学习笔记—MapReduce
MapReduce是什么
MapReduce是一种分布式计算编程框架,是Hadoop主要组成部分之一,可以让用户专注于编写核心逻辑代码,最后以高可靠、高容错的方式在大型集群上并行处理大量数据。
MapReduce的存储
MapReduce的数据是存储在HDFS上的,HDFS也是Hadoop的主要组成部分之一。下边是MapReduce在HDFS上的存储的图解
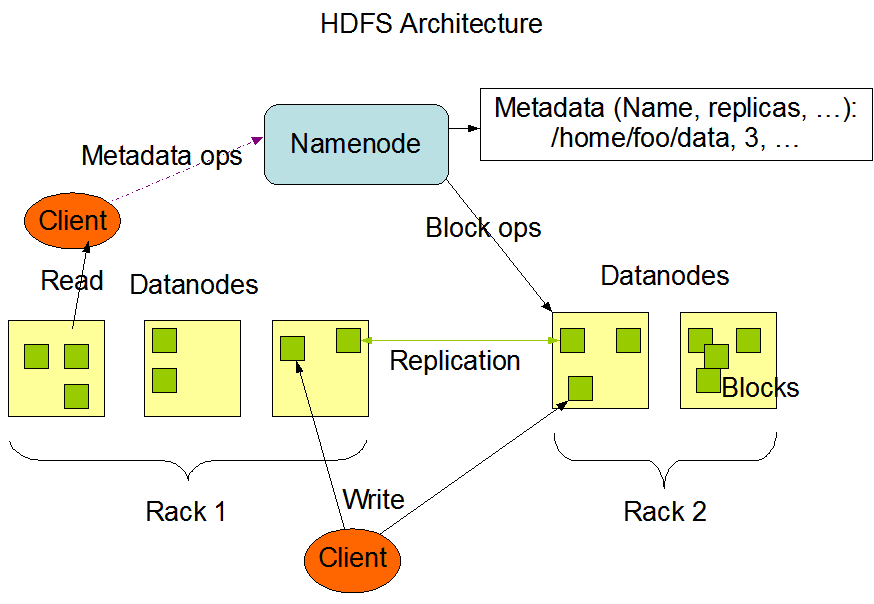
HDFS主要有Namenode和Datanode两部分组成,整个集群有一个Namenode和多个DataNode,通常每一个节点一个DataNode,Namenode的主要功能是用来管理客户端client对数据文件的操作请求和储存数据文件的地址。DataNode主要是用来储存和管理本节点的数据文件。节点内部数据文件被分为一个或多个block块(block默认大小原来是64MB,后来变为128MB),然后这些块储存在一组DataNode中。(这里不对HDFS做过多的介绍,后续会写一篇详细的HDFS笔记)
MapReduce的运行流程


1、首先把需要处理的数据文件上传到HDFS上,然后这些数据会被分为好多个小的分片,然后每个分片对应一个map任务,推荐情况下分片的大小等于block块的大小。然后map的计算结果会暂存到一个内存缓冲区内,该缓冲区默认为100M,等缓存的数据达到一个阈值的时候,默认情况下是80%,然后会在磁盘创建一个文件,开始向文件里边写入数据。
2、map任务的输入数据的格式是<key,value>对的形式,我们也可以自定义自己的<key,value>类型。然后map在往内存缓冲区里写入数据的时候会根据key进行排序,同样溢写到磁盘的文件里的数据也是排好序的,最后map任务结束的时候可能会产生多个数据文件,然后把这些数据文件再根据归并排序合并成一个大的文件。
3、然后每个分片都会经过map任务后产生一个排好序的文件,同样文件的格式也是<key,value>对的形式,然后通过对key进行hash的方式把数据分配到不同的reduce里边去,这样对每个分片的数据进行hash,再把每个分片分配过来的数据进行合并,合并过程中也是不断进行排序的。最后数据经过reduce任务的处理就产生了最后的输出。
4、在我们开发中只需要对中间map和reduce的逻辑进行开发就可以了,中间分片,排序,合并,分配都有MapReduce框架帮我完成了。
MapReduce的资源调度系统
最后我们来看一下MapReduce的资源调度系统Yarn。
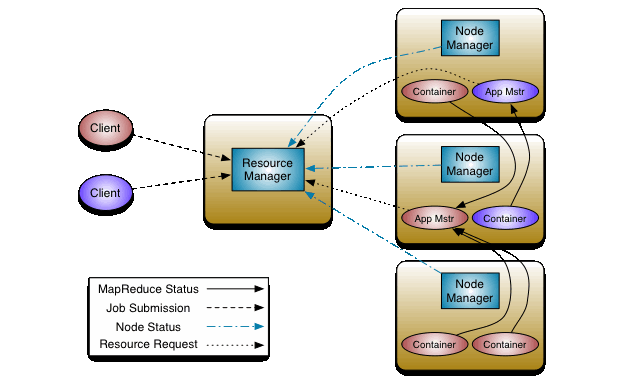
Yarn的基本思想是将资源管理和作业调度/监视的功能分解为单独的守护进程。全局唯一的ResourceManager是负责所有应用程序之间的资源的调度和分配,每个程序有一个ApplicationMaster,ApplicationMaster实际上是一个特定于框架的库,其任务是协调来自ResourceManager的资源,并与NodeManager一起执行和监视任务。NodeManager是每台机器框架代理,监视其资源使用情况(CPU,内存,磁盘,网络)并将其报告给ResourceManager。
WordConut代码
- python实现
map.py
#!/usr/bin/env python
# -*- coding:UTF-8 -*-
import sys
for line in sys.stdin:
words = line.strip().split()
for word in words:
print('%s\t%s' % (word, 1))
reduce.py
#!/usr/bin/env python
# -*- coding:UTF-8 -*-
import sys
current_word = None
sum = 0
for line in sys.stdin:
word, count = line.strip().split(' ')
if current_word == None:
current_word = word
if word != current_word:
print('%s\t%s' % (current_word, sum))
current_word = word
sum = 0
sum += int(count)
print('%s\t%s' % (current_word, sum))
我们先把输入文件上传到HDFS上去
hadoop fs -put /input.txt /
然后在Linux下运行,为了方便我们把命令写成了shell文件
HADOOP_CMD="/usr/local/src/hadoop-2.6.1/bin/hadoop"
STREAM_JAR_PATH="/usr/local/src/hadoop-2.6.1/share/hadoop/tools/lib/hadoop-streaming-2.6.1.jar"
INPUT_FILE_PATH="/input.txt"
OUTPUT_FILE_PATH="/output"
$HADOOP_CMD fs -rmr -skipTrush $OUTPUT_FILE_PATH
$HADOOP_CMD jar $STREAM_JAR_PATH \
-input $INPUT_FILE_PATH \
-output $OUTPUT_FILE_PATH \
-mapper "python map.py" \
-reducer "python reduce.py" \
-file "./map.py" \
-file "./reduce.py"
- java实现
MyMap.java
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
import java.io.IOException;
public class MyMap extends Mapper<LongWritable, Text, Text, IntWritable> {
private IntWritable one = new IntWritable(1);
private Text text = new Text();
@Override
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
String line = value.toString();
String[] words = line.split(" ");
for (String word: words){
text.set(word);
context.write(text,one);
}
}
}
MyReduce.java
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer;
import java.io.IOException;
public class MyReduce extends Reducer<Text, IntWritable, Text, IntWritable> {
private IntWritable result = new IntWritable();
@Override
protected void reduce(Text key, Iterable<IntWritable> values, Context context) throws IOException, InterruptedException {
int sum = 0;
for (IntWritable i:values){
sum+=i.get();
}
result.set(sum);
context.write(key,result);
}
}
WordCount.java
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
public class WordCount {
public static void main(String[] args) throws Exception {
Configuration configuration = new Configuration();
Job job = Job.getInstance(configuration, "WordCount");
job.setJarByClass(WordCount.class);
job.setMapperClass(MyMap.class);
job.setReducerClass(MyReduce.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
FileInputFormat.addInputPath(job, new Path(args[0]));
FileOutputFormat.setOutputPath(job, new Path(args[1]));
System.exit(job.waitForCompletion(true) ? 0 : 1);
}
}
把工程打成jar包,然后把jar包和输入文件上传到HDfs
$ hadoop fs -put /wordcount.jar /
$ hadoop fs -put /input.txt /
执行wordcount任务
$ bin/hadoop jar wordcount.jar WordCount /input.txt /user/joe/wordcount/output
欢迎关注公众号:「努力给自己看」

学习笔记—MapReduce的更多相关文章
- Hadoop学习笔记—MapReduce的理解
我不喜欢照搬书上的东西,我觉得那样写个blog没多大意义,不如直接把那本书那一页告诉大家,来得省事.我喜欢将我自己的理解.所以我会说说我对于Hadoop对大量数据进行处理的理解.如果有理解不对欢迎批评 ...
- Hadoop学习笔记—22.Hadoop2.x环境搭建与配置
自从2015年花了2个多月时间把Hadoop1.x的学习教程学习了一遍,对Hadoop这个神奇的小象有了一个初步的了解,还对每次学习的内容进行了总结,也形成了我的一个博文系列<Hadoop学习笔 ...
- Hadoop学习笔记—18.Sqoop框架学习
一.Sqoop基础:连接关系型数据库与Hadoop的桥梁 1.1 Sqoop的基本概念 Hadoop正成为企业用于大数据分析的最热门选择,但想将你的数据移植过去并不容易.Apache Sqoop正在加 ...
- MongoDB学习笔记~环境搭建
回到目录 Redis学习笔记已经告一段落,Redis仓储也已经实现了,对于key/value结构的redis我更愿意使用它来实现数据集的缓存机制,而对于结构灵活,查询效率高的时候使用redis就有点不 ...
- spark学习笔记总结-spark入门资料精化
Spark学习笔记 Spark简介 spark 可以很容易和yarn结合,直接调用HDFS.Hbase上面的数据,和hadoop结合.配置很容易. spark发展迅猛,框架比hadoop更加灵活实用. ...
- Hadoop入门学习笔记---part1
随着毕业设计的进行,大学四年正式进入尾声.任你玩四年的大学的最后一次作业最后在激烈的选题中尘埃落定.无论选择了怎样的选题,无论最后的结果是怎样的,对于大学里面的这最后一份作业,也希望自己能够尽心尽力, ...
- 学习笔记:The Log(我所读过的最好的一篇分布式技术文章)
前言 这是一篇学习笔记. 学习的材料来自Jay Kreps的一篇讲Log的博文. 原文很长,但是我坚持看完了,收获颇多,也深深为Jay哥的技术能力.架构能力和对于分布式系统的理解之深刻所折服.同时也因 ...
- Hadoop学习笔记(7) ——高级编程
Hadoop学习笔记(7) ——高级编程 从前面的学习中,我们了解到了MapReduce整个过程需要经过以下几个步骤: 1.输入(input):将输入数据分成一个个split,并将split进一步拆成 ...
- Hadoop学习笔记(6) ——重新认识Hadoop
Hadoop学习笔记(6) ——重新认识Hadoop 之前,我们把hadoop从下载包部署到编写了helloworld,看到了结果.现是得开始稍微更深入地了解hadoop了. Hadoop包含了两大功 ...
随机推荐
- java 内存分析之static
源码: 内存分析: 源码: 静态方法: 用static 声明的方法为静态方法,在调用该方法时,不会将对象的引用传递给它,所以在static 方法中不可访问非static 的成员. 可以通过对象 ...
- 【Python】Java程序员学习Python(八)— 基本类型的基本运算
这一篇待写,毕竟基本运算都是通用的.
- webstorm忽略node_modules目录
我在使用了cnpm后node_modules之前的层级目录变成了同一级目录,所以目录很多,造成webstorm读取时卡死. 网上大家列了各种方法,在这里我归纳一下! 先给大家看看一些相关链接. 方法1 ...
- zabbix系列之五——安装后配置一
https://www.zabbix.com/documentation/3.4/manual/appliance Configuration 1Hosts and host groups Overv ...
- Oracle EBS AR 删除应收发票
DECLARE -- Non-scalar parameters require additional processing p_errors arp_trx_validate.mess ...
- springMVC入门-08
这一讲介绍用户登录实现以及两种异常处理controller控制器的方法,最后提一下在springMVC中对静态资源访问的实现方法. 用户登录需要一个登录页面login.jsp,对应代码如下所示: &l ...
- UITabBar设置详解
UITabBar设置详解 效果图 说明 1. 设置tabBarItem中的图片以及标题 2. 设置标题文本样式 3. 修改tabBar背景色 源码 https://github.com/YouXian ...
- IIS 7 反向代理 URL重写 转发动态请求
一.反向代理是什么 有一篇文章说的挺好的 Nginx 反向代理.负载均衡.页面缓存.URL重写及读写分离详解 http://www.server110.com/nginx/201402/5534.ht ...
- eclipse缓慢了么?
我的eclipse突然变得无比缓慢,javaw.exe的cpu使用率高达85%! 可是我什么也没做啊.项目组的其他同事询问过后,也没有谁修改了eclipse的配置文件(.setting文件夹 .cl ...
- 获取 docker 容器(container)的 ip 地址
获取单个IP docker inspect --format '{{ .NetworkSettings.IPAddress }}' <container-ID> 获取所有容器IP doc ...