Kafka从入门到放弃(三) —— 详说生产者
上一篇对Kafka做了简单介绍,还没看的朋友可以点击下方链接。
消息中间件必须与生产者和消费者一起存在才有意义,这次先来聊聊Kafka的生产者。
在开始之前,先了解一下消息在Kafka中是如何存储的,如下图所示,一般我们称那些数字为offset(偏移量)一般来说,消息在持久化后应该是有序的,这里的有序是针对分区的,而不是针对 Topic 的。
而且,生产者写入消息时,是往 Leader 写入,Follower 从 Leader 进行复制。
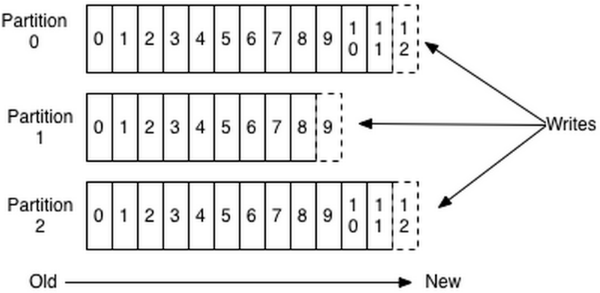
别看生产者只是发消息,调用 API 也是几行代码,但它的学问多着呢。为更好地理解后面的内容,请带着以下问题阅读:
- 生产者发送消息前会做什么准备?
- 生产者发送消息怎么保证数据不丢失?
- 生产者发送消息如何保证消息有序性?
- 生产者发送的消息是怎么分区的?
生产者设计了一个缓冲池,可以通过修改 buffer.memory 参数设置其大小;缓冲池内又有多个 Batch,当有多个消息需要写入同一个分区时,消息会先往 Batch 里面写入,等消息达到 batch.size 的时候开始发送,如果 batch.size 设置太小,生产者会频繁发送消息,带来更多的网络开销;
有些读者可能有这个疑问,如果有时候生产者生产的消息很少很小,一直达不到批次的大小,而消费者对时效性要求比较高,这种情况怎么办?其实,默认情况下,只要有线程,即使批次里只有一条消息,也会直接发送出去。但是,可以设置参数 linger.ms 来指定等待消息加入批次的时间,只要当批次消息达到 batch.size 或者等待时间达到 linger.ms 的时候,消息就会发送。
除此之外,生产者可以对消息进行压缩,以降低网络开销以及存储开销,通过设置参数 compression.type 设置相应的压缩算法。
先抛开 Kafka 现有确认机制,假如一条消息发到对应分区后,没有任何确认就紧接着发送第二条,很难不造成数据丢失。
于是我们让分区在收到消息后返回确认消息给生产者,生产者收到后发送下一条。
就这样,消息很顺利地发着,正好在 Leader 拿到最新的消息并返回确认给生产者的时候,Leader 挂了,此时,Follower 还没同步最新的消息,而生产者已经接收到了分区返回的确认,这时候还是丢了数据。
因此我们让 Leader 以及参与复制的 Follower 都收到消息后返回确认,这样就能最大程度保证消息不丢失,不过延迟较高。
针对上述的情况,Kafka 设置了一个 acks 参数,指定了必须有几个副本收到消息生产者才认为是写入成功了。
- acks=0,生产者只管写入,不会等待 Broker 返回响应,默认成功。这种情况最容易造成数据丢失,不过吞吐量最高;
- acks=1,Leader 收到消息后响应,生产者才认为写成功,这种也会造成丢失;
- acks=all,Kafka 集群内部会维护一个副本清单 ISR(后续会写,再此不做描述),当 ISR 里的所有副本都收到消息,才认为写入成功,最大程度保证消息不丢失,不过可能会造成延迟较高。
另外,Kafka 还有一个参数 retries,表示当消息发送失败后,生产者重试的次数,默认为0,如果对丢失消息零容忍,那就不能设置为0.
事实上,生产者在收到分区返回的确认消息前,还是可以持续发送消息的,这个可以通过设置 max.in.flight.requests.per.connection 参数进行修改,这个参数指定了生产者在收到响应前可以发送多少个消息。
这里需要注意的是,如果这个参数不为1,而 retries 参数也不为 0 的时候,当发生重试的时候,有可能造成分区数据顺序错乱。在有些场景下,顺序是很重要的,比如分析交易流水的过程,某个第一次存款的客户先存1块钱再取1块钱是正常的,但反过来可能就有点奇怪了。
所以,如果要保证数据不丢失,同时要保证数据有序性,就需要将 retries 设置为非 0 整数,max.in.flight.requests.per.connection 设置为 1,注意不是 0.
生产者可以指定键作为分区键,如果不指定,生产者会使用轮询算法将消息均匀的发到各个分区上
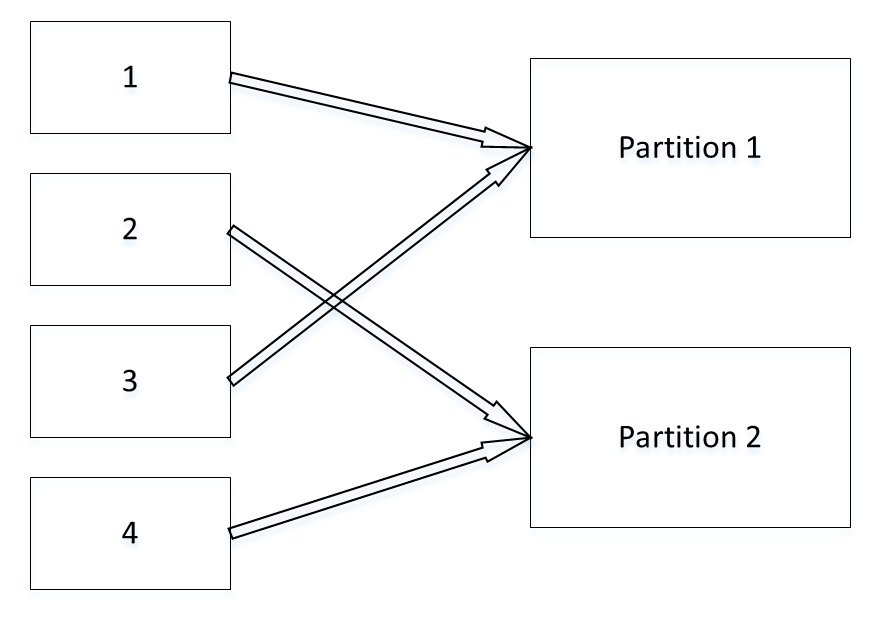
但如果指定了分区键,Kafka 会使用自己的 hash 算法获得 hash 值,然后根据 hash 值发到相应的分区。
到这,回顾一下前面的几个问题,是不是有点豁然开朗了?
如果觉得写得不错,对你有帮助,麻烦点个小小的赞,谢谢!
转载请注明出处:工众号“大数据的奇妙冒险”,博客园 Lyu_zt
Kafka从入门到放弃(三) —— 详说生产者的更多相关文章
- Kafka从入门到放弃(三)—— 详说消费者
之前介绍了Kafka以及生产者,包括它的一些特性和参数,这回写一下消费者. 之前没看得可以点击链接阅读. Kafka从入门到放弃(一) -- 初识Kafka Kafka从入门到放弃(二) -- 详说生 ...
- kafka原理和实践(三)spring-kafka生产者源码
系列目录 kafka原理和实践(一)原理:10分钟入门 kafka原理和实践(二)spring-kafka简单实践 kafka原理和实践(三)spring-kafka生产者源码 kafka原理和实践( ...
- hive从入门到放弃(三)——DML数据操作
上一篇给大家介绍了 hive 的 DDL 数据定义语言,这篇来介绍一下 DML 数据操作语言. 没看过的可以点击跳转阅读: hive从入门到放弃(一)--初识hive hive从入门到放弃(二)--D ...
- storm从入门到放弃(三),放弃使用《StreamId》特性。
序:StreamId是storm中实现DAG有向无环图的重要一个特性,但是从实际生产环境来看,这个功能其实蛮影响生产环境的稳定性的,我们系统在迭代时会带来整体服务的不可用. StreamId是stor ...
- storm从入门到放弃(三),放弃使用 StreamId 特性
序:StreamId是storm中实现DAG有向无环图的重要一个特性,但是从实际生产环境来看,这个功能其实蛮影响生产环境的稳定性的,我们系统在迭代时会带来整体服务的不可用. StreamId是stor ...
- Kafka从入门到放弃(一) —— 初识Kafka
消息中间件的使用已经越来越广泛,基本上具有一定规模的系统都会用到它,在大数据领域也是个必需品,但为什么使用它呢?一个技术的广泛使用必然有它的道理. 背景与问题 以前一些传统的系统,基本上都是" ...
- robotium从入门到放弃 三 基于apk的自动化测试
1.apk重签名 在做基于APK的自动化测试的过程中,需要确保的一点是,被测试的APK必须跟测试项目具有相同的签名,那怎么做才能确保两者拥有相同的签名呢?下面将给出具体的实现方法. 首先将被测 ...
- Go语言从入门到放弃(三) 布尔/数字/格式化输出
本章主要介绍Go语言的数据类型 布尔(bool) 布尔指对或者错,也就是说bool只有两个值, True 或 False 两个类型相同的值可以使用比较运算符来得出一个布尔值 当两个值是完全相同的情况下 ...
- MyBatis从入门到放弃三:一对一关联查询
前言 简单来说在mybatis.xml中实现关联查询实在是有些麻烦,正是因为起框架本质是实现orm的半自动化. 那么mybatis实现一对一的关联查询则是使用association属性和resultM ...
随机推荐
- [ARC117F]Gateau
假设序列$b_{i}$为最终第$i$片上的草莓数,即需要满足:$\forall 0\le i<2n,a_{i}\le \sum_{j=0}^{n-1}b_{(i+j)mod\ 2n}$ 要求最小 ...
- UNCTF2020 web writeup
1.Easy_ssrf 给了file_get_contents,直接读取flag即可 2.Easyunserialize 利用点在 构造uname反序列化逃逸即可 3.Babyeval 两个过滤,绕过 ...
- 多线程06.thread守护线程
package chapter2; public class Demo02 { public static void main(String[] args) { Thread th1=new Thre ...
- 什么是CLI、GUI
就是命令行界面command-line interface,也有人称之为字符用户界面(CUI). 通常认为,命令行界面(CLI)没有图形用户界面(GUI)那么方便用户操作. 因为,命令行界面的软件通常 ...
- 洛谷 P7516 - [省选联考 2021 A/B 卷] 图函数(Floyd)
洛谷题面传送门 一道需要发现一些简单的性质的中档题(不过可能这道题放在省选 D1T3 中偏简单了?) u1s1 现在已经是 \(1\text{s}\) \(10^9\) 的时代了吗?落伍了落伍了/ ...
- CUDA计算矩阵相乘
1.最简单的 kernel 函数 __global__ void MatrixMulKernel( float* Md, float* Nd, float* Pd, int Width) { int ...
- perl 子函数传入多个数组
perl中的引用和C中的指针一样,用"\"标识,引用后可使用符号"->"取值.解引用则在对应的数据类型前加$,@ 或%. 这里这里用两数组求和做示例,引用 ...
- exit(0) exit(1) return() 3个的区别
exit(0):正常运行程序并退出程序: exit(1):非正常运行导致退出程序: return():返回函数,若在主函数中,则会退出函数并返回一值. 详细说: 1. return返回函数值,是关键字 ...
- 【Go语言学习笔记】包
包其实是每个大型工程都会使用的模块化工具. 将相关的代码封装成一个包,给其他项目调用,提供不同的功能. GO的设计是将一个文件夹看成一个包,虽然不一定非要用文件夹的名字,但是比较建议. 同一个文件夹下 ...
- day12 keepalived高可用
day12 keepalived高可用 一.高可用介绍 1.什么是高可用 部署在整个集群中的一个高可用软件,作用是创建一个VIP(虚拟IP),在整个集群中有且只有一个机器上生成VIP,当这台机器出现问 ...