Hadoop提交作业流程
一 、需要知道的内容
1.ResourceManager ------>yarn的老大
2.NodeManager ------>yarn的小弟
3.ResourceManager调度器 a.默认调度器------>先进先出FIFO
b.公平调度器------>每个任务都有执行的机会
......
4.心跳机制 ------>NodeManager可通过心跳机制将节点健康状况实时汇报给ResourceManager,而ResourceManager则会 根据每个NodeManager的健康状况适当调整分配的任务数目。当NodeManager认为自己的健康状况“欠 佳”时,可让ResourceManager不再分配任务,待健康状况好转时,再分配新任务。
5.NodeManager子进程------>独立于NodeManager,不在NodeManager内部
二 、Hadoop工作流程:
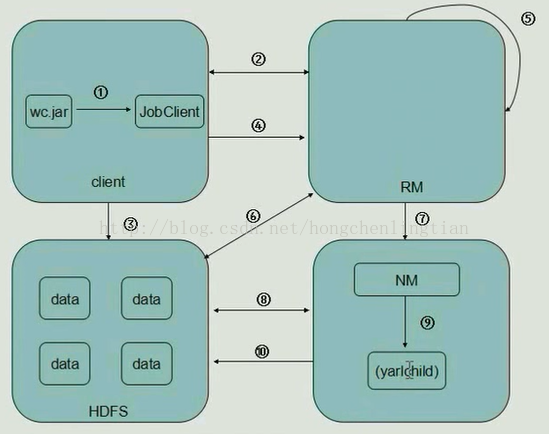
1.Client中,客户端提交一个mr的jar包给JobClient(提交方式:hadoop jar ...)
2.JobClient持有ResourceManager的一个代理对象,它向ResourceManager发送一个RPC请求,告诉ResourceManager作业开始,
然后ResourceManager返回一个JobID和一个存放jar包的路径给Client
3.Client将得到的jar包的路径作为前缀,JobID作为后缀(path = hdfs上的地址 + jobId) 拼接成一个新的hdfs的路径,然后Client通过FileSystem向hdfs中存放jar包,默认存放10份
(NameNode和DateNode等操作)
4.开始提交任务,Client将作业的描述信息(JobID和拼接后的存放jar包的路径等)RPC返回给ResourceManager
5.ResourceManager进行初始化任务,然后放到一个调度器中
6.ResourceManager读取HDFS上的要处理的文件,开始计算输入分片,每一个分片对应一个MapperTask,根据数据量确定起多少个mapper,多少个reducer
7.NodeManager 通过心跳机制向ResourceManager领取任务(任务的描述信息)
8.领取到任务的NodeManager去Hdfs上下载jar包,配置文件等
9.NodeManager启动相应的子进程yarnchild,运行mapreduce,运行maptask或者reducetask
10.map从hdfs中读取数据,然后传给reduce,reduce将输出的数据给回hdfs
---------------------
本文来自 小虹尘 的CSDN 博客 ,全文地址请点击:https://blog.csdn.net/hongchenlingtian/article/details/53524705?utm_source=copy
Hadoop提交作业流程的更多相关文章
- git 提交作业流程
git 提交作业流程,主要分为4个步骤 # 拉取远程git最新版本到本地,每次都可以先执行这条命令,因为会有其他同学更新仓库 git pull # add需要上传的文件,那个文件修改或者新增的,就ad ...
- hadoop提交作业自定义排序和分组
现有数据如下: 3 3 3 2 3 1 2 2 2 1 1 1 要求为: 先按第一列从小到大排序,如果第一列相同,按第二列从小到大排序 如果是hadoop默认的排序方式,只能比较key,也就是第一列, ...
- eclipse 提交作业到JobTracker Hadoop的数据类型要求必须实现Writable接口
问:在eclipse中的写的代码如何提交作业到JobTracker中的哪?答:(1)在eclipse中调用的job.waitForCompletion(true)实际上执行如下方法 connect() ...
- Spark源码系列(一)spark-submit提交作业过程
前言 折腾了很久,终于开始学习Spark的源码了,第一篇我打算讲一下Spark作业的提交过程. 这个是Spark的App运行图,它通过一个Driver来和集群通信,集群负责作业的分配.今天我要讲的是如 ...
- Spark集群之yarn提交作业优化案例
Spark集群之yarn提交作业优化案例 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. 一.启动Hadoop集群 1>.自定义批量管理脚本 [yinzhengjie@s101 ...
- Hadoop yarn工作流程详解
yarn是什么?1.它是一个资源调度及提供作业运行的系统环境平台 资源:cpu.mem等 作业:map task.reduce Task yarn产生背景?它是从hadoop2.x版本才引入1.had ...
- 如何使用git 提交作业 收作业
如何使用git 提交作业 收作业 方法论: 今天就来用一个通俗易懂的自然模型来解释Git的commit,pull和push.不过,我们首先要理解两个名词,remote,local. remote,翻译 ...
- oozie 重新提交作业
在oozie的运行过程当中可能会出现错误,比如数据库连接不上,或者作业执行报错导致流程进入suspend或者killed状态,这个时候我们就要分析了,如果确实是数据或者是网络有问题,我们比如把问题解决 ...
- oozie java api提交作业
今晚试验用java的api来提交代码,由于代码是在我机器上写的,然后提交到我的虚拟机集群当中去,所以中间产生了一个错误..要想在任意一台机器上向oozie提交作业的话,需要对hadoop的core-s ...
随机推荐
- Asp.Net 跨域,Asp.Net MVC 跨域,Session共享,CORS,Asp.Net CORS,Asp.Net MVC CORS,MVC CORS
比如 http://www.test.com 和 http://m.test.com 一.简单粗暴的方法 Web.Config <system.web> <!--其他配置 省略……- ...
- VS中ReportView的坑爹问题
ReportViewer不是.netframework提供的,而是visual studio提供的组件,它依赖如下组件: Microsoft.ReportViewer.Winforms.dll Mic ...
- WPF点滴(2) 创建单实例应用程序
最近有同事问道在应用程序启动之后,再次双击应用程序,如何保证不再启动新的应用程序,而是弹出之前已经启动的进程,本质上这就是创建一个单实例的WPF应用程序.在VS的工程树中有一个App.xaml和App ...
- C#扩展一个现有的类
做个记录,写个示例 using System; class Rubbish { public void Say() { Console.Write("Hello"); } } st ...
- OpenSL的使用
#include <jni.h> #include <string> #include <SLES/OpenSLES.h> #include <SLES/Op ...
- python中实现三目运算
python中没有其他语言中的三元表达式,不过有类似的实现方法 如: a = 1 b =2 k = 3 if a>b else 4 上面的代码就是python中实现三目运算的一个小demo, 如 ...
- HDU 6198(2017 ACM/ICPC Asia Regional Shenyang Online)
思路:找规律发现这个数是斐波那契第2*k+3项-1,数据较大矩阵快速幂搞定. 快速幂入门第一题QAQ #include <stdio.h> #include <stdlib.h& ...
- POJ 1260
//状态转移方程: F[i] = min{f[k] + (a[k+1]+………+a[i]+10} * p[i]} #include <iostream> #define MAXN 105 ...
- 54.Storm环境搭建
集群环境搭建 关闭防火墙,修改/etc/hosts配置(3台机器的ip可以相互通信) 下载安装jdk7(1.6以上),配置JAVA_HOME, CLASSPATH 搭建Zookeeper集群(保证3台 ...
- Monkey学习笔记<五>:检查内存泄露
1.分析内存泄漏工具与命令 1)HPROF文件:HPROF可以监控CPU使用率,堆分配统计 2)MAT工具:下载地址(http:www.eclipse.org/mat/) 3)生成HPROF文件命令: ...