gj6 深入python的set和dict
6.1 collections中的abc
from collections.abc import Mapping, MutableMapping
#dict属于mapping类型 a = {}
print (isinstance(a, MutableMapping))
# True
6.2 dict的常见用法
a = {"lewen1": {"company": "imooc"},
"lewen2": {"company": "imooc2"}
}
# clear Remove all items from D.
# a.clear()
# pass
# copy, 返回浅拷贝
new_dict = a.copy()
new_dict["lewen1"]["company"] = "imooc3" # 浅拷贝,只是拷贝了指向。这里修改会修改了a 中原来的值
print(new_dict)
print(a)
---
{'lewen1': {'company': 'imooc3'}, 'lewen2': {'company': 'imooc2'}}
{'lewen1': {'company': 'imooc3'}, 'lewen2': {'company': 'imooc2'}}
---
import copy
a = {"lewen1": {"company": "imooc"},
"lewen2": {"company": "imooc2"}
}
new_dict = copy.deepcopy(a) # 深拷贝,开辟独立的内存空间,并复制值
new_dict["lewen1"]["company"] = "imooc3" # 这里修改,并不会影响字典a的值
print(new_dict)
print(a)
---
{'lewen1': {'company': 'imooc3'}, 'lewen2': {'company': 'imooc2'}}
{'lewen1': {'company': 'imooc'}, 'lewen2': {'company': 'imooc2'}}
---
# formkeys
new_list = ["lewen1", "lewen2"]
new_dict = dict.fromkeys(new_list, {"company": "imooc"})
print(new_dict)
# new_dict["kevin"] # KeyError 不存在会抛异常
ret = new_dict.get("kevin","None") #
print(ret)
# items 方法
for key,value in new_dict.items():
print(key,value) ret_set = new_dict.setdefault("kevin","new mem") # 不存在key,就设置并返回值
print(ret_set)
print(new_dict)
new_dict.update( # update() 括号里面添加为可迭代对象
(("lewen", "imooc"),)
)
---
{'lewen1': {'company': 'imooc'}, 'lewen2': {'company': 'imooc'}}
None
lewen1 {'company': 'imooc'}
lewen2 {'company': 'imooc'}
new mem
{'lewen1': {'company': 'imooc'}, 'lewen2': {'company': 'imooc'}, 'kevin': 'new mem'}
6.3 dict的子类
#不建议继承list和dict
class Mydict(dict):
def __setitem__(self, key, value):
super().__setitem__(key, value*2) my_dict = Mydict(one=1) # value*2 没有生效
# my_dict["one"] = 1 # 生效了
print (my_dict)
{'one': 1}
---
from collections import UserDict
class Mydict(UserDict):
def __setitem__(self, key, value):
super().__setitem__(key, value*2) my_dict = Mydict(one=1)
# my_dict["one"] = 1
print (my_dict)
{'one': 2}
---
# defaultdict
from collections import defaultdict
my_dict = defaultdict(dict)
my_value = my_dict["bobby"] # 没有则返回空字典
print(my_value)
{}
6.4 set和frozenset
#set 集合 fronzenset (不可变集合) 无序, 不重复
s = set('abcdee')
print(s) s2 = set(['a','b','c','d','e'])
print(s2) s3 = {'a','b', 'c'}
print(type(s3)) s = frozenset("abcde") #frozenset 不可变,以作为dict的key
# 不能添加值
print(s)
# ---
{'a', 'e', 'c', 'd', 'b'}
{'a', 'e', 'c', 'd', 'b'}
<class 'set'>
frozenset({'a', 'e', 'c', 'd', 'b'})
# ---
#向set添加数据
s = set('abcdee')
another_set = set("cef")
s.update(another_set)
print(s) re_set = s.difference(another_set) # {'b', 'd', 'a'}
re_set = s - another_set # {'b', 'd', 'a'}
re_set = s & another_set # {'c', 'f', 'e'}
re_set = s | another_set # {'a', 'f', 'c', 'e', 'd', 'b'} #set性能很高
# | & - #集合运算
print(re_set) print (s.issubset(re_set))
if "c" in re_set:
print ("i am in set")
# ---
{'a', 'f', 'e', 'c', 'd', 'b'}
{'a', 'f', 'c', 'e', 'd', 'b'}
True
i am in set
6.5 dict和set实现原理
from random import randint def load_list_data(total_nums, target_nums):
"""
从文件中读取数据,以list的方式返回
:param total_nums: 读取的数量
:param target_nums: 需要查询的数据的数量
"""
all_data = []
target_data = []
file_name = "D:\电子书\Python面试宝典Version8.1.pdf"
with open(file_name, encoding="utf8", mode="r") as f_open:
for count, line in enumerate(f_open):
if count < total_nums:
all_data.append(line)
else:
break for x in range(target_nums):
random_index = randint(0, total_nums)
if all_data[random_index] not in target_data:
target_data.append(all_data[random_index])
if len(target_data) == target_nums:
break return all_data, target_data def load_dict_data(total_nums, target_nums):
"""
从文件中读取数据,以dict的方式返回
:param total_nums: 读取的数量
:param target_nums: 需要查询的数据的数量
"""
all_data = {}
target_data = []
file_name = "D:\电子书\Python面试宝典Version8.1.pdf"
with open(file_name, encoding="utf8", mode="r") as f_open:
for count, line in enumerate(f_open):
if count < total_nums:
all_data[line] = 0
else:
break
all_data_list = list(all_data)
for x in range(target_nums):
random_index = randint(0, total_nums-1)
if all_data_list[random_index] not in target_data:
target_data.append(all_data_list[random_index])
if len(target_data) == target_nums:
break return all_data, target_data def find_test(all_data, target_data):
#测试运行时间
test_times = 100
total_times = 0
import time
for i in range(test_times):
find = 0
start_time = time.time()
for data in target_data:
if data in all_data:
find += 1
last_time = time.time() - start_time
total_times += last_time
return total_times/test_times if __name__ == "__main__":
# all_data, target_data = load_list_data(10000, 1000)
# all_data, target_data = load_list_data(100000, 1000)
# all_data, target_data = load_list_data(1000000, 1000) # all_data, target_data = load_dict_data(10000, 1000)
# all_data, target_data = load_dict_data(100000, 1000)
# all_data, target_data = load_dict_data(1000000, 1000)
all_data, target_data = load_dict_data(2000000, 1000)
last_time = find_test(all_data, target_data)
view
#dict查找的性能远远大于list
#在list中随着list数据的增大 查找时间会增大
#在dict中查找元素不会随着dict的增大而增大
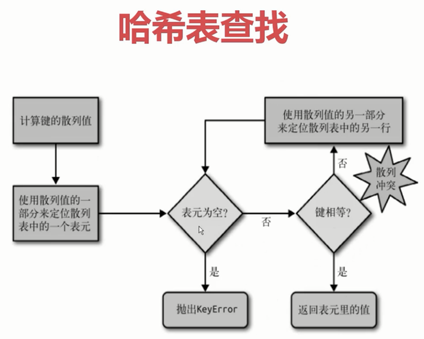
print(last_time) #1.dict的key或者set的值 都必须是可以hash的
#不可变对象 都是可hash的, str, fronzenset, tuple,自己实现的类 __hash__
#2. dict的内存花销大(有大量空余的表元),但是查询速度快, 自定义的对象 或者python内部的对象都是用dict包装的
# 3. dict的存储顺序和元素添加顺序有关
# 4. 添加数据有可能改变已有数据的顺序
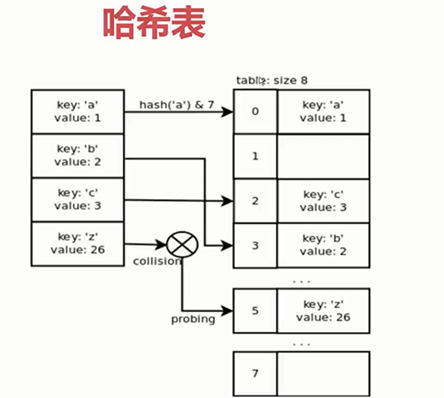
哈希冲突后重新计算位置
在剩余空间小于三分之一时,申请更大的空间,然后数据搬迁,有可能会改变顺序
gj6 深入python的set和dict的更多相关文章
- python基础之字典dict和集合set
作者:tongqingliu 转载请注明出处:http://www.cnblogs.com/liutongqing/p/7043642.html python基础之字典dict和集合set 字典dic ...
- python入门14 字典dict
字典dict是无序的key:value格式的数据序列 #coding:utf-8 #/usr/bin/python """ 2018-11-11 dinghanhua 字 ...
- Python基础——字典(dict)
由键-值对构建的集合. 创建 dic1={} type(dic1) dic2=dict() type(dic2) 初始化 dic2={'hello':123,'world':456,'python': ...
- 05-深入python的set和dict
一.深入python的set和dict 1.1.dict的abc继承关系 from collections.abc import Mapping,MutableMapping #dict属于mappi ...
- python何时用list,dict,set
从读取的角度来讲: 看是用来随机读取(查询)还是连续读取. list数组集中存放,连续读取效率高(具体还没测试,理论上应该如此). dict散列表,使用hash计算存放的位置,随机读取效率高. 随机读 ...
- Python中list,tuple,dict,set的区别和用法
Python语言简洁明了,可以用较少的代码实现同样的功能.这其中Python的四个内置数据类型功不可没,他们即是list, tuple, dict, set.这里对他们进行一个简明的总结. List ...
- python日常-list and dict
什么是list: list 觉得算是python日常编程中用的最多的python自带的数据结构了.但是python重的list跟其他语言中的并不相同. 少年..不知道你听说过python中的appen ...
- Python~list,tuple^_^dict,set
tuple~(小括号) list~[中括号] 和list比较,dict有以下几个特点: dict~{‘key’:value,} set~set([1,2,3]) tuple一旦初始化就不能修改~指向不 ...
- Python之什么是dict
我们已经知道,list 和 tuple 可以用来表示顺序集合,例如,班里同学的名字: ['Adam', 'Lisa', 'Bart'] 或者考试的成绩列表: [95, 85, 59] 但是,要根据名字 ...
随机推荐
- Mysql 主- 开启binlog
https://www.cnblogs.com/martinzhang/p/3454358.html my.cnf 添加 log_bin=mysql-bin 开启日志,然后重启mysql服务器. 查看 ...
- Optimizing graphics performance
看U3D文档,心得:对于3D场景,使用分层次的距离裁剪,小物件分到一个层,稍远时就被裁掉,大物体分到一个层,距离很远时才裁掉,甚至不载.中物体介于二者之间. 文档如下: Good performanc ...
- neo4j 学习-2
Neo4j 查询例句 MATCH (john {name: 'John'})-[:friend]->()-[:friend]->(fof) RETURN john.name, fof.na ...
- Mysql InnoDB 数据更新 锁表
一.数据表结构 1 2 3 4 5 6 7 8 9 10 CREATE TABLE `jx_attach` ( `attach_id` int(11) NOT NULL AUTO_INCREMEN ...
- Linux下启动Tomcat启动并显示控制台日志信息
Linux下如何启动Tomcat像Windows启动并显示控制台日志信息一样? Windows下启动tomcat,一般直接运行startup.bat,启动后如下图所示: Linux下直接启动./sta ...
- 第八章 高级搜索树 (b2)B-树:结构
- 在UNITY中按钮的高亮用POINT灯实现,效果别具一番风味
在UNITY中按钮的高亮用POINT灯实现,效果别具一番风味
- 基于AspectJ的XML方式进行AOP开发
-------------------siwuxie095 基于 AspectJ 的 XML 方式进行 AOP 开发 1 ...
- 转 Appium for Mac 环境准备篇
转发地址:http://www.cnblogs.com/oscarxie/p/3894559.html 1. 爬墙因为后续安装过程中可能会碰到墙的问题,所以首先得解决爬墙的问题.我的方便,公司提供代理 ...
- OC 里面 webView与js
webView与js的交互流程吗,iOS端暴露函数 ,js直接调用 [链接]WKWebView-如何通过JS调用OC方法 https://www.jianshu.com/p/68f799d6679e ...