大数据入门第二天——基础部分之zookeeper(上)
一、概述
1.是什么?
根据凡技术必登其官网的原则,我们先去官网瞅一瞅:http://zookeeper.apache.org/
Apache ZooKeeper is an effort to develop and maintain an open-source server which enables highly reliable distributed coordination
分布式:一个业务分拆多个子业务,部署在不同的服务器上
集群:同一个业务,部署在多个服务器上
形象的说:
作者:张鹏飞
链接:https://www.zhihu.com/question/20004877/answer/112124929
来源:知乎
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
Zookeeper是一个分布式协调服务;就是为用户的分布式应用程序提供协调服务
A、zookeeper是为别的分布式程序服务的
B、Zookeeper本身就是一个分布式程序(只要有半数以上节点存活,zk就能正常服务)
C、Zookeeper所提供的服务涵盖:主从协调、服务器节点动态上下线、统一配置管理、分布式共享锁、统一名称服务……
D、虽然说可以提供各种服务,但是zookeeper在底层其实只提供了两个功能:
管理(存储,读取)用户程序提交的数据;
并为用户程序提供数据节点监听服务;
更多的深入浅出的介绍,参考:https://www.cnblogs.com/wuxl360/p/5817471.html
zookeeper的W3C教程,参考:https://www.w3cschool.cn/zookeeper/zookeeper_overview.html
选举重点清晰讲解,参考:http://blog.csdn.net/gaoshan12345678910/article/details/67638657
2.集群中的角色
Zookeeper集群的角色: Leader 和 follower (Observer)
只要集群中有半数以上节点存活,集群就能提供服务
二、安装
以下请使用hadoop用户!并配置hosts安装为好!
###zk有相关的可视化工具,详情参考IDEA插件章节篇
通过克隆复制好3台机器后,使用rz命令先上传文件
(安装前提需要有JDK)
解压:
tar -zxvf zookeeper-3.4..tar.gz -C /opt/zookeeper
配置环境变量:
sudo vi /etc/profile
export ZOOKEEPER_HOME=/opt/zookeeper/zookeeper-3.4.
export PATH=$PATH:$ZOOKEEPER_HOME/bin
生效环境变量:
source /etc/profile
以上配环境步骤3台机器均需要更改!
修改配置文件:
cd zookeeper-3.4.5/conf
cp zoo_sample.cfg zoo.cfg
vim zoo.cfg
增加以下内容:
dataDir=/opt/zookeeper/zookeeper-3.4./data
dataLogDir=/opt/zookeeper/zookeeper-3.4./log
#主机名:心跳端口:数据端口
server.=192.168.137.128::
server.=192.168.137.138::
server.=192.168.137.148::
创建文件夹:
cd /opt/zookeeper/zookeeper-3.4.
mkdir -m data
mkdir -m log
创建myid:
cd data
vim myid
myid内容:
1
下发集群到其他机器上:
scp -r /opt/zookeeper/zookeeper-3.4. root@192.168.137.138:/opt/zookeeper/
scp -r /opt/zookeeper/zookeeper-3.4. root@192.168.137.148:/opt/zookeeper/
其实应当使用hadoop用户,并配置hosts,换成如下命令:
scp -r zookeeper-3.4./ mini2:/home/hadoop/apps/
到两台机器上分别修改myid为2 3
启动机器:
zkServer.sh start
查看状态:
zkServer.sh status
出现报错请关闭防火墙重试!
三、命令行客户端的使用
1.命令行客户端

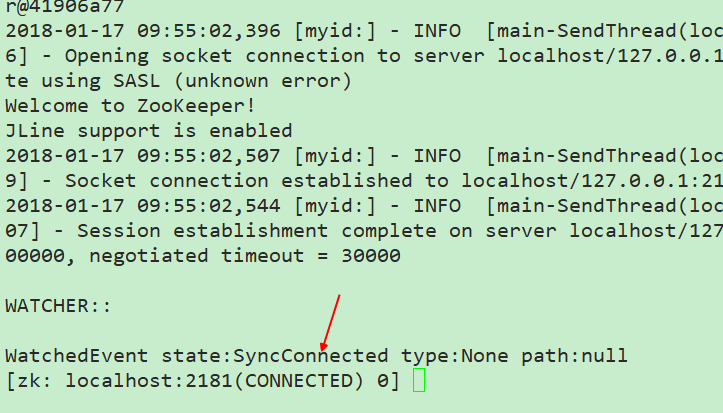
可以看到连接上了自己这一台
打开帮助信息,可以 看到如果想要连接其他的服务器,可以使用-server host:port的形式,或者在当前使用connect host:port的形式
[zk: localhost:(CONNECTED) ] help
ZooKeeper -server host:port cmd args
stat path [watch]
set path data [version]
ls path [watch]
delquota [-n|-b] path
ls2 path [watch]
setAcl path acl
setquota -n|-b val path
history
redo cmdno
printwatches on|off
delete path [version]
sync path
listquota path
rmr path
get path [watch]
create [-s] [-e] path data acl
addauth scheme auth
quit
getAcl path
close
connect host:port
切换服务器:
[zk: localhost:2181(CONNECTED) 0] connect 192.168.137.138:2181
这样就切换过来了:

2.zookeeper的数据的结构
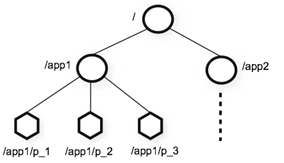
、层次化的目录结构,命名符合常规文件系统规范(见下图)
、每个节点在zookeeper中叫做znode,并且其有一个唯一的路径标识
、节点Znode可以包含数据和子节点(但是EPHEMERAL类型的节点不能有子节点,下一页详细讲解)
、客户端应用可以在节点上设置监视器(后续详细讲解)
如图所示:
节点类型:
、Znode有两种类型:
短暂(ephemeral)(断开连接自己删除)
持久(persistent)(断开连接不删除)
、Znode有四种形式的目录节点(默认是persistent )
PERSISTENT
PERSISTENT_SEQUENTIAL(持久序列/test0000000019 )
EPHEMERAL
EPHEMERAL_SEQUENTIAL
、创建znode时设置顺序标识,znode名称后会附加一个值,顺序号是一个单调递增的计数器,由父节点维护
、在分布式系统中,顺序号可以被用于为所有的事件进行全局排序,这样客户端可以通过顺序号推断事件的顺序
3.客户端操作
基本上操作可以在help列出的命令中查看
1.查看
[zk: 192.168.137.138:(CONNECTED) ] ls /
[zookeeper]
//可以看到只有一个根节点
2.创建znode
-e参数:短暂节点
-s节点:是否带序号(SEQUENTIAL)
主要短暂节点下不能有子节点!
[zk: 192.168.137.138:(CONNECTED) ] create /app1 "this is app1"
Created /app1
[zk: 192.168.137.138:(CONNECTED) ] ls /
[zookeeper, app1]
//可以看到这里创建了一个示例的字符串节点,由于默认是持久节点,如果需要创建短暂节点,请使用-e参数!
创建带序号的znode:
[zk: 192.168.137.138:(CONNECTED) ] create /test
Created /test
[zk: 192.168.137.138:(CONNECTED) ] create -s /test/aaa
Created /test/aaa0000000000
[zk: 192.168.137.138:(CONNECTED) ] create -s /test/aaa
Created /test/aaa0000000001
//可以看到节点自动带了编号,所以即使重名也是允许的!当然只在次目录从0开始标序号,切换目录创建带序号的将会重新从0开始
当然,/app1还可以有子节点
[zk: 192.168.137.138:(CONNECTED) ] create /app1/server01 "192.168.137.138,100"
Created /app1/server01
3.查看znode数据
[zk: 192.168.137.138:(CONNECTED) ] ls /app1
[server01]
[zk: 192.168.137.138:(CONNECTED) ] get /app1
"this
cZxid = 0x100000008
ctime = Wed Jan :: CST
mZxid = 0x100000008
mtime = Wed Jan :: CST
pZxid = 0x100000009
cversion =
dataVersion =
aclVersion =
ephemeralOwner = 0x0
dataLength =
numChildren =
//可以看到它这里直接以空格就给分割了,不直接把引号内容当作数据;当然,我们写Java API的时候肯定是不会以空格就分断的,这仅仅是客户端的问题
4.修改znode数据
修改的数据在各个节点之间基本上是实时同步的!
[zk: 192.168.137.138:(CONNECTED) ] set /app1 yyy
cZxid = 0x100000008
ctime = Wed Jan :: CST
mZxid = 0x10000000d
mtime = Wed Jan :: CST
pZxid = 0x100000009
cversion =
dataVersion =
aclVersion =
ephemeralOwner = 0x0
dataLength =
numChildren =
5.删除znode
znode 删除(只能删除没有子节点的)
[zk: 202.115.36.251:(CONNECTED) ] delete /zk
删除节点:rmr(整个节点和子节点全部删除)
[zk: 202.115.36.251:(CONNECTED) ] rmr /zk
更多增删改查的实例,参考:https://www.cnblogs.com/sherrykid/p/5813148.html
6.监听
其他机器发生修改了,本机立马可以收到通知!
其中get监听是监听内容的变化(子节点变化不会影响)
使用ls /app1 watch时,再创建子节点就会有监听了!
[zk: 192.168.137.138:(CONNECTED) ] get /app1 watch
yyy
cZxid = 0x100000008
ctime = Wed Jan :: CST
mZxid = 0x10000000d
mtime = Wed Jan :: CST
pZxid = 0x100000009
cversion =
dataVersion =
aclVersion =
ephemeralOwner = 0x0
dataLength =
numChildren =
[zk: 192.168.137.138:(CONNECTED) ]
WATCHER:: WatchedEvent state:SyncConnected type:NodeDataChanged path:/app1
更多znode详解,参考:http://blog.csdn.net/lihao21/article/details/51810395
大数据入门第二天——基础部分之zookeeper(上)的更多相关文章
- 大数据入门第二天——基础部分之zookeeper(下)
一.集群自启动脚本 1.关闭zk [root@localhost bin]# jps Jps QuorumPeerMain [root@localhost bin]# //kill或者stop都是可以 ...
- 大数据入门第一天——基础部分之Linux基础(环境准备与先导知识)
一.Linux环境安装 1.VM的安装 参考Linux环境搭建随笔:http://www.cnblogs.com/jiangbei/p/7248054.html 2.CentOS的安装 同参考上述随笔 ...
- 大数据入门第二十二天——spark(一)入门与安装
一.概述 1.什么是spark 从官网http://spark.apache.org/可以得知: Apache Spark™ is a fast and general engine for larg ...
- 大数据入门第二十五天——elasticsearch入门
一.概述 推荐路神的ES权威指南翻译:https://es.xiaoleilu.com/010_Intro/00_README.html 官网:https://www.elastic.co/cn/pr ...
- 大数据入门第二十二天——spark(二)RDD算子(1)
一.RDD概述 1.什么是RDD RDD(Resilient Distributed Dataset)叫做分布式数据集,是Spark中最基本的数据抽象,它代表一个不可变.可分区.里面的元素可并行计算的 ...
- 大数据入门第二十五天——logstash入门
一.概述 1.logstash是什么 根据官网介绍: Logstash 是开源的服务器端数据处理管道,能够同时 从多个来源采集数据.转换数据,然后将数据发送到您最喜欢的 “存储库” 中.(我们的存储库 ...
- 大数据入门第二十四天——SparkStreaming(一)入门与示例
一.概述 1.什么是spark streaming Spark Streaming is an extension of the core Spark API that enables scalabl ...
- 大数据入门第二十二天——spark(三)自定义分区、排序与查找
一.自定义分区 1.概述 默认的是Hash的分区策略,这点和Hadoop是类似的,具体的分区介绍,参见:https://blog.csdn.net/high2011/article/details/6 ...
- 大数据入门第二十四天——SparkStreaming(二)与flume、kafka整合
前一篇中数据源采用的是从一个socket中拿数据,有点属于“旁门左道”,正经的是从kafka等消息队列中拿数据! 主要支持的source,由官网得知如下: 获取数据的形式包括推送push和拉取pull ...
随机推荐
- windows下php使用zerophp
官网地址:http://zeromq.org/ 下载windows版本安装(不过php可以不用安装,直接使用扩展包就可以了) 然后下载php的zmq扩展包:https://pecl.php.net/p ...
- Oracle 数据库执行慢SQL
) hou, - ))) mini, c.sql_address, c.inst_id,f.full_name,u.user_name, b.user_concurrent_program_name, ...
- Oracle EBS 取总账期间
--取期间 select GPS.EFFECTIVE_PERIOD_NUM, GPS.PERIOD_NAME from GL_PERIOD_STATUSES GPS AND (GPS.SET_OF_B ...
- 【gp数据库】OLTP和OLAP区别详解
原来一直使用Oracle,新公司使用greenplum后发现系统的并发性差很多,后来才了解因为Oracle属于OLTP类型,而gp数据库属于OLAP类型的.具体了解如下: 数据库系统一般分为两种类型, ...
- SpringMVC框架项目在编译运行是常见错误
1.问题描述(Spring_shizhan4ban_Chapter05应用):在自动注入FileValidator对象引用类型时报错,由于FileValidator是实体类,没有实现接口. @Auto ...
- 逆向分析-IDA动态调试WanaCrypt0r的wcry.exe程序
0x00 前言 2017年5月12日全球爆发大规模蠕虫勒索软件WanaCrypt0r感染事件,各大厂商对该软件做了深入分析,但针对初学者的分析教程还比较少,复现过程需要解决的问题有很多,而且没有文章具 ...
- nodejs API(一)
不要注重版本 URL 官网所在位置:https://nodejs.org/dist/latest-v8.x/docs/api/url.html URL网址解析的好帮手: url有三个可调用的方法:ur ...
- ZT 计算一个无符整数中1Bit的个数(1) 2010-04-20 10:52:48
计算一个无符整数中1Bit的个数(1) 2010-04-20 10:52:48 分类: C/C++ [转]计算一个无符整数中1Bit的个数(1) Count the number of bits ...
- jprofiler9.2注册码
jprofiler9.2注册码 2016-08-23 18:11 3658人阅读 评论(2) 收藏 举报 L-Larry_Lau@163.com#23874-hrwpdp1sh1wrn#0620 L- ...
- 2668: [cqoi2012]交换棋子
Description 有一个n行m列的黑白棋盘,你每次可以交换两个相邻格子(相邻是指有公共边或公共顶点)中的棋子,最终达到目标状态.要求第i行第j列的格子只能参与mi,j次交换. Input 第一行 ...