用 TensorFlow 实现 SVM 分类问题
这篇文章解释了底部链接的代码。
问题描述
 

如上图所示,有一些点位于单位正方形内,并做好了标记。要求找到一条线,作为分类的标准。这些点的数据在 inearly_separable_data.csv 文件内。
思路
最初的 SVM 可以形式化为如下:
\[\begin{equation}\min_{\boldsymbol{\omega,b}}\frac{1}{2}\|\boldsymbol{\omega}\|^2\\s.t.\ y_i(\boldsymbol{\omega}^T\boldsymbol{x}_i+b)\geqslant 1,\ i = 1,2,\cdots ,m.\end{equation} \]
引入软间隔,可以在一定情况下避免过拟合的问题。
引入软间隔之后,问题转化为
\[\begin{equation}
\min_{\boldsymbol{\omega,b}}\frac{1}{2}\|\boldsymbol{\omega}\|^2 + C \sum_{i=1}^{N}max(0,1-y_i(\boldsymbol{\omega}^T\boldsymbol{x}_i+b))
\end{equation}\]
代码
主要代码在 linear_svm.py 内,plot_boundary_on_data.py 负责画图。
一、引入库和声明
import tensorflow as tf
import numpy as np
import scipy.io as io
from matplotlib import pyplot as plt
import plot_boundary_on_data
二、 定义一些变量
# Global variables.
BATCH_SIZE = 100 # The number of training examples to use per training step.
# Define the flags useable from the command line.
tf.app.flags.DEFINE_string('train', None,
'File containing the training data (labels & features).')
tf.app.flags.DEFINE_integer('num_epochs', 1,
'Number of training epochs.')
tf.app.flags.DEFINE_float('svmC', 1,
'The C parameter of the SVM cost function.')
tf.app.flags.DEFINE_boolean('verbose', False, 'Produce verbose output.')
tf.app.flags.DEFINE_boolean('plot', True, 'Plot the final decision boundary on the data.')
FLAGS = tf.app.flags.FLAGS
包括每次训练使用的数据,称为一个 batch,大小定义为 BATCH_SIZE。
train 是训练集文件的位置,这里是 inearly_separable_data.csv。
num_epochs 是把所有训练集的数据使用几遍。把训练集的数据使用一遍称为一个 epoch。
svmC 即\((2)\)式中 \(C\)的大小。
三、读取训练数据
# Extract it into numpy matrices.
train_data,train_labels = extract_data(train_data_filename)
# Convert labels to +1,-1
train_labels[train_labels==0] = -1
# Get the shape of the training data.
train_size,num_features = train_data.shape
读出来的 train_data 是一个 [1000, 2] 的张量,样本的有两个属性,train_labels 是一个 [1000, 1] 的张量。
在读取过程中用到了 numpy 的接口。
标准的 SVM 的标记为 \(\{-1, 1\}\),而文件中标记为 \(\{0, 1\}\)。因此需要做一次转换。
四、构造网络结构
x = tf.placeholder("float", shape=[None, num_features])
y = tf.placeholder("float", shape=[None,1])
W = tf.Variable(tf.zeros([num_features,1]))
b = tf.Variable(tf.zeros([1]))
y_raw = tf.matmul(x,W) + b
线性方程的最终表现形式是 \(\boldsymbol{\omega}^t\boldsymbol{x}+b=0\)。
给定一个样本数据 \(\boldsymbol{x}\),若 \(\boldsymbol{\omega}^t\boldsymbol{x}+b \geqslant 1\),则认为对应的分类为 1,然后和样本的标记对比,若标记为1,则分类正确;否则,分类错误。
若 \(\boldsymbol{\omega}^t\boldsymbol{x}+b \leqslant 1\),则认为对应的分类为 -1,然后和样本的标记对比,若标记为-1,则分类正确;否则,分类错误。
最终要求解的值是一个 shape 为 [2, 1] 的张量 \(W\) 和一个标量 \(b\)。
y_raw 是向量机判定的输出。
五、构造优化目标
regularization_loss = 0.5*tf.reduce_sum(tf.square(W))
hinge_loss = tf.reduce_sum(tf.maximum(tf.zeros([BATCH_SIZE,1]),
1 - y*y_raw));
svm_loss = regularization_loss + svmC*hinge_loss;
train_step = tf.train.GradientDescentOptimizer(0.01).minimize(svm_loss)
即 \( \min_{\boldsymbol{\omega,b}}\frac{1}{2}\|\boldsymbol{\omega}\|^2 + C \sum_{i=1}^{N}max(0,1-y_i(\boldsymbol{\omega}^T\boldsymbol{x}_i+b))\) 的代码表示。
指定用梯度下降法最小化 svm_loss。
六、用精度来评价模型的好坏
predicted_class = tf.sign(y_raw);
correct_prediction = tf.equal(y,predicted_class)
accuracy = tf.reduce_mean(tf.cast(correct_prediction, "float"))
如果 y_raw和样本的标记 y 同符号,即认为预测正确。用预测正确的比例来评价模型的好坏。
七、用数据训练模型
with tf.Session() as s:
# Run all the initializers to prepare the trainable parameters.
tf.initialize_all_variables().run()
# Iterate and train.
for step in xrange(num_epochs * train_size // BATCH_SIZE):
offset = (step * BATCH_SIZE) % train_size
batch_data = train_data[offset:(offset + BATCH_SIZE), :]
batch_labels = train_labels[offset:(offset + BATCH_SIZE)]
train_step.run(feed_dict={x: batch_data, y: batch_labels})
print 'loss: ', svm_loss.eval(feed_dict={x: batch_data, y: batch_labels})
首先启动一个 session,每次取 BATCH_SIZE 个数据来训练模型。即用batch_data 和 batch_lables来训练一次,每次得到一个 svm_loss 的值。
运行结果
python linear_svm.py --train linearly_separable_data.csv --svmC 1 --verbose True --num_epochs 10
运行以上命令,指定把数据使用10轮,一次使用100个数据,因此可以得到100次迭代的结果。最后得到的结果及精度如下:
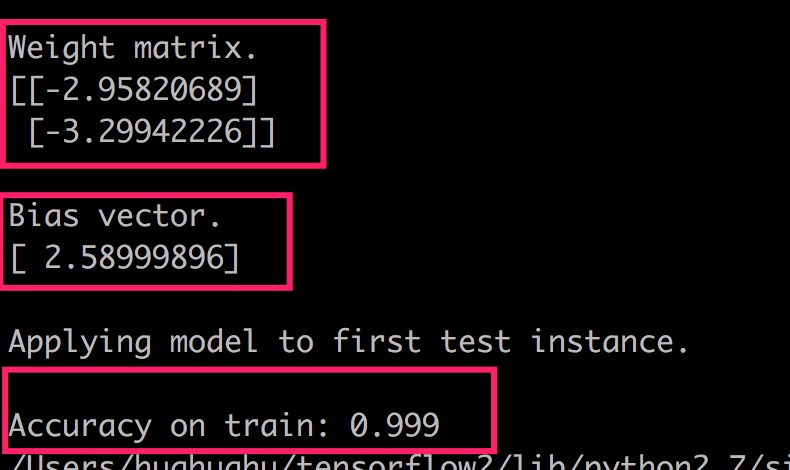 

思考
- 指定
BATCH_SIZE和num_epochs是为了减少计算量。
根据数学理论,应该在整个训练数据集上进行梯度下降法的迭代,每一步迭代都应该选取所有训练数据集的样本。但是这样子做计算量太大,于是在每一次迭代时选用训练数据集的一部分作为输入。
这么做要求每一步迭代选取的数据子集的分布和总体分布一致,否则得不到正确的结果。
参考
用 TensorFlow 实现 SVM 分类问题的更多相关文章
- SVM原理以及Tensorflow 实现SVM分类(附代码)
1.1. SVM介绍 1.2. 工作原理 1.2.1. 几何间隔和函数间隔 1.2.2. 最大化间隔 - 1.2.2.0.0.1. \(L( {x}^*)\)对$ {x}^*$求导为0 - 1.2.2 ...
- Relation Extraction中SVM分类样例unbalance data问题解决 -松弛变量与惩罚因子
转载自:http://blog.csdn.net/yangliuy/article/details/8152390 1.问题描述 做关系抽取就是要从产品评论中抽取出描述产品特征项的target短语以及 ...
- SVM-支持向量机(二)非线性SVM分类
非线性SVM分类 尽管SVM分类器非常高效,并且在很多场景下都非常实用.但是很多数据集并不是可以线性可分的.一个处理非线性数据集的方法是增加更多的特征,例如多项式特征.在某些情况下,这样可以让数据集变 ...
- SVM-支持向量机(一)线性SVM分类
SVM-支持向量机 SVM(Support Vector Machine)-支持向量机,是一个功能非常强大的机器学习模型,可以处理线性与非线性的分类.回归,甚至是异常检测.它也是机器学习中非常热门的算 ...
- tensorflow实现svm iris二分类——本质上在使用梯度下降法求解线性回归(loss是定制的而已)
iris二分类 # Linear Support Vector Machine: Soft Margin # ---------------------------------- # # This f ...
- tensorflow实现svm多分类 iris 3分类——本质上在使用梯度下降法求解线性回归(loss是定制的而已)
# Multi-class (Nonlinear) SVM Example # # This function wll illustrate how to # implement the gaussi ...
- 用tensorflow实现SVM
环境配置 win10 Python 3.6 tensorflow1.15 scipy matplotlib (运行时可能会遇到module tkinter的问题) sklearn 一个基于Python ...
- SVM分类与回归
SVM(支撑向量机模型)是二(多)分类问题中经常使用的方法,思想比较简单,但是具体实现与求解细节对工程人员来说比较复杂,如需了解SVM的入门知识和中级进阶可点此下载.本文从应用的角度出发,使用Libs ...
- VQ结合SVM分类方法
今天整理资料时,发现了在学校时做的这个实验,当时整个过程过重偏向依赖分类器方面,而又很难对分类器性能进行一定程度的改良,所以最后没有选用这个方案,估计以后也不会接触这类机器学习的东西了,希望它对刚入门 ...
随机推荐
- 创建cookie
cookie的创建using System;using System.Collections.Generic;using System.Linq;using System.Web;using Syst ...
- HTML5 APP应用实现图片上传及拍照上传功能
https://blog.csdn.net/zmzwll1314/article/details/46965663 http://www.cnblogs.com/leo0705/ https://zh ...
- 2018.10.01 NOIP模拟 购买书籍(贪心+STL)
传送门 一道有意思的贪心. 感觉使用了网络流推流反悔的思想. 考虑维护三个setsetset维护a[i]−b[i],b[i]a[i]-b[i],b[i]a[i]−b[i],b[i]和a[i]a[i]a ...
- mysql 查询表 的所有字段名称
select COLUMN_NAME from information_schema.COLUMNS where table_name = 'your_table_name' and table_sc ...
- angularjs写公共方法
'use strict'; angular.module('fast-westone') .factory('commonUtilService', function () { return { /* ...
- 怎么备份VMware虚拟磁盘文件或移植到其他虚拟机
原文:http://jingyan.baidu.com/article/a681b0de17b3173b1843468f.html 方法/步骤 第一种方法:直接复制本地主机磁盘下的虚拟磁盘文件 ...
- HDU 2058 The sum problem (数学+暴力)
题意:给定一个N和M,N表示从1到N的连续序列,让你求在1到N这个序列中连续子序列的和为M的子序列区间. 析:很明显最直接的方法就是暴力,可是不幸的是,由于N,M太大了,肯定会TLE的.所以我们就想能 ...
- Java多线程-并发协作(生产者消费者模型)
对于多线程程序来说,不管任何编程语言,生产者和消费者模型都是最经典的.就像学习每一门编程语言一样,Hello World!都是最经典的例子. 实际上,准确说应该是“生产者-消费者-仓储”模型,离开了仓 ...
- 《Android开发艺术探索》第11章 Android的线程和线程池
第11章 Android的线程和线程池 11.1 主线程和子线程 (1)在Java中默认情况下一个进程只有一个线程,也就是主线程,其他线程都是子线程,也叫工作线程.Android中的主线程主要处理和界 ...
- node 命令行
问题起源于,想用node执行命令行的命令. 结论如下:两种情况 1.node本身的命令(node app.js):使用child_process模块的四个方法 2.命令行的命令(包括1,还有java) ...