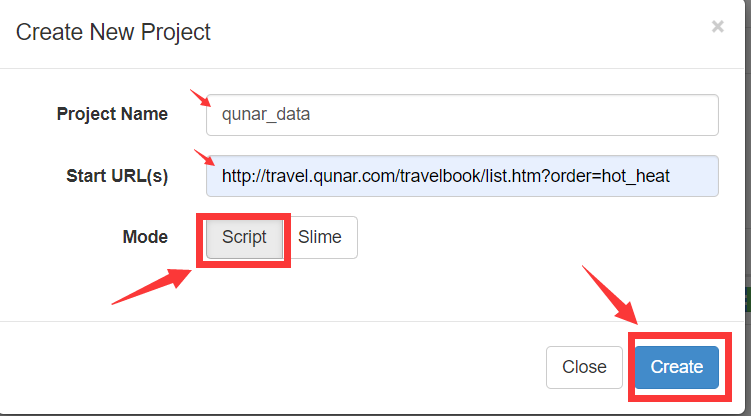
- 创建后进入项目首页

- 右边 Handler 是pyspider的主类,整个爬虫一个Handler,其中可定义爬虫的爬取、解析、存储逻辑;crawl_config 中定义项目爬取配置;on_start() 爬取入口,通过调用 crawl() 方法新建爬取请求,第一个参数是爬取的URL,另外一个参数callback指定爬取成功后的解析方法,即index_page()。index_page() 接收Response参数,Response对接了pyquery,可直接调用doc()解析页面;detail_page() 方法接收Response参数,抓取详情页信息,不生成新的请求,对Response解析后以字典形式返回数据。
- 左边,上面绿色和灰色是运行参数内容,下面点击左边RUN按钮,运行项目,follow中是请求连接,点击连接右边运行三角,进入页面;html是源码;web是渲染页面; enable css selecter helper帮助进行css选择,在右边代码中选中doc方法引号中内容后,点击web窗口右上方箭头实现右边代码css选择替换;massage是页面信息。
- 点击run运行项目

- 发现follows中出现一条消息,点击follows

- 出现如下界面
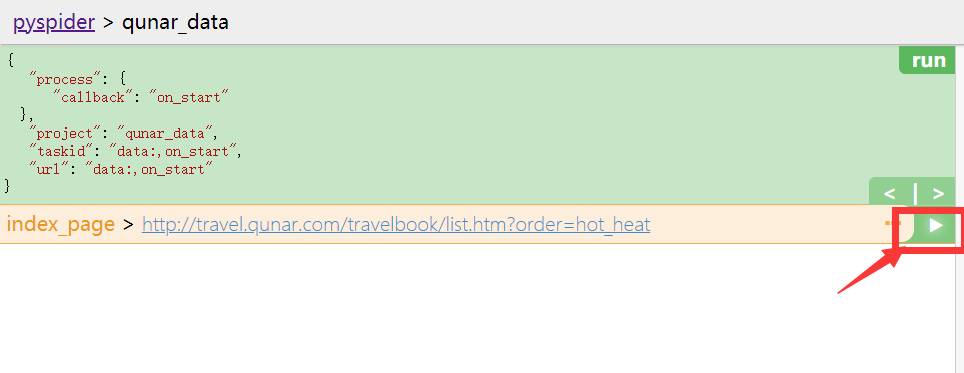
- 点击三角运行符号,进入该界面
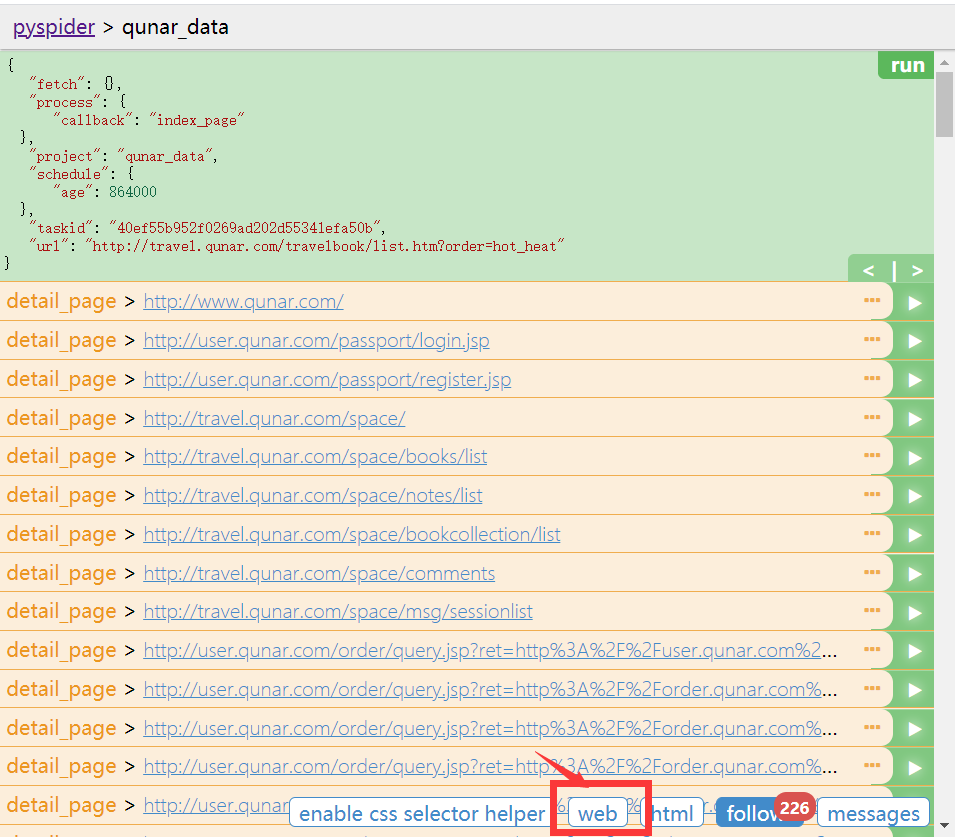
- 出现页面所有请求后,点击HTML显示源码,点击web展示页面,如果web窗口太小,可以通过开发者模式调整(尝试网上说的修改debug.min.css失败)

- 选择右边index_page()方法中的css选择器内容,点击左边enable css selecter helper然后选择对应元素,在3位置出现选择的元素后,点击右边箭头,对右边代码选中内容进行替换
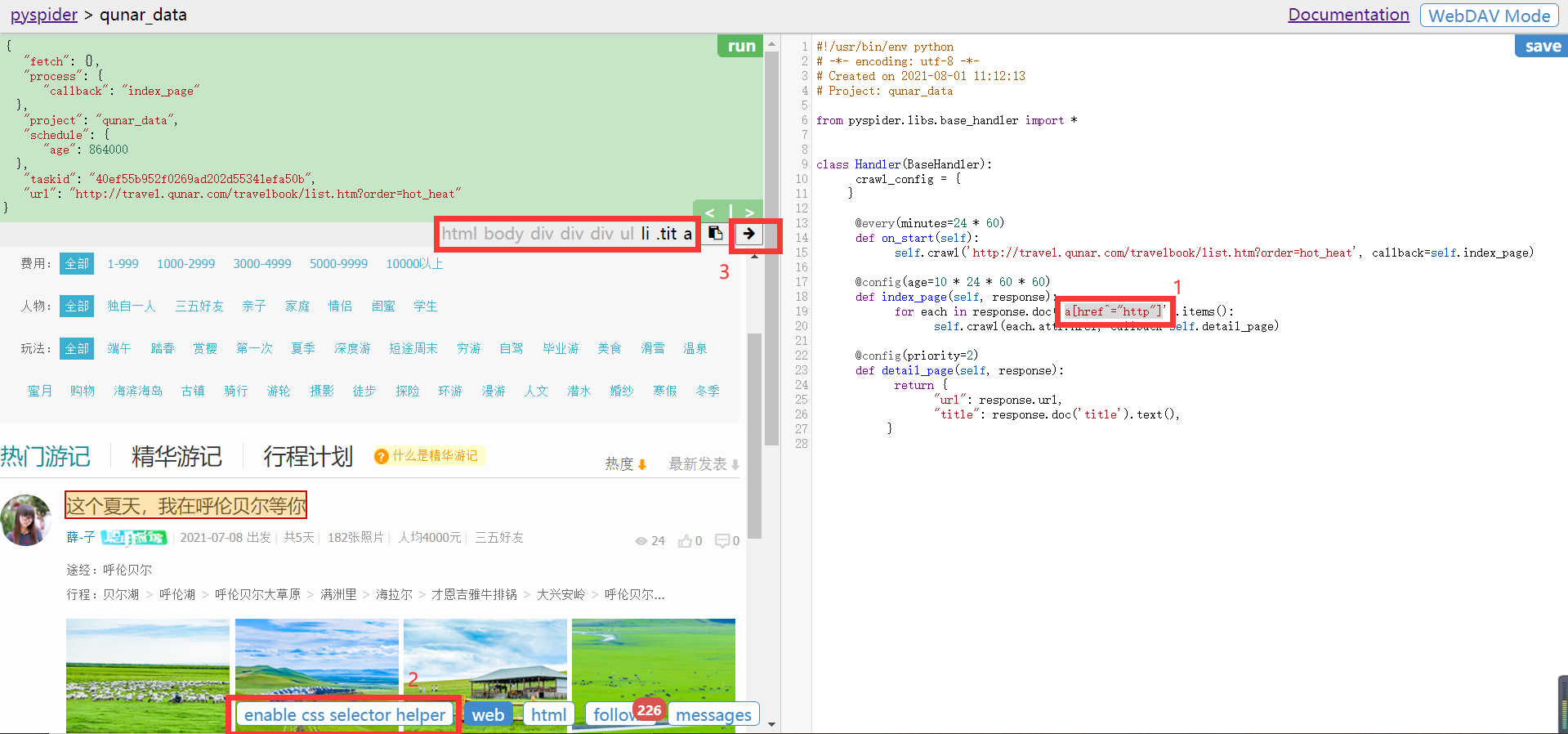
- 再次点击左边run,follows变成10条选中css的请求连接。
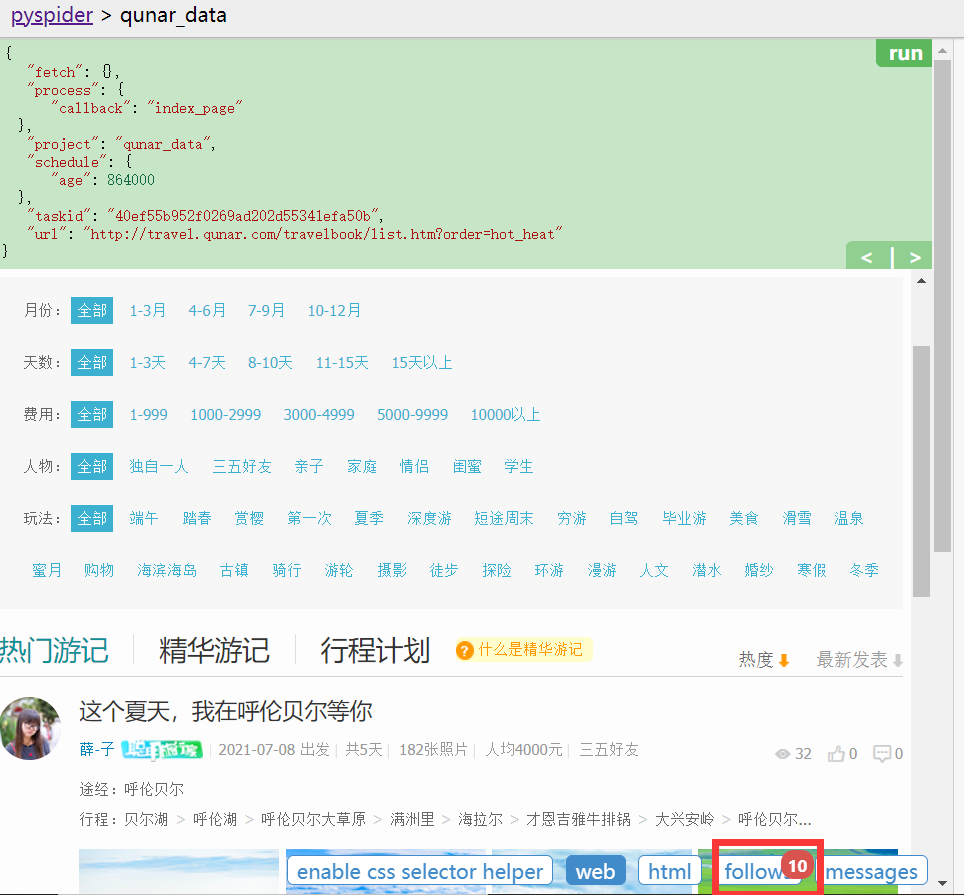
- 要想选择多页,即实现自动翻页爬取,修改index_page()内容
@config(age=10 * 24 * 60 * 60)
def index_page(self, response):
for each in response.doc('li > .tit > a').items():
self.crawl(each.attr.href, callback=self.detail_page)
next=response.doc('.next').attr.href
self.crawl(next,callback=self.index_page)
- 再次点击run,follows变成11(多了next)
- 随便点进一个内容连接,发现没有图片,需要修改crawl添加fetch参数,修改后,重新run
self.crawl(each.attr.href, callback=self.detail_page,fetch_type='js')

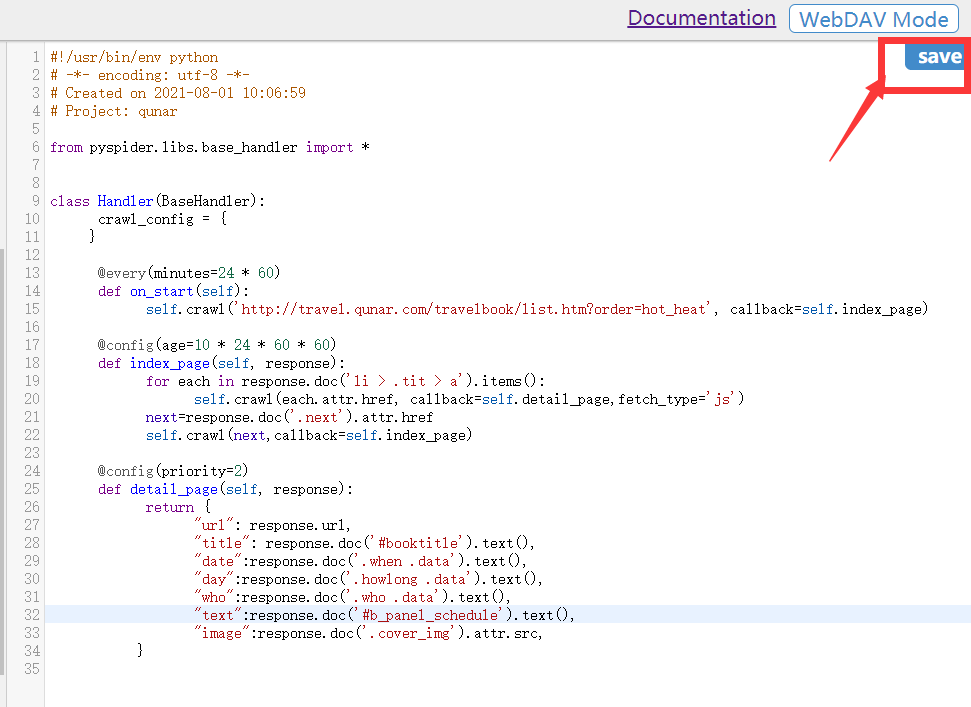
- 然后修改detail_page(),设置要保存的数据信息
@config(priority=2)
def detail_page(self, response):
return {
"url": response.url,
"title": response.doc('#booktitle').text(),
"date":response.doc('.when .data').text(),
"day":response.doc('.howlong .data').text(),
"who":response.doc('.who .data').text(),
"text":response.doc('#b_panel_schedule').text(),
"image":response.doc('.cover_img').attr.src,
}
- 点击run运行成功后,点击右边save保存项目
- 之后就可以返回pyspider首页,管理项目

- 选择项目运行状态,设置rate/burst【rate表示1s发出多少个请求;burst相当于流控制中令牌桶算法的令牌数;这两个值越大爬取速率越快,也越有可能被封】; progress 四个进度条各时间段状态,蓝色等待执行,绿色成功执行,黄色失败后等待重试,红色失败太多被忽略的任务actions可以运行项目查看结果。
- 我们可以看一下result,右上角可以下载数据

2 pyspider用法详解
- 命令行:
pyspider all / pyspider # 启动
pyspider [OPTIONS] COMMAND [ARGS]
可以指定配置文件访问,pyspider -c pyspider.json all
也可以单独运行一个组件,pyspider scheduler/fetcher/processor [OPTIONS]
更换端口运行 pyspider webui --port 5001 ,也可以写进配置文件中
- crawl方法参数配置:
url 可以是列表也可以是字符串;callback 回调函数解析响应的方法;age 任务的有效时间;priority 优先级越大越优先;exetime 定时任务,时间戳类型;retries 重试次数,默认为3;itag 判定网页是否发生变化的节点值;auto_recrawl 值为true即开启后爬取任务过期后悔重新执行;method HTTP请求方式默认是GET;params 定义get请求参数;data 定义POST表单数据;files 定义上传文件;user_agent;headers;cookies;connect_timeout 初始化最长等待时间,默认20s;timeout 抓取最长等待时间,默认120s;allow_redirects 自动处理重定向,默认True;validate_cert 是否验证证书 对HTTPS有效,默认True;proxy 代理;fetch_type 开启PhantomJS渲染;js_script 页面加载后执行的js脚本;js_run_at js脚本运行位置,默认document-end;js_viewport_width/js_viewport_height js渲染时窗口大小;load_iamges 在加载js页面时是否加载图片,默认否;save 可以在不同方法直接传递参数;cancel 取消任务,如果一个任务是active状态,需要设置force_update为True;force_update 强制更新状态
- 任务区分
pyspider判断两个任务是否重复,对URL的MD5值作为任务的唯一ID。重写task_id()方法可以改变ID计算方式,进行区分如相同URL的post和get
- 全局配置
在crawl_config中进行指定
- 定时爬取
可以在on_start前的every属性设置爬取的时间间隔,24*60代表每天执行一次。index_page上面的age代表过期时间,如果未到过期时间是不会重新执行的。
- 项目状态
TODO 刚创建还没有实现;STOP 停止某项目抓取;CHECKING 正在运行的项目被修改后;DEBUG/RUNNIG 调试/运行;PAUSE 暂停,爬取中多次连续错误,会被自动设置暂停,一段时间后继续爬取;
- 抓取进度
progress 四个进度条各时间段状态,蓝色等待执行,绿色成功执行,黄色失败后等待重试,红色失败太多被忽略的任务。
- 删除项目
pyspider没有删除项目的选项,如果要删除,将项目状态设置为STOP,分组名称设置为delete,24h后自动删除。
PySpider爬取去哪儿攻略数据项目的更多相关文章
- Python爬虫系列之爬取美团美食板块商家数据(二)
今天为大家重写一个美团美食板块小爬虫,说不定哪天做旅游攻略的时候也可以用下呢.废话不多说,让我们愉快地开始吧~ 开发工具 Python版本:3.6.4 相关模块: requests模块: argpar ...
- Java爬虫系列四:使用selenium-java爬取js异步请求的数据
在之前的系列文章中介绍了如何使用httpclient抓取页面html以及如何用jsoup分析html源文件内容得到我们想要的数据,但是有时候通过这两种方式不能正常抓取到我们想要的数据,比如看如下例子. ...
- 爬虫(二)Python网络爬虫相关基础概念、爬取get请求的页面数据
什么是爬虫 爬虫就是通过编写程序模拟浏览器上网,然后让其去互联网上抓取数据的过程. 哪些语言可以实现爬虫 1.php:可以实现爬虫.php被号称是全世界最优美的语言(当然是其自己号称的,就是王婆 ...
- 使用 Scrapy 爬取去哪儿网景区信息
Scrapy 是一个使用 Python 语言开发,为了爬取网站数据,提取结构性数据而编写的应用框架,它用途广泛,比如:数据挖掘.监测和自动化测试.安装使用终端命令 pip install Scrapy ...
- 网络字体反爬之pyspider爬取起点中文小说
前几天跟同事聊到最近在看什么小说,想起之前看过一篇文章说的是网络十大水文,就想把起点上的小说信息爬一下,搞点可视化数据看看.这段时间正在看爬虫框架-pyspider,觉得这种网站用框架还是很方便的,所 ...
- python 爬取天猫美的评论数据
笔者最近迷上了数据挖掘和机器学习,要做数据分析首先得有数据才行.对于我等平民来说,最廉价的获取数据的方法,应该是用爬虫在网络上爬取数据了.本文记录一下笔者爬取天猫某商品的全过程,淘宝上面的店铺也是类似 ...
- Python网络爬虫第三弹《爬取get请求的页面数据》
一.urllib库 urllib是Python自带的一个用于爬虫的库,其主要作用就是可以通过代码模拟浏览器发送请求.其常被用到的子模块在Python3中的为urllib.request和urllib. ...
- Python爬虫《爬取get请求的页面数据》
一.urllib库 urllib是Python自带的一个用于爬虫的库,其主要作用就是可以通过代码模拟浏览器发送请求.其常被用到的子模块在Python3中的为urllib.request和urllib. ...
- 02. 爬取get请求的页面数据
目录 02. 爬取get请求的页面数据 一.urllib库 二.由易到难的爬虫程序: 02. 爬取get请求的页面数据 一.urllib库 urllib是Python自带的一个用于爬虫的库,其主要作用 ...
随机推荐
- 【NX二次开发】属性操作总结
内容包括:1.属相创建2.判断属性是否存在3.读取属性值4.时间属性转换成字符串5.统计属性的数量6.删除指定属性7.删除全部属性 源码: 1 #include <stdlib.h> 2 ...
- python学习笔记04-了解操作符与条件分支
先来了解一下条件操作符: 运算符 描述 示例 == 检查两个操作数的值是否相等,如果是则条件变为真. 如a=3,b=3则(a == b) 为 true. != 检查两个操作数的值是否相等,如果值不相等 ...
- v-for和v-if不能同时使用
如果使用v-for遍历数据时,想筛选出URL不为空的项并进行渲染 <ul> <li v-for="(item,index) in list" v-if=" ...
- sql优化问题
一.分析阶段 一 般来说,在系统分析阶段往往有太多需要关注的地方,系统各种功能性.可用性.可靠性.安全性需求往往吸引了我们大部分的注意力,但是,我们必须注意,性能 是很重要的非功能性需求,必须根据系统 ...
- JWT原理实现代码
JWT学习文章: 第一篇:JWT原理 第二篇:JWT原理实现代码 上一篇学习了JWT的基本理论,这一篇将根据原理进行代码实现. 要想实现jwt的加密解密,要先生成一个SecurityKey,大家可以在 ...
- DDoS攻击的工具介绍
1.低轨道离子加农炮(LOIC) 1.1 什么是低轨道离子加农炮(LOIC)? 低轨道离子加农炮是通常用于发起DoS和DDoS攻击的工具.它最初是由Praetox Technology作为网络压力测试 ...
- 关于React Native常用技巧
Doctor命令检查所需环境 @2019年11月18日,React Native v新增了一个环境检查和诊断命令行,可以帮助新手修复环境,输出环境依赖报告. 先建好的一个React Native项目, ...
- Linux云计算-01_介绍以及Linux操作系统安装
1 学习目的 兴趣爱好 技能提升 找到满意的工作 2 什么是云计算 云计算(cloud computing)是分布式计算的一种,指的是通过网络"云"将巨大的数据计算处理程序分解成无 ...
- Spring Boot配置Filter
此博客是学习Spring Boot过程中记录的,一来为了加深自己的理解,二来也希望这篇博客能帮到有需要的朋友.同时如果有错误,希望各位不吝指教 一.通过注入Bean的方式配置Filter: 注意:此方 ...
- 升级Ubuntu 16.04 到 Ubuntu 18.04 的方法
特别注意,在进行升级前,请做好重要数据备份工作,防止升级失败或者其他奇怪原因,导致数据丢失或损坏 sudo vim /etc/apt/sources.list 将 http://archive.ubu ...