Scrapy命令行工具简介
Windows 10家庭中文版,Python 3.6.4,virtualenv 16.0.0,Scrapy 1.5.0,
在最初使用Scrapy时,使用编辑器或IDE手动编写模块来创建爬虫(Spider)程序,然后使用scrapy crawl命令执行Spider。
这种方式很初级、繁琐,不适合更大型的项目。
很好的是,Scrapy提供了 命令行工具(Command line tool),通过这套工具,开发者可以轻松建立 Scrapy项目,而不仅仅是一个一个的Spider程序。
初见Scrapy命令行工具
先说几个使用过的Scrapy命令行工具中的命令:
-scrapy startproject
创建一个新的爬虫项目,语法如下:
scrapy startproject <project_name> [project_dir]
-scrapy genspider
在当前目录下创建一个爬虫程序(重名了会怎样?待试验),语法如下:
scrapy genspider [-t template] <name> <domain>
其中,template可以为basic、crawl、csvfeed、xmlfeed,默认是basic,其它三个尚未用过。
爬虫程序的name需要是一个合法的Python标识符(说法不太准确,需要更正),domain是需要爬取的网址的域名,会出现在爬虫的allowed_domains属性中,还会影响到爬虫的start_urls属性。
注意:domain中不能有http://、https://,仅仅是域名,不包含协议部分(犯过错误)。
疑问:domain是否可以设置多个呢?(需验证)
下面是第一次创建Spider时犯错了:

下图的start_urls中以两个http://开头!
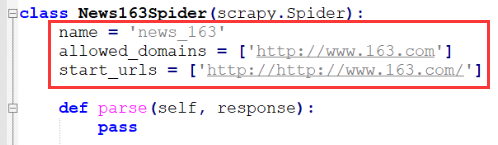
执行爬虫程序时发生DNSLookupError!
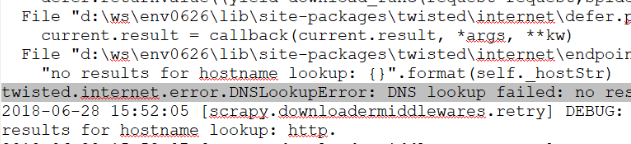
注意,默认是给domain添加http://,那么,https网站还得手动更改?
更正代码后——删除allowed_domains和start_urls中多余的http://,爬虫程序可以正常执行。
-scrapy runspider
在没有使用scrapy startproject之前,自己写一个爬虫程序——没有项目的概念,此时,使用runspider命令来执行,因此,此命令时全局的(Global)。
语法如下:参数是 Python文件
scrapy runspider <spider_file.py>
-scrapy crawl
在创建的Scrapy项目中执行爬虫程序,依托于项目,此命令并非全局的。
语法如下:参数是 爬虫项目 内的 爬虫的 name,即在genspider时使用的name。
scrapy crawl <spider>
之前还会把runspider和crawl搞混,现在不会了。
----
上面就是几个自己常用的命令,本文后面会对其它命令进行简单介绍。
Scrapy命令行工具运行机制
Scrapy命令行工具运行时,会寻找一个配置文件,此文件命名为scrapy.cfg。在使用startproject建立爬虫项目时,此文件出现在爬虫项目的根目录下。
不过,scrapy.cfg不仅仅会出现在这里,见官文的截图(不再赘述):

对于1,但孤的Windows系统没有c:scrapy目录,更没有下面的scrapy.cfg了,需要自己建立吗?
对于2,也没有在用户根目下发现.scrapy.cfg文件;
看来,只有3——Scrapy项目的根目录下的scrapy.cfg是有效的了。
除了配置文件外,Scrapy命令行工具还可以下面三个环境变量配合使用:
-SCRAPY_SETTINGS_MODULE
-SCRAPY_PROJECT
-SCRAPY_PYTHON_SHELL
默认是打开标准的Python控制台(配置值为python,),可以将其配置为ipython(Scrapy推荐)、bpython,代表其它两个Python版本。
scrapy项目的默认结果如下(截图自官文的Tutorial文档):
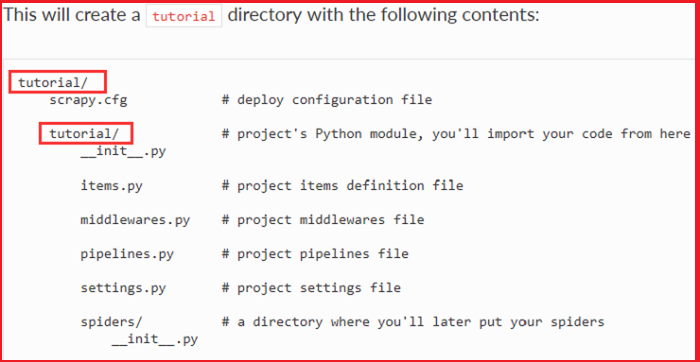
其中,scrapy.cfg文件的内容格式如下:
[settings]
default = myproject.settings
上面的myproject表示项目名称,在上图的tutorial项目中,其为tutorial。这句表示,配置默认是tutorial目录下的settings.py文件的配置(请参考官文Settings)。
scrapy命令行工具用法
-直接输入scrapy 或 输入scrapy -h,显示scrapy的用法信息;
-输入scrayp <command> -h,显示子命令的用法信息;
-命令分为两种:项目命令(Project-specific commands)、全局命令(Global commands),前者只能在Scrapy项目中使用(有效),后者无论在哪里使用都有效。需要注意的是,某些命令在项目外执行和项目里面执行时是有区别的,比如,全局命令fetch,(省略若干字,还没弄清楚,请参考官网先)。
-全局命令 如下
startproject, genspider, settings, runspider, shell, fetch, view, version
-项目命令 如下
crawl, check, list, edit, parse, bench
更多Scrapy命令介绍
全局命令
-settings
获取Scrapy的配置,语法:
scrapy settings [options]
示例见官文。
-shell
重要!
语法如下:
scrapy shell [url]
基于参数url打开一个Scrapy shell,如果没有url参数,直接打开一个Scrapy shell。
也支持UNIX风格的本地文件路径,但是,相对路径必须用 ./或../ 开头,或者使用绝对路径,只是文件名是不行的。
开发者可以使用Scrapy shell来验证自己抓取数据的规则是否正确,熟练使用后,可以更高效进行Scrapy项目开发。
没有使用url打开后的示例:
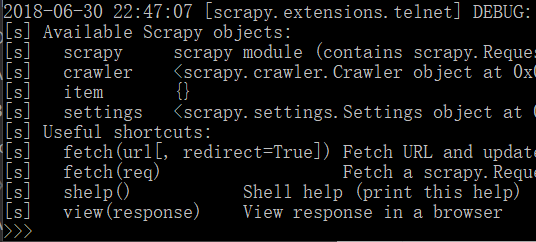
-fetch
未使用过。语法如下:
scrapy fetch <url>
使用Scrapy下载器下载给定的url并把内容写到标准输出。
可以通过配置项指定爬虫程序。
更多消息见官文。
-view
用浏览器打开给定的链接。
-version
查看Scrapy版本,加-v查看Python、twisted和平台相关信息。
项目命令
-check
重要!
和Scrapy项目的测试有关!
需要深入学习!
尚未使用过,请参考官文Spiders Contracts。
0703-1124更新:
今天看了官文Spiders Contracts,这个命令用于方便地测试爬虫程序。
在爬虫程序的docstring中定义好contracts后,就可以使用check命令对contracts中规则进行检查了。
默认有三个contracts,开发者也可以定制开发。
-list
显示当前Scrapy项目可用的 爬虫。
-edit
编辑指定的爬虫程序。
经过测试,在Windows上未能打开IDLE,和孤是在virtualenv中操作有关系吗?
Linux上是用vi打开(vim?)。
-parse
未使用过。语法如下:
scrapy parse <url> [options]
获取给定的URL,并用处理它的spider(--callback或-c指定解析函数)解析它的响应。
此函数有很多配置项,请查阅官文。
07-02更新:
刚刚在官文Debugging Spiders中看到了parse的使用示例,调试的时候用。
在scrapy parse命令中使用--spider指定爬虫程序、-c指定解析程序、-d指定爬取深度,可以逐层展现指定爬虫、指定解析程序的数据爬取结果。
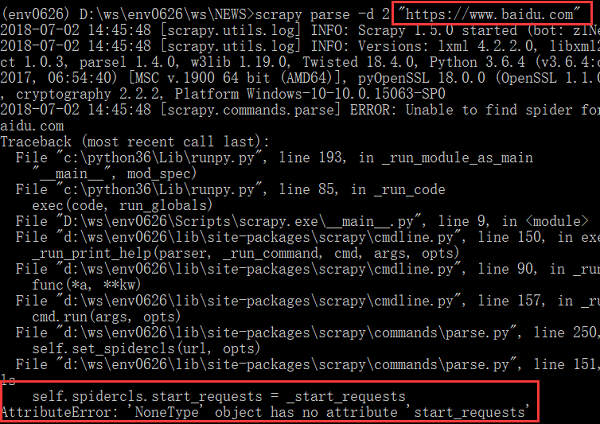
测试发现,其对一些https开头的网页爬取失败了,比如,https://www.baidu.com(还测试了https://docs.scrapy.org,也失败了):
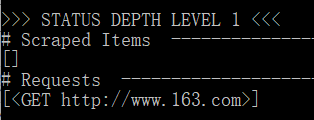
网易首页是HTTP的,没有使用--spider、-c、-d选项,执行结果如下:Scraped Items是爬取结果,Requests是请求(一个GET请求)。
-bench
运行一个benchmark,官文Benchmarking,还没用过,
上面标记了“重要”的都需要达到【精通】的级别,当然,更需要熟悉CSS选择器和XPath。
定制项目命令
看清楚,是定制 项目命令!
全局命令就固定那几个了,但开发者可以定制项目命令,可以很久很久都不会用到吧,不再深入介绍。
后记
还有不少命令的用法不是很熟悉,还需要更加多地实践和理解;
-版本1.0:2018-06-30 22:56
写完后感觉好多命令不是很熟悉啊!还得多练习。后面更熟练了,再进行补充。
目前认为两个命令最重要:shell、check。
其实,这篇文章写的有些乱,因为自己不是精通Scrapy命令行工具吧!日后真的需要完善才行!
当然,孤以为文中还是提供了一些初级的、有价值的信息的。
Scrapy命令行工具简介的更多相关文章
- openssl命令行工具简介 - 指令x509
原文链接: http://blog.csdn.net/allwtg/article/details/4982507 openssl命令行工具简介 - 指令x509 用法: open ...
- Python -- Scrapy 命令行工具(command line tools)
结合scrapy 官方文档,进行学习,并整理了部分自己学习实践的内容 Scrapy是通过 scrapy 命令行工具进行控制的. 这里我们称之为 “Scrapy tool” 以用来和子命令进行区分. 对 ...
- 使用Scrapy命令行工具【导出JSON文件】时编码设置
Windows 10家庭中文版,Python 3.6.4,virtualenv 16.0.0,Scrapy 1.5.0, 使用scrapy命令行工具建立了爬虫项目(startproject),并使用s ...
- 二、Scrapy命令行工具
本文转载自以下链接:https://scrapy-chs.readthedocs.io/zh_CN/latest/topics/commands.html Scrapy是通过 scrapy 命令行工具 ...
- openssl命令行工具简介 - RSA操作
原文链接: http://www.cnblogs.com/aLittleBitCool/archive/2011/09/22/2185418.html 首先介绍下命令台下openssl工具的简单使用: ...
- Scrapy学习篇(二)之常用命令行工具
简介 Scrapy是通过Scrapy命令行工具进行控制的,包括创建新的项目,爬虫的启动,相关的设置,Scrapy提供了两种内置的命令,分别是全局命令和项目命令,顾名思义,全局命令就是在任意位置都可以执 ...
- Scrapy 1.4 文档 05 命令行工具
在系统命令行中,使用 scrapy 命令可以创建工程或启动爬虫,它控制着 Scrapy 的行为,我们称之为 Scrapy 命令行工具(command-line tool)或 Scrapy 工具(Scr ...
- 爬虫:Scrapy2 - 命令行工具
Scrapy 是通过 scrapy 命令行工具进行控制的. 这里我们称之为 “Scrapy tool” 以用来和子命令进行区分.对于子命令,我们称为 “command” 或者 “Scrapy comm ...
- Scrapy系列教程(1)------命令行工具
默认的Scrapy项目结构 在開始对命令行工具以及子命令的探索前,让我们首先了解一下Scrapy的项目的文件夹结构. 尽管能够被改动,但全部的Scrapy项目默认有类似于下边的文件结构: scrapy ...
随机推荐
- 学习Spring Boot:(四)应用日志
前言 应用日志是一个系统非常重要的一部分,后来不管是开发还是线上,日志都起到至关重要的作用.这次使用的是 Logback 日志框架. 正文 Spring Boot在所有内部日志中使用Commons L ...
- 【模板】网络流-最大流模板(Dinic)
#include <cstdio> #include <cstring> #include <algorithm> #include <queue> u ...
- 【bzoj2733】 HNOI2012—永无乡
http://www.lydsy.com/JudgeOnline/problem.php?id=2733 (题目链接) 题意 给出图上$n$个点,每个点有一个点权,每次询问一个连通块中点权第$K$小的 ...
- 网络对抗课题4.3.1 SQL注入原理与实践
网络对抗课题4.3.1 SQL注入原理与实践 原理 SQL注入漏洞是指在Web应用对后台数据库查询语句处理存在的安全漏洞.也就是,在输入字符串中嵌入SQL指令,在设计程序中忽略对可能构成攻击的特殊字符 ...
- linux 第三周读书笔记-----第一二章 20135334赵阳林
第一章 Linux内核简介 1.1 Unix的历史 由于Unix系统设计简洁并且在发布时提供源代码,所以许多其他组织和团体都对它进了进一步的开发. Unⅸ虽然已经使用了40年,但计算机科学家仍然认为它 ...
- php版本的code review软件
phabricator, http://www.oschina.net/p/phabricator
- php高效遍历文件夹、高效读取文件
/** * PHP高效遍历文件夹(大量文件不会卡死) * @param string $path 目录路径 * @param integer $level 目录深度 */ function fn_sc ...
- Luogu 1063 能量项链(动态规划)
Luogu 1063 能量项链(动态规划) Description 在Mars星球上,每个Mars人都随身佩带着一串能量项链.在项链上有N颗能量珠.能量珠是一颗有头标记与尾标记的珠子,这些标记对应着某 ...
- linux命令总结之查找命令find、locate、whereis、which、type
我们经常需要在系统中查找一个文件,那么在Linux系统中我们如何准确高效的确定一个文件在系统中的具体位置呢?一下我总结了在linux系统中用于查找文件的几个命令. 1.find命令 find是最常用也 ...
- unity解析json的两种方式
一直比较钟情于json,用来做数据交互,堪称完美!下面简单说一下unity使用C#脚本如何解析json数据吧. 一.写解析类,借助于JsonUtility.FromJson 直接给个例子吧 1.jso ...