Kafka日志存储原理
引言
Kafka中的Message是以topic为基本单位组织的,不同的topic之间是相互独立的。每个topic又可以分成几个不同的partition(每个topic有几个partition是在创建topic时指定的),每个partition存储一部分Message。借用官方的一张图,可以直观地看到topic和partition的关系。
partition是以文件的形式存储在文件系统中,比如,创建了一个名为page_visits的topic,其有5个partition,那么在Kafka的数据目录中(由配置文件中的log.dirs指定的)中就有这样5个目录: page_visits-0, page_visits-1,page_visits-2,page_visits-3,page_visits-4,其命名规则为<topic_name>-<partition_id>,里面存储的分别就是这5个partition的数据。
接下来,本文将分析partition目录中的文件的存储格式和相关的代码所在的位置。
Partition的数据文件
Partition中的每条Message由offset来表示它在这个partition中的偏移量,这个offset不是该Message在partition数据文件中的实际存储位置,而是逻辑上一个值,它唯一确定了partition中的一条Message。因此,可以认为offset是partition中Message的id。partition中的每条Message包含了以下三个属性:
- offset
- MessageSize
- data
其中offset为long型,MessageSize为int32,表示data有多大,data为message的具体内容。它的格式和Kafka通讯协议中介绍的MessageSet格式是一致。
Partition的数据文件则包含了若干条上述格式的Message,按offset由小到大排列在一起。它的实现类为FileMessageSet,类图如下:
它的主要方法如下:
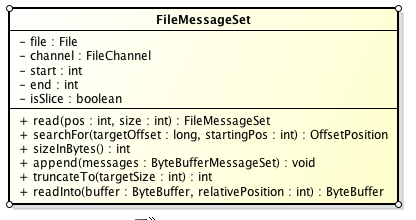
- append: 把给定的ByteBufferMessageSet中的Message写入到这个数据文件中。
- searchFor: 从指定的startingPosition开始搜索找到第一个Message其offset是大于或者等于指定的offset,并返回其在文件中的位置Position。它的实现方式是从startingPosition开始读取12个字节,分别是当前MessageSet的offset和size。如果当前offset小于指定的offset,那么将position向后移动LogOverHead+MessageSize(其中LogOverHead为offset+messagesize,为12个字节)。
- read:准确名字应该是slice,它截取其中一部分返回一个新的FileMessageSet。它不保证截取的位置数据的完整性。
- sizeInBytes: 表示这个FileMessageSet占有了多少字节的空间。
- truncateTo: 把这个文件截断,这个方法不保证截断位置的Message的完整性。
- readInto: 从指定的相对位置开始把文件的内容读取到对应的ByteBuffer中。
我们来思考一下,如果一个partition只有一个数据文件会怎么样?
- 新数据是添加在文件末尾(调用FileMessageSet的append方法),不论文件数据文件有多大,这个操作永远都是O(1)的。
- 查找某个offset的Message(调用FileMessageSet的searchFor方法)是顺序查找的。因此,如果数据文件很大的话,查找的效率就低。
那Kafka是如何解决查找效率的的问题呢?有两大法宝:1) 分段 2) 索引。
数据文件的分段
Kafka解决查询效率的手段之一是将数据文件分段,比如有100条Message,它们的offset是从0到99。假设将数据文件分成5段,第一段为0-19,第二段为20-39,以此类推,每段放在一个单独的数据文件里面,数据文件以该段中最小的offset命名。这样在查找指定offset的Message的时候,用二分查找就可以定位到该Message在哪个段中。
为数据文件建索引
数据文件分段使得可以在一个较小的数据文件中查找对应offset的Message了,但是这依然需要顺序扫描才能找到对应offset的Message。为了进一步提高查找的效率,Kafka为每个分段后的数据文件建立了索引文件,文件名与数据文件的名字是一样的,只是文件扩展名为.index。
索引文件中包含若干个索引条目,每个条目表示数据文件中一条Message的索引。索引包含两个部分(均为4个字节的数字),分别为相对offset和position。
- 相对offset:因为数据文件分段以后,每个数据文件的起始offset不为0,相对offset表示这条Message相对于其所属数据文件中最小的offset的大小。举例,分段后的一个数据文件的offset是从20开始,那么offset为25的Message在index文件中的相对offset就是25-20 = 5。存储相对offset可以减小索引文件占用的空间。
- position,表示该条Message在数据文件中的绝对位置。只要打开文件并移动文件指针到这个position就可以读取对应的Message了。
index文件中并没有为数据文件中的每条Message建立索引,而是采用了稀疏存储的方式,每隔一定字节的数据建立一条索引。这样避免了索引文件占用过多的空间,从而可以将索引文件保留在内存中。但缺点是没有建立索引的Message也不能一次定位到其在数据文件的位置,从而需要做一次顺序扫描,但是这次顺序扫描的范围就很小了。
在Kafka中,索引文件的实现类为OffsetIndex,它的类图如下:

主要的方法有:
- append方法,添加一对offset和position到index文件中,这里的offset将会被转成相对的offset。
- lookup, 用二分查找的方式去查找小于或等于给定offset的最大的那个offset
小结
我们以几张图来总结一下Message是如何在Kafka中存储的,以及如何查找指定offset的Message的。
Message是按照topic来组织,每个topic可以分成多个的partition,比如:有5个partition的名为为page_visits的topic的目录结构为:

partition是分段的,每个段叫LogSegment,包括了一个数据文件和一个索引文件,下图是某个partition目录下的文件:
可以看到,这个partition有4个LogSegment。

查找Message原理图:
比如:要查找绝对offset为7的Message:
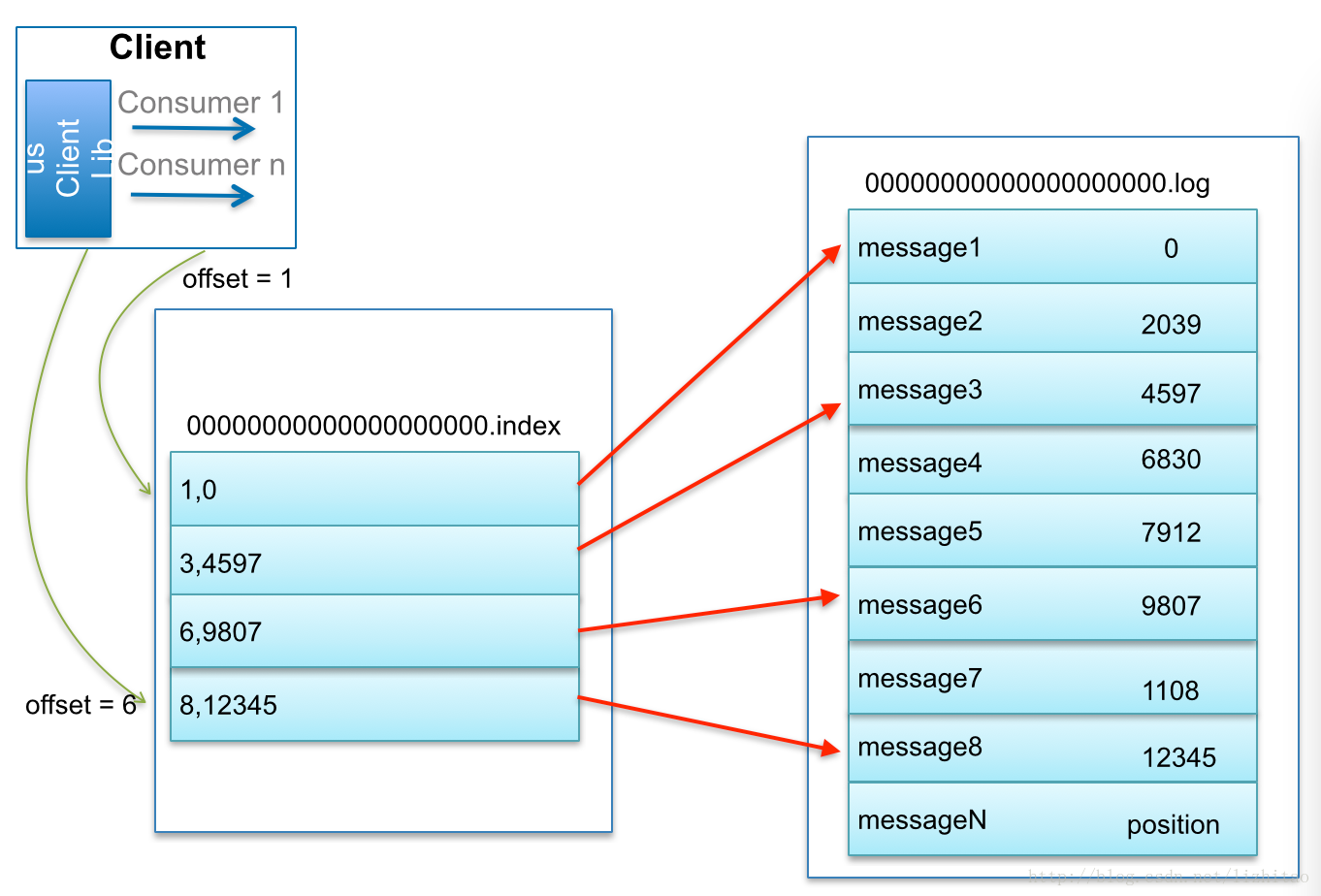
- 首先是用二分查找确定它是在哪个LogSegment中,自然是在第一个Segment中。
- 打开这个Segment的index文件,也是用二分查找找到offset小于或者等于指定offset的索引条目中最大的那个offset。自然offset为6的那个索引是我们要找的,通过索引文件我们知道offset为6的Message在数据文件中的位置为9807。
- 打开数据文件,从位置为9807的那个地方开始顺序扫描直到找到offset为7的那条Message。
这套机制是建立在offset是有序的。索引文件被映射到内存中,所以查找的速度还是很快的。
一句话,Kafka的Message存储采用了分区(partition),分段(LogSegment)和稀疏索引这几个手段来达到了高效性。
Kafka日志存储原理的更多相关文章
- 【原创】阿里三面:搞透Kafka的存储架构,看这篇就够了
阅读本文大约需要30分钟.这篇文章干货很多,希望你可以耐心读完. 你好, 我是华仔,在这个 1024 程序员特殊的节日里,又和大家见面了. 从这篇文章开始,我将对 Kafka 专项知识进行深度剖析, ...
- Es+kafka搭建日志存储查询系统(设计)
现在使用的比较常用的日志分析系统有Splunk和Elk,Splunk功能齐全,处理能力强,但是是商用项目,而且收费高.Elk则是Splunk项目的一个开源实现,Elk是ElasticSearch(Es ...
- kafka知识体系-kafka设计和原理分析-kafka文件存储机制
kafka文件存储机制 topic中partition存储分布 假设实验环境中Kafka集群只有一个broker,xxx/message-folder为数据文件存储根目录,在Kafka broker中 ...
- kafka知识体系-kafka设计和原理分析
kafka设计和原理分析 kafka在1.0版本以前,官方主要定义为分布式多分区多副本的消息队列,而1.0后定义为分布式流处理平台,就是说处理传递消息外,kafka还能进行流式计算,类似Strom和S ...
- Kafka文件存储机制及partition和offset
转载自: https://yq.aliyun.com/ziliao/65771 参考: Kafka集群partition replication默认自动分配分析 如何为kafka选择合适的p ...
- 深入剖析kafka架构内部原理
1 概述 Kakfa起初是由LinkedIn公司开发的一个分布式的消息系统,后成为Apache的一部分,它使用Scala编写,以可水平扩展和高吞吐率而被广泛使用.目前越来越多的开源分布式处理系统如Cl ...
- Kafka文件存储机制及offset存取
Kafka是什么 Kafka是最初由Linkedin公司开发,是一个分布式.分区的.多副本的.多订阅者,基于zookeeper协调的分布式日志系统(也可以当做MQ系统),常见可以用于web/nginx ...
- Kafka文件存储机制那些事
Kafka是什么 Kafka是最初由Linkedin公司开发,是一个分布式.分区的.多副本的.多订阅者,基于zookeeper协调的分布式日志系统(也可以当做MQ系统),常见可以用于web/nginx ...
- kafka日志同步至elasticsearch和kibana展示
kafka日志同步至elasticsearch和kibana展示 一 kafka consumer准备 前面的章节进行了分布式job的自动计算的概念讲解以及实践.上次分布式日志说过日志写进kafka, ...
随机推荐
- Codeforces 909 C. Python Indentation (DP+树状数组优化)
题目链接:Python Indentation 题意: Python是没有大括号来标明语句块的,而是用严格的缩进来体现.现在有一种简化版的Python,只有两种语句: (1)'s'语句:Simple ...
- Wannafly挑战赛18B 随机数
Wannafly挑战赛18B 随机数 设\(f_i\)表示生成\(i\)个数有奇数个1的概率. 那么显而易见的递推式:\(f_i=p(1-f_{i-1})+(1-p)f_{i-1}=(1-2p)f_{ ...
- BZOJ3601. 一个人的数论(狄利克雷卷积+高斯消元)及关于「前 $n$ 个正整数的 $k$ 次幂之和是关于 $n$ 的 $k+1$ 次多项式」的证明
题目链接 https://www.lydsy.com/JudgeOnline/problem.php?id=3601 题解 首先还是基本的推式子: \[\begin{aligned}f_d(n) &a ...
- python之进程池与线程池
一.进程池与线程池介绍 池子使用来限制并发的任务数目,限制我们的计算机在一个自己可承受的范围内去并发地执行任务 当并发的任务数远远超过了计算机的承受能力时,即无法一次性开启过多的进程数或线程数时就应该 ...
- 在使用Reference Source调试.Net 源代码时如何取消optimizations(代码优化)-翻译
在使用PDB调试XAF时,发现好多变量都看不到.都被优化掉了. 下面的方法可以解决. 当你在使用Reference Source functionality in VS 2008 调试.Net 的源代 ...
- 高大上网站-CSS3总结1-图片2D处理以及BUG修复
高大上网站-CSS3总结1-图片2D处理以及BUG修复 一,前言: 现在的前端UI相对JS来说,重视并不够. 但是CSS3提供的新特性,将现在的网站赤裸裸的划分为两类:一类还在写着老旧样式,或者通过b ...
- OpenCV中图像以Mat类型保存时各通道数据在内存中的组织形式及python代码访问各通道数据的简要方式
以最简单的4 x 5三通道图像为例,其在内存中Mat类型的数据组织形式如下: 每一行的每一列像素的三个通道数据组成一个一维数组,一行像素组成一个二维数组,整幅图像组成一个三维数组,即: Mat.dat ...
- 苏州地区--校招IT公司
完整经历了苏州的秋招和春招,在本校和苏州大学跑了许多次的宣讲会,自认为对苏州IT企业的校招有一个充分的认知.原本打算在苏州找一份Java开发的工作,可是发现自己简历连那些公司的简历关都过不去(对双非学 ...
- 如何判断Map中的key或value是什么类型
在上班写工具类时,遇到了一个问题,将xml文件的节点都放入map容器中时,map的value也是一个map,导致取map的value时,需要判断这个value的数据类型,用到了一下说的这些知识: 对于 ...
- Nginx内置的嵌入变量
Nginx核心模块ngx_http_core_module自带有许多内置嵌入的变量,这些变量方便我们配置和使用nginx,在nginx的配置文件中我们可以以$开头直接使用这些变量,这些变量表示客户端请 ...