如何用python解析mysqldump文件
一、前言
最近在做离线数据导入HBase项目,涉及将存储在Mysql中的历史数据通过bulkload的方式导入HBase。由于源数据已经不在DB中,而是以文件形式存储在机器磁盘,此文件是mysqldump导出的格式。如何将mysqldump格式的文件转换成实际的数据文件提供给bulkload作转换,是需要考虑的一个问题。
二、思路
我们知道mysqldump导出的文件主要是Insert,数据库表结构定义语句。而要解析的对象也主要是包含INSERT关键字记录,这样我们就把问题转换成如何从dmp文件解析Insert语句。接触过dmp文件的同学应该了解,其INSERT语句的结构,主要包含表名、字段名、字段值, 这里面主要包含几个关键字:INSERT INTO, VALUES。我们要做的就是把Values括号后的字段值给解析出来,这个过程需要考虑VALUES后面包含的是多少行的记录,有可能导出的记录Values后面包含多行对应mysql中存储的记录。
在解析文件过程中,我自然想到用Python来写,因为Python在处理文件方面有很多优势,也比较简单。在处理DMP文件这块,考虑到字段值间是用逗号分割的,在python中正好一个模块可以很好的来处理此类格式 ,即大家很熟悉的CSV模块,在处理CSV类型的文件有很多优势。在这里我们把CSV模块有在解析dmp文件,同时加一些解析逻辑,可以很好解决此类问题。
同时,我们要处理的dmp文件是经过压缩的,并且单个文件都比较大,都是Gigbytes的,在读取时需要注意机器内存大小,不能一次读出所有的数据,python也考虑到此类问题,采用的方法是惰性取值,即在真正使用时才从磁盘中加载相应的文件数据。如果想加块解析,还可以采集多进程或多线程的方法。
三、方法
处理流程图如下所示:
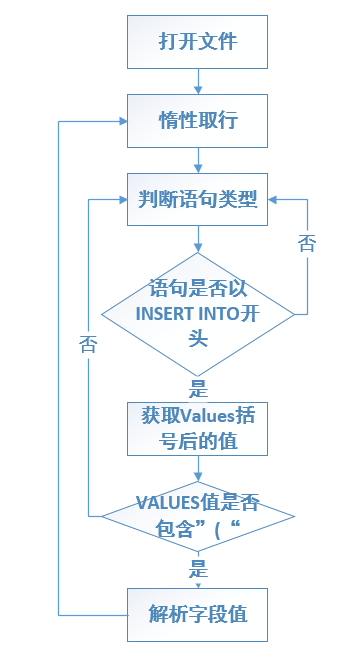
代码如下图所示:
#!/usr/bin/env python
import fileinput
import csv
import sys
import gzip # 设定CSV读取的最大容量
csv.field_size_limit(sys.maxsize) def check_insert(line):
"""
返回语句是否以insert into开头,如果是返回true,否则返回false
"""
return line.startswith('INSERT INTO') or False def get_line_values(line):
"""
返回Insert语句中包含Values的部分
"""
return line.partition('VALUES ')[2] def check_values_style(values):
"""
保证INSERT语句满足基本的条件,即包含(右括号
""" if values and values[0] == '(':
return True
return False def parse_line(values):
"""
创建csv对象,读取INSERT VALUES 字段值
"""
latest_row = [] reader = csv.reader([values], delimiter=',',
doublequote=False,
escapechar='\\',
quotechar="'",
strict=True
) for reader_row in reader:
for column in reader_row:
# 判断字段值是否为空或为NULL
if len(column) == 0 or column == 'NULL':
latest_row.append("")
continue # 判断字段开头是否以(开头,如果是则说明此VALUES后面不只包含一行数据,可能有多行,要分别解析
if column[0] == "(":
new_row = False
if len(latest_row) > 0:
#判断行是否包含),如果包含则说明一行数据完毕
if latest_row[-1][-1] == ")":
# 移除)
latest_row[-1] = latest_row[-1][:-1]
if latest_row[-1] == "NULL":
latest_row[-1] = ""
new_row = True
# 如果是新行,则打印该行
if new_row:
line="}}}{{{".join(latest_row)
print "%s<{||}>" % line
latest_row = [] if len(latest_row) == 0:
column = column[1:] latest_row.append(column)
# 判断行结束符
if latest_row[-1][-2:] == ");":
latest_row[-1] = latest_row[-1][:-2]
if latest_row[-1] == "NULL":
latest_row[-1] = "" line="}}}{{{".join(latest_row)
print "%s<{||}>" % line def main(): filename=sys.argv[1]
try:
#惰性取行
with gzip.open(filename,"rb") as f:
for line in f:
if check_insert(line):
values = get_line_values(line)
if check_values_style(values):
parse_line(values)
except KeyboardInterrupt:
sys.exit(0) if __name__ == "__main__":
main()
四、总结
总的说来,主要是利用Python的CSV模块来解析DMP文件的INSERT语句,如果DMP文件不规整,可能还是有些问题。对于dmp文件很大情况,也是需要考虑解析时间效率问题,可以考虑增加多进程或多线程机制。
如何用python解析mysqldump文件的更多相关文章
- Python解析Wav文件并绘制波形的方法
资源下载 #本文PDF版下载 Python解析Wav文件并绘制波形的方法 #本文代码下载 Wav波形绘图代码 #本文实例音频文件night.wav下载 音频文件下载 (石进-夜的钢琴曲) 前言 在现在 ...
- Python解析excel文件并存入sqlite数据库
最近由于工作上的需求 需要使用Python解析excel文件并存入sqlite 就此做个总结 功能:1.数据库设计 建立数据库2.Python解析excel文件3.Python读取文件名并解析4.将解 ...
- python解析ini文件
python解析ini文件 使用configparser - Configuration file parser sections() add_section(section) has_section ...
- 如何用Python判断一个文件是否被占用?
本文的文字及图片来源于网络,仅供学习.交流使用,不具有任何商业用途,如有问题请及时联系我们以作处理 今天有同学问,用os模块的access()能否判断一个文件是否被占用?直觉上,这是行不通的,因为ac ...
- python 解析xml 文件: Element Tree 方式
环境 python:3.4.4 准备xml文件 首先新建一个xml文件,countries.xml.内容是在python官网上看到的. <?xml version="1.0" ...
- python 解析xml 文件: DOM 方式
环境 python:3.4.4 准备xml文件 首先新建一个xml文件,countries.xml.内容是在python官网上看到的. <?xml version="1.0" ...
- python 解析xml 文件: SAX方式
环境 python:3.4.4 准备xml文件 首先新建一个xml文件,countries.xml.内容是在python官网上看到的. <?xml version="1.0" ...
- 遍历文件 创建XML对象 方法 python解析XML文件 提取坐标计存入文件
XML文件??? xml即可扩展标记语言,它可以用来标记数据.定义数据类型,是一种允许用户对自己的标记语言进行定义的源语言. 里面的标签都是可以随心所欲的按照他的命名规则来定义的,文件名为roi.xm ...
- Python解析HDF文件 分类: Python 2015-06-25 00:16 743人阅读 评论(0) 收藏
前段时间因为一个业务的需求需要解析一个HDF格式的文件.在这之前也不知道到底什么是HDF文件.百度百科的解释如下: HDF是用于存储和分发科学数据的一种自我描述.多对象文件格式.HDF是由美国国家超级 ...
随机推荐
- C++ STL之LIST详解A
List 容器 list是C++标准模版库(STL,Standard Template Library)中的部分内容.实际上,list容器就是一个双向链表,可以高效地进行插入删除元素. 使用list容 ...
- Codeforces Round #552 (Div. 3) 题解
Codeforces Round #552 (Div. 3) 题目链接 A. Restoring Three Numbers 给出 \(a+b\),\(b+c\),\(a+c\) 以及 \(a+b+c ...
- 关于javaweb中图片的存储问题
图片上传到服务器,然后把上传路径保存到数据库,然后从数据库读出保存的路径显示到网站页面. 我们一般可以在CMS系统中将图片添加到图片服务器中(这个可以使用ftp来部署),然后图片上传到服务器后,在数据 ...
- 什么是Docker并且它为什么这么受欢迎
什么是Docker (why it's so hot than hot) Docker是一个使用容器来方便快捷的创建,部署,运行程序的工具,容器允许开发人员将应用程序的一切打包(镜像),例如库和其他的 ...
- UDP_TCP示意图
- idea插件安装的通用操作
序:今天下午看到一个bug,很神奇,粘出来大家看看 看到这个异常栈,有经验的或者查到的答案都是mapper.xml中哪个的方法配置错了,应替换parameterMap为parameterType, 奇 ...
- 织梦自定义表单通过ajax提交的实现方法
自定义表单通过ajax判断,提交不用跳转页面,提高用户体验.具体方法如下: html表单代码部分,就提交按钮改成botton,,添加onclick事件 表单代码: <form action=&q ...
- Nginx+tomcat 负载均衡
一.系统版本 Nginx使用版本.tomcat使用版本: Nginx:nginx-1.10.2.tar.gz Java :Java version: 1.8.0_60, vendor: Oracl ...
- 微信小程序开发教程(七)逻辑层——.js详解
逻辑层,是事务逻辑处理的地方.对于小程序而言,逻辑层就是.js脚本文件的集合.逻辑层将数据进行处理后发送给视图层,同时接收视图层的事件反馈. 微信小程序开发框架的逻辑层是由JavaScript编写.在 ...
- 安装Win8引起Ubuntu启动项丢失的恢复过程
画电路图的时候手痒,于是将之前做好的Win8PE拿出来装着玩儿.至于Win8的pE很好做,用UltraISO将Win8 的镜像用制作硬盘镜像的方法烧进U盘就行了. Win8的安装过程也很简单.安装前为 ...