Kafka设计解析(四)Kafka Consumer设计解析
转载自 技术世界,原文链接 Kafka设计解析(四)- Kafka Consumer设计解析
目录
一、High Level Consumer
1. Consumer Group
2. High Level Consumer Rebalance
三、Low Level Consumer
四、Consumer重新设计
1. 设计方向
摘要
本文主要介绍了Kafka High Level Consumer,Consumer Group,Consumer Rebalance,Low Level Consumer实现的语义,以及适用场景。以及未来版本中对High Level Consumer的重新设计–使用Consumer Coordinator解决Split Brain和Herd等问题。
一、High Level Consumer
很多时候,客户程序只是希望从Kafka读取数据,不太关心消息offset的处理。同时也希望提供一些语义,例如同一条消息只被某一个Consumer消费(单播)或被所有Consumer消费(广播)。因此,Kafka Hight Level Consumer提供了一个从Kafka消费数据的高层抽象,从而屏蔽掉其中的细节并提供丰富的语义。
1. Consumer Group
High Level Consumer将从某个Partition读取的最后一条消息的offset存于Zookeeper中(Kafka从0.8.2版本开始同时支持将offset存于Zookeeper中与将offset存于专用的Kafka Topic中)。这个offset基于客户程序提供给Kafka的名字来保存,这个名字被称为Consumer Group。Consumer Group是整个Kafka集群全局的,而非某个Topic的。每一个High Level Consumer实例都属于一个Consumer Group,若不指定则属于默认的Group。
Zookeeper中Consumer相关节点如下图所示
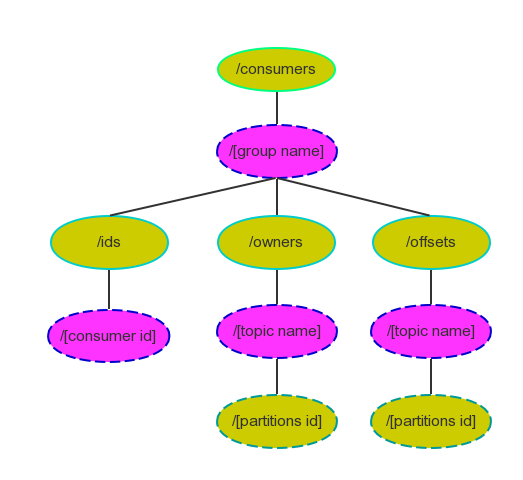
很多传统的Message Queue都会在消息被消费完后将消息删除,一方面避免重复消费,另一方面可以保证Queue的长度比较短,提高效率。而如上文所述,Kafka并不删除已消费的消息,为了实现传统Message Queue消息只被消费一次的语义,Kafka保证每条消息在同一个Consumer Group里只会被某一个Consumer消费。与传统Message Queue不同的是,Kafka还允许不同Consumer Group同时消费同一条消息,这一特性可以为消息的多元化处理提供支持。
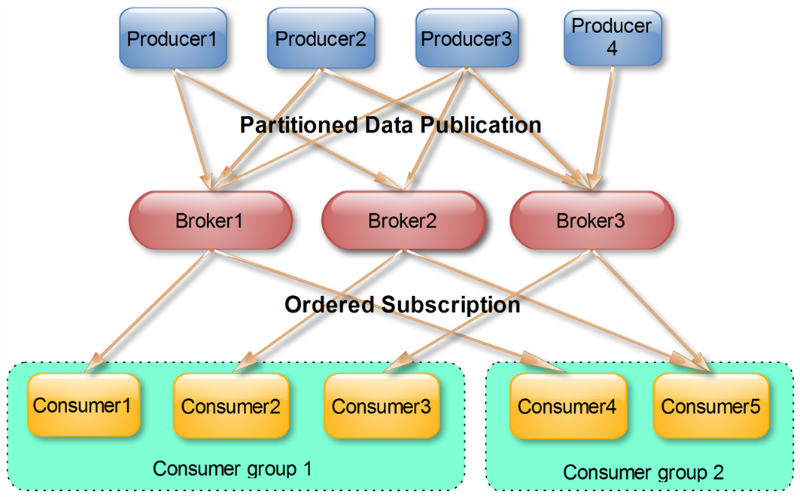
实际上,Kafka的设计理念之一就是同时提供离线处理和实时处理。根据这一特性,可以使用Storm这种实时流处理系统对消息进行实时在线处理,同时使用Hadoop这种批处理系统进行离线处理,还可以同时将数据实时备份到另一个数据中心,只需要保证这三个操作所使用的Consumer在不同的Consumer Group即可。下图展示了Kafka在LinkedIn的一种简化部署模型。
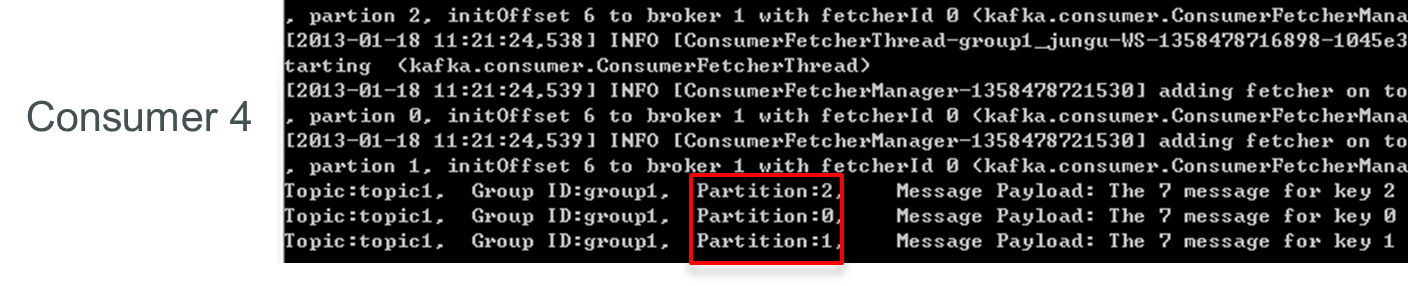
为了更清晰展示Kafka Consumer Group的特性,笔者进行了一项测试。创建一个Topic (名为topic1),再创建一个属于group1的Consumer实例,并创建三个属于group2的Consumer实例,然后通过Producer向topic1发送Key分别为1,2,3的消息。结果发现属于group1的Consumer收到了所有的这三条消息,同时group2中的3个Consumer分别收到了Key为1,2,3的消息,如下图所示。
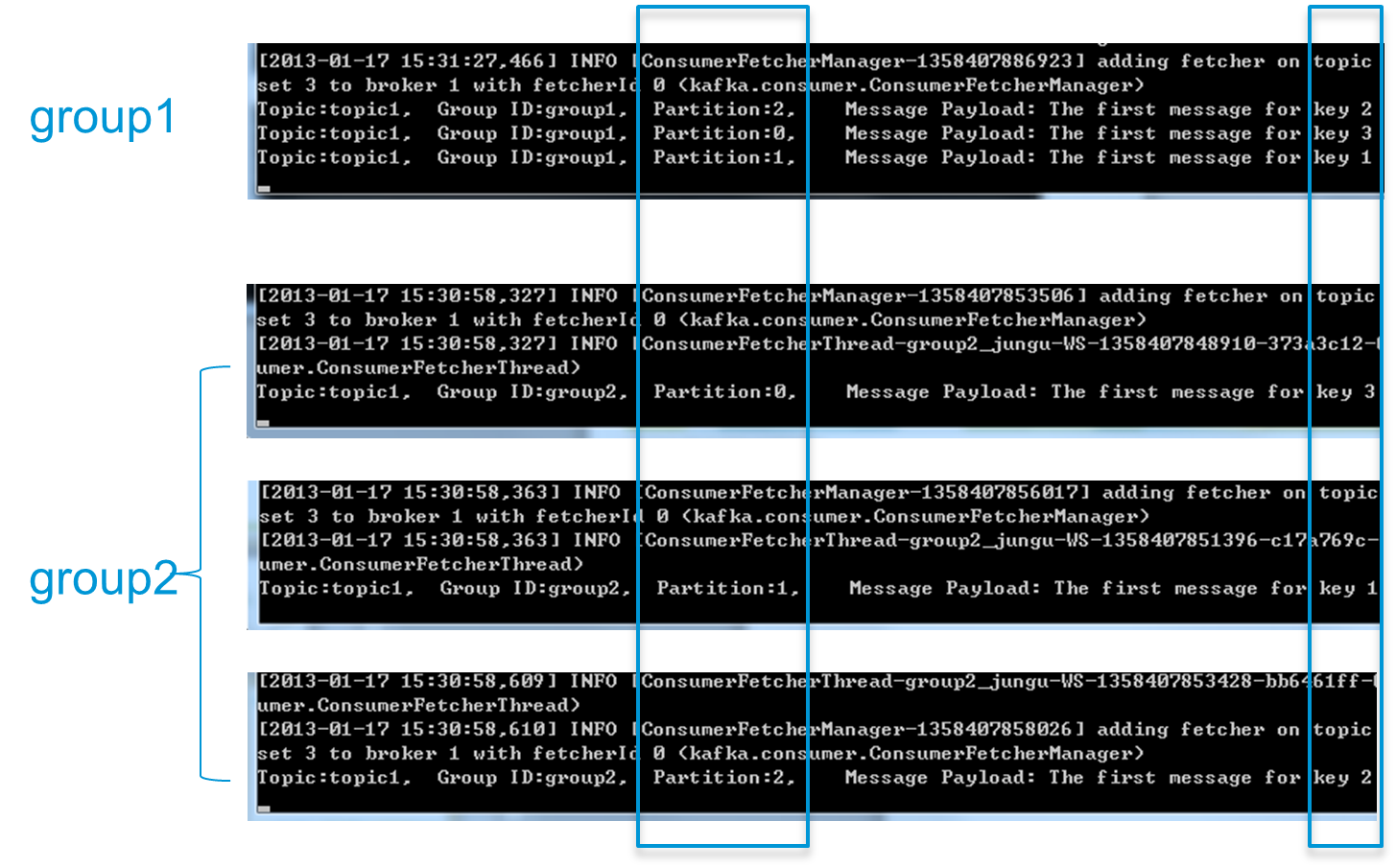
注:上图中每个黑色区域代表一个Consumer实例,每个实例只创建一个MessageStream。实际上,本实验将Consumer应用程序打成jar包,并在4个不同的命令行终端中传入不同的参数运行。
2. High Level Consumer Rebalance
(本节所讲述Rebalance相关内容均基于Kafka High Level Consumer)
Kafka保证同一Consumer Group中只有一个Consumer会消费某条消息,实际上,Kafka保证的是稳定状态下每一个Consumer实例只会消费某一个或多个特定Partition的数据,而某个Partition的数据只会被某一个特定的Consumer实例所消费。也就是说Kafka对消息的分配是以Partition为单位分配的,而非以每一条消息作为分配单元。这样设计的劣势是无法保证同一个Consumer Group里的Consumer均匀消费数据,优势是每个Consumer不用都跟大量的Broker通信,减少通信开销,同时也降低了分配难度,实现也更简单。另外,因为同一个Partition里的数据是有序的,这种设计可以保证每个Partition里的数据可以被有序消费。
如果某Consumer Group中Consumer(每个Consumer只创建1个MessageStream)数量少于Partition数量,则至少有一个Consumer会消费多个Partition的数据,如果Consumer的数量与Partition数量相同,则正好一个Consumer消费一个Partition的数据。而如果Consumer的数量多于Partition的数量时,会有部分Consumer无法消费该Topic下任何一条消息。
如下例所示,如果topic1有0,1,2共三个Partition,当group1只有一个Consumer(名为consumer1)时,该 Consumer可消费这3个Partition的所有数据。

增加一个Consumer(consumer2)后,其中一个Consumer(consumer1)可消费2个Partition的数据(Partition 0和Partition 1),另外一个Consumer(consumer2)可消费另外一个Partition(Partition 2)的数据。
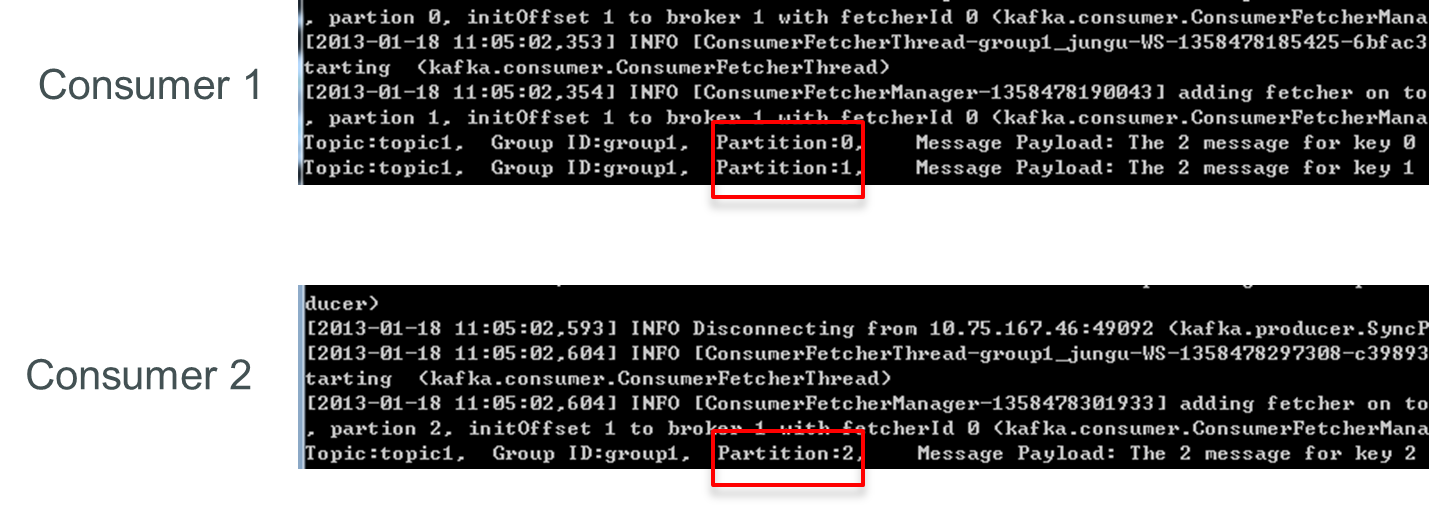
再增加一个Consumer(consumer3)后,每个Consumer可消费一个Partition的数据。consumer1消费partition0,consumer2消费partition1,consumer3消费partition2。
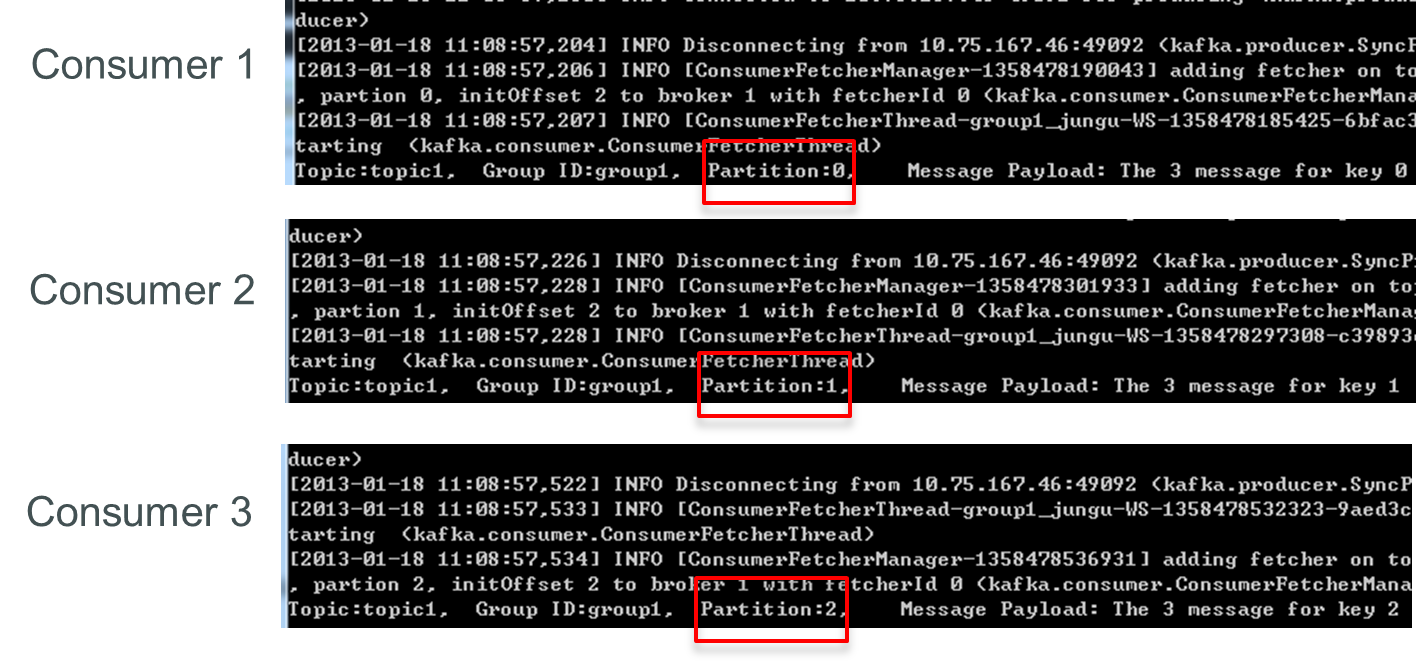
再增加一个Consumer(consumer4)后,其中3个Consumer可分别消费一个Partition的数据,另外一个Consumer(consumer4)不能消费topic1的任何数据。

此时关闭consumer1,其余3个Consumer可分别消费一个Partition的数据。
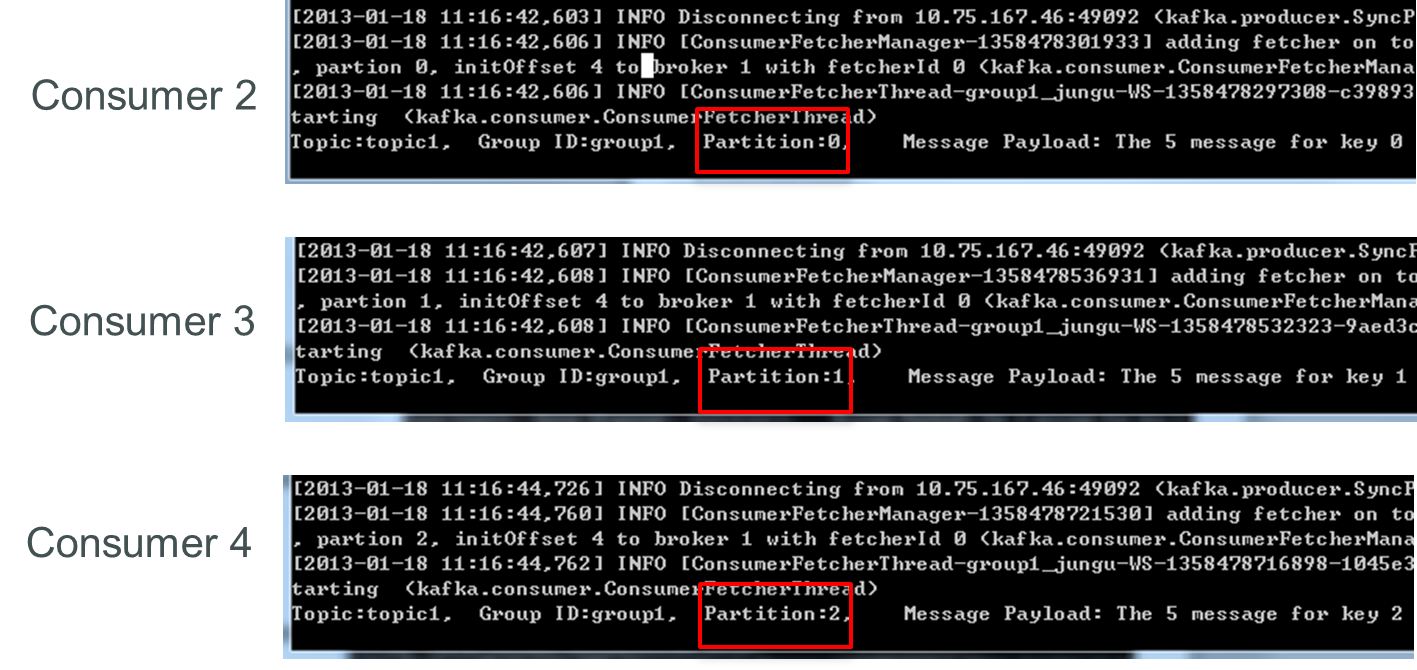
接着关闭consumer2,consumer3可消费2个Partition,consumer4可消费1个Partition。
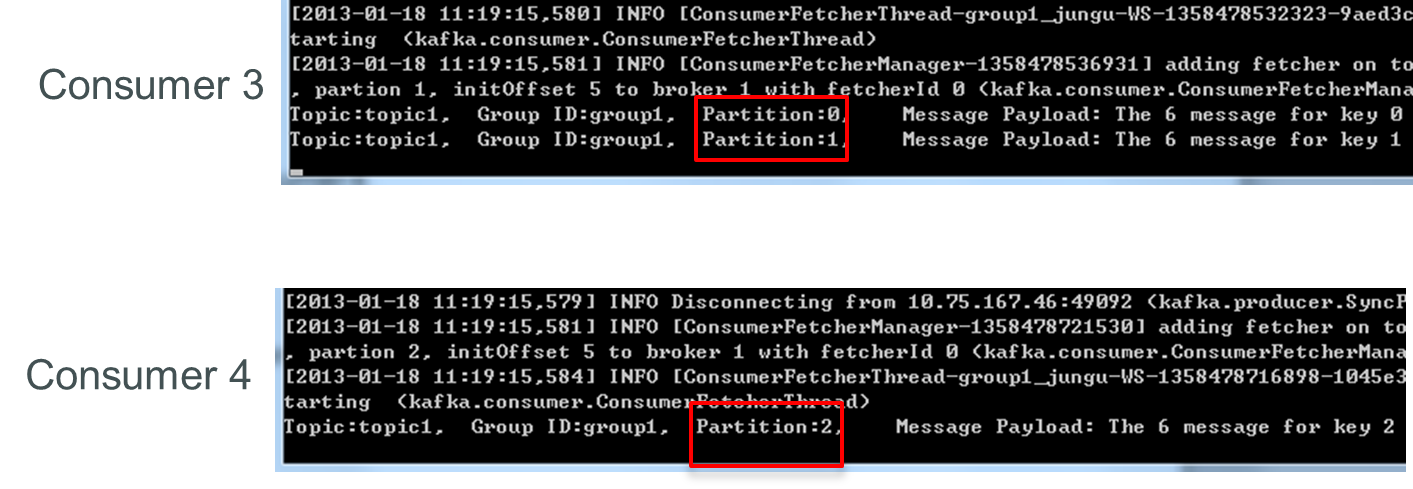
再关闭consumer3,仅存的consumer4可同时消费topic1的3个Partition。
Consumer Rebalance的算法如下:
- 将目标Topic下的所有Partirtion排序,存于PT
- 对某Consumer Group下所有Consumer排序,存于CG,第i个Consumer记为Ci
- N=size(PT)/size(CG),向上取整
- 解除Ci对原来分配的Partition的消费权(i从0开始)
- 将第 i∗N 到 (i+1)∗N−1 个Partition分配给Ci
目前,最新版(0.8.2.1)Kafka的Consumer Rebalance的控制策略是由每一个Consumer通过在Zookeeper上注册Watch完成的。每个Consumer被创建时会触发Consumer Group的Rebalance,具体启动流程如下:
- High Level Consumer启动时将其ID注册到其Consumer Group下,在Zookeeper上的路径为/consumers/[consumer group]/ids/[consumer id]
- 在/consumers/[consumer group]/ids上注册Watch
- 在/brokers/ids上注册Watch
- 如果Consumer通过Topic Filter创建消息流,则它会同时在/brokers/topics上也创建Watch
- 强制自己在其Consumer Group内启动Rebalance流程
在这种策略下,每一个Consumer或者Broker的增加或者减少都会触发Consumer Rebalance。因为每个Consumer只负责调整自己所消费的Partition,为了保证整个Consumer Group的一致性,当一个Consumer触发了Rebalance时,该Consumer Group内的其它Consumer也应该同时触发Rebalance。
该方式有如下缺陷:
- Herd effect
任何Broker或者Consumer的增减都会触发所有的Consumer的Rebalance - Split Brain
每个Consumer分别单独通过Zookeeper判断哪些Broker和Consumer 宕机了,那么不同Consumer在同一时刻从Zookeeper“看”到的View就可能不一样,这是由Zookeeper的特性决定的,这就会造成不正确的Rebalance尝试。 - 调整结果不可控
所有的Consumer都并不知道其它Consumer的Rebalance是否成功,这可能会导致Kafka工作在一个不正确的状态。
根据Kafka社区wiki,Kafka作者正在考虑在还未发布的0.9.x版本中使用中心协调器(Coordinator)。大体思想是为所有Consumer Group的子集选举出一个Broker作为Coordinator,由它Watch Zookeeper,从而判断是否有Partition或者Consumer的增减,然后生成Rebalance命令,并检查这些Rebalance在所有相关的Consumer中是否被执行成功,如果不成功则重试,若成功则认为此次Rebalance成功(这个过程跟Replication Controller非常类似)。具体方案将在后文中详细阐述。
三、Low Level Consumer
使用Low Level Consumer (Simple Consumer)的主要原因是,用户希望比Consumer Group更好的控制数据的消费。比如:
- 同一条消息读多次
- 只读取某个Topic的部分Partition
- 管理事务,从而确保每条消息被处理一次,且仅被处理一次
与Consumer Group相比,Low Level Consumer要求用户做大量的额外工作。
- 必须在应用程序中跟踪offset,从而确定下一条应该消费哪条消息
- 应用程序需要通过程序获知每个Partition的Leader是谁
- 必须处理Leader的变化
使用Low Level Consumer的一般流程如下
- 查找到一个“活着”的Broker,并且找出每个Partition的Leader
- 找出每个Partition的Follower
- 定义好请求,该请求应该能描述应用程序需要哪些数据
- Fetch数据
- 识别Leader的变化,并对之作出必要的响应
四、Consumer重新设计
根据社区社区wiki,Kafka在0.9.*版本中,重新设计Consumer可能是最重要的Feature之一。本节会根据社区wiki介绍Kafka 0.9.*中对Consumer可能的设计方向及思路。
1. 设计方向
简化消费者客户端
部分用户希望开发和使用non-java的客户端。现阶段使用non-java开发SimpleConsumer比较方便,但想开发High Level Consumer并不容易。因为High Level Consumer需要实现一些复杂但必不可少的失败探测和Rebalance。如果能将消费者客户端更精简,使依赖最小化,将会极大的方便non-java用户实现自己的Consumer。
中心Coordinator
如上文所述,当前版本的High Level Consumer存在Herd Effect和Split Brain的问题。如果将失败探测和Rebalance的逻辑放到一个高可用的中心Coordinator,那么这两个问题即可解决。同时还可大大减少Zookeeper的负载,有利于Kafka Broker的Scale Out。
允许手工管理offset
一些系统希望以特定的时间间隔在自定义的数据库中管理Offset。这就要求Consumer能获取到每条消息的metadata,例如Topic,Partition,Offset,同时还需要在Consumer启动时得到每个Partition的Offset。实现这些,需要提供新的Consumer API。同时有个问题不得不考虑,即是否允许Consumer手工管理部分Topic的Offset,而让Kafka自动通过Zookeeper管理其它Topic的Offset。一个可能的选项是让每个Consumer只能选取1种Offset管理机制,这可极大的简化Consumer API的设计和实现。
Rebalance后触发用户指定的回调
一些应用可能会在内存中为每个Partition维护一些状态,Rebalance时,它们可能需要将该状态持久化。因此该需求希望支持用户实现并指定一些可插拔的并在Rebalance时触发的回调。如果用户使用手动的Offset管理,那该需求可方便得由用户实现,而如果用户希望使用Kafka提供的自动Offset管理,则需要Kafka提供该回调机制。
非阻塞式Consumer API
该需求源于那些实现高层流处理操作,如filter by, group by, join等,的系统。现阶段的阻塞式Consumer几乎不可能实现Join操作。
##如何通过中心Coordinator实现Rebalance
成功Rebalance的结果是,被订阅的所有Topic的每一个Partition将会被Consumer Group内的一个(有且仅有一个)Consumer拥有。每一个Broker将被选举为某些Consumer Group的Coordinator。某个Cosnumer Group的Coordinator负责在该Consumer Group的成员变化或者所订阅的Topic的Partition变化时协调Rebalance操作。
Consumer
(1) Consumer启动时,先向Broker列表中的任意一个Broker发送ConsumerMetadataRequest,并通过ConsumerMetadataResponse获取它所在Group的Coordinator信息。ConsumerMetadataRequest和ConsumerMetadataResponse的结构如下
ConsumerMetadataRequest
{
GroupId => String
}
ConsumerMetadataResponse
{
ErrorCode => int16
Coordinator => Broker
}
(2)Consumer连接到Coordinator并发送HeartbeatRequest,如果返回的HeartbeatResponse没有任何错误码,Consumer继续fetch数据。若其中包含IllegalGeneration错误码,即说明Coordinator已经发起了Rebalance操作,此时Consumer停止fetch数据,commit offset,并发送JoinGroupRequest给它的Coordinator,并在JoinGroupResponse中获得它应该拥有的所有Partition列表和它所属的Group的新的Generation ID。此时Rebalance完成,Consumer开始fetch数据。相应Request和Response结构如下
HeartbeatRequest
{
GroupId => String
GroupGenerationId => int32
ConsumerId => String
}
HeartbeatResponse
{
ErrorCode => int16
}
JoinGroupRequest
{
GroupId => String
SessionTimeout => int32
Topics => [String]
ConsumerId => String
PartitionAssignmentStrategy => String
}
JoinGroupResponse
{
ErrorCode => int16
GroupGenerationId => int32
ConsumerId => String
PartitionsToOwn => [TopicName [Partition]]
}
TopicName => String
Partition => int32
Consumer状态机
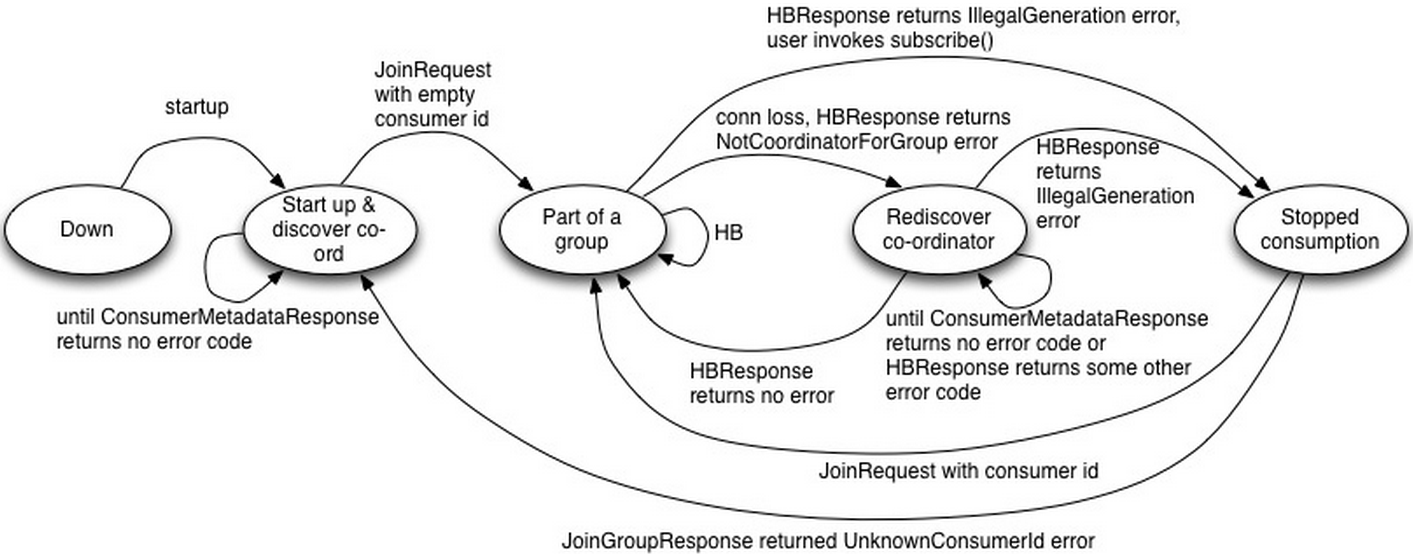
Down:Consumer停止工作
Start up & discover coordinator:Consumer检测其所在Group的Coordinator。一旦它检测到Coordinator,即向其发送JoinGroupRequest。
Part of a group:该状态下,Consumer已经是该Group的成员,并周期性发送HeartbeatRequest。如HeartbeatResponse包含IllegalGeneration错误码,则转换到Stopped Consumption状态。若连接丢失,HeartbeatResponse包含NotCoordinatorForGroup错误码,则转换到Rediscover coordinator状态。
Rediscover coordinator:该状态下,Consumer不停止消费而是尝试通过发送ConsumerMetadataRequest来探测新的Coordinator,并且等待直到获得无错误码的响应。
Stopped consumption:该状态下,Consumer停止消费并提交offset,直到它再次加入Group。
故障检测机制
Consumer成功加入Group后,Consumer和相应的Coordinator同时开始故障探测程序。Consumer向Coordinator发起周期性的Heartbeat(HeartbeatRequest)并等待响应,该周期为 session.timeout.ms/heartbeat.frequency。若Consumer在session.timeout.ms内未收到HeartbeatResponse,或者发现相应的Socket channel断开,它即认为Coordinator已宕机并启动Coordinator探测程序。若Coordinator在session.timeout.ms内没有收到一次HeartbeatRequest,则它将该Consumer标记为宕机状态并为其所在Group触发一次Rebalance操作。
Coordinator Failover过程中,Consumer可能会在新的Coordinator完成Failover过程之前或之后发现新的Coordinator并向其发送HeatbeatRequest。对于后者,新的Cooodinator可能拒绝该请求,致使该Consumer重新探测Coordinator并发起新的连接请求。如果该Consumer向新的Coordinator发送连接请求太晚,新的Coordinator可能已经在此之前将其标记为宕机状态而将之视为新加入的Consumer并触发一次Rebalance操作。
Coordinator
(1)稳定状态下,Coordinator通过上述故障探测机制跟踪其所管理的每个Group下的每个Consumer的健康状态。
(2)刚启动时或选举完成后,Coordinator从Zookeeper读取它所管理的Group列表及这些Group的成员列表。如果没有获取到Group成员信息,它不会做任何事情直到某个Group中有成员注册进来。
(3)在Coordinator完成加载其管理的Group列表及其相应的成员信息之前,它将为HeartbeatRequest,OffsetCommitRequest和JoinGroupRequests返回CoordinatorStartupNotComplete错误码。此时,Consumer会重新发送请求。
(4)Coordinator会跟踪被其所管理的任何Consumer Group注册的Topic的Partition的变化,并为该变化触发Rebalance操作。创建新的Topic也可能触发Rebalance,因为Consumer可以在Topic被创建之前就已经订阅它了。
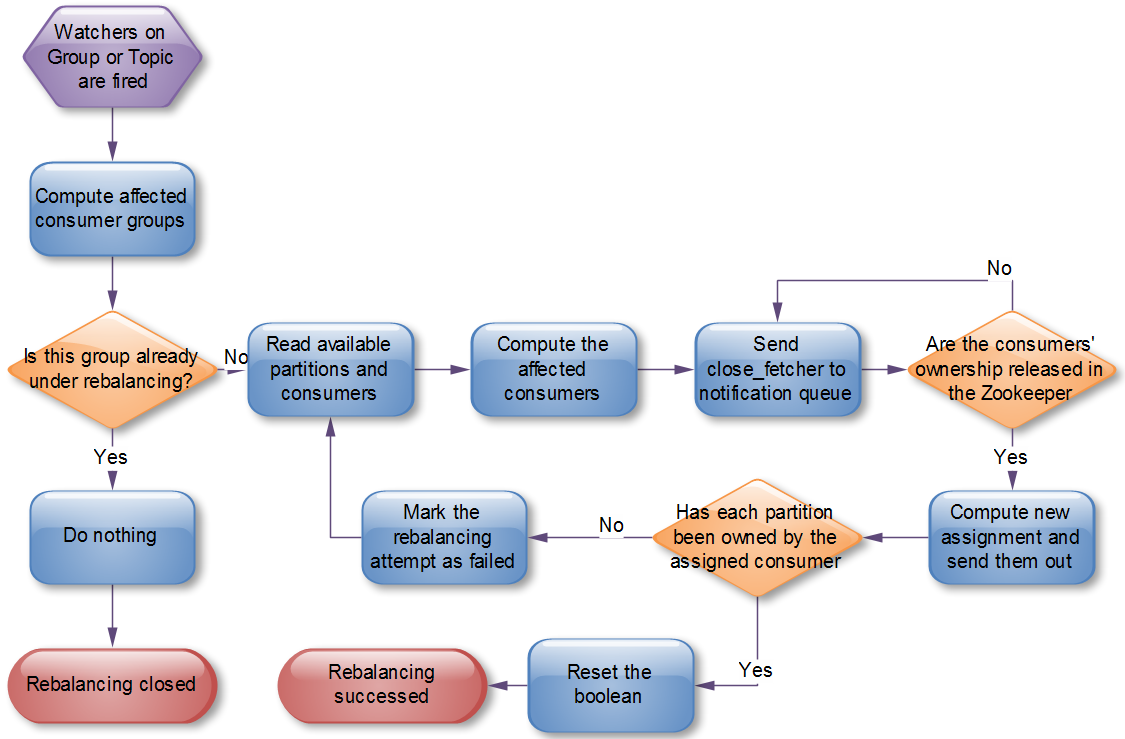
Coordinator发起Rebalance操作流程如下所示。
Coordinator状态机
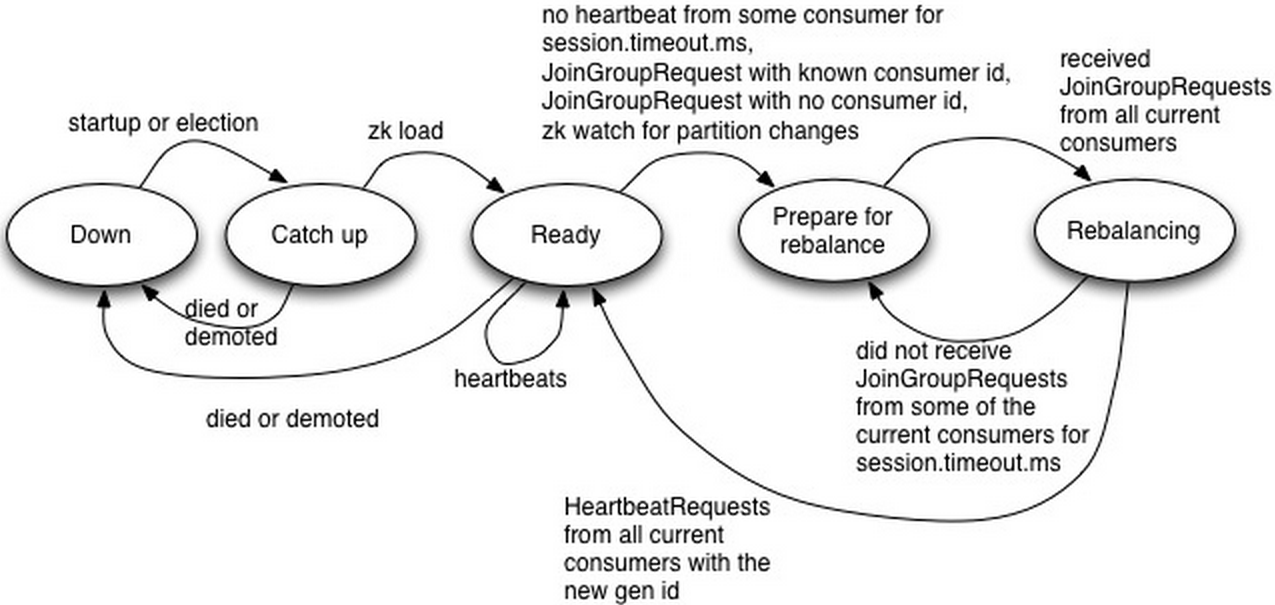
Down:Coordinator不再担任之前负责的Consumer Group的Coordinator
Catch up:该状态下,Coordinator竞选成功,但还未能做好服务相应请求的准备。
Ready:该状态下,新竞选出来的Coordinator已经完成从Zookeeper中加载它所负责管理的所有Group的metadata,并可开始接收相应的请求。
Prepare for rebalance:该状态下,Coordinator在所有HeartbeatResponse中返回IllegalGeneration错误码,并等待所有Consumer向其发送JoinGroupRequest后转到Rebalancing状态。
Rebalancing:该状态下,Coordinator已经收到了JoinGroupRequest请求,并增加其Group Generation ID,分配Consumer ID,分配Partition。Rebalance成功后,它会等待接收包含新的Consumer Generation ID的HeartbeatRequest,并转至Ready状态。
Coordinator Failover
如前文所述,Rebalance操作需要经历如下几个阶段
(1)Topic/Partition的改变或者新Consumer的加入或者已有Consumer停止,触发Coordinator注册在Zookeeper上的watch,Coordinator收到通知准备发起Rebalance操作。
(2)Coordinator通过在HeartbeatResponse中返回IllegalGeneration错误码发起Rebalance操作。
(3)Consumer发送JoinGroupRequest
(4)Coordinator在Zookeeper中增加Group的Generation ID并将新的Partition分配情况写入Zookeeper
(5)Coordinator发送JoinGroupResponse
在这个过程中的每个阶段,Coordinator都可能出现故障。下面给出Rebalance不同阶段中Coordinator的Failover处理方式。
(1)如果Coordinator的故障发生在第一阶段,即它收到Notification并未来得及作出响应,则新的Coordinator将从Zookeeper读取Group的metadata,包含这些Group订阅的Topic列表和之前的Partition分配。如果某个Group所订阅的Topic数或者某个Topic的Partition数与之前的Partition分配不一致,亦或者某个Group连接到新的Coordinator的Consumer数与之前Partition分配中的不一致,新的Coordinator会发起Rebalance操作。
(2)如果失败发生在阶段2,它可能对部分而非全部Consumer发出带错误码的HeartbeatResponse。与第上面第一种情况一样,新的Coordinator会检测到Rebalance的必要性并发起一次Rebalance操作。如果Rebalance是由Consumer的失败所触发并且Cosnumer在Coordinator的Failover完成前恢复,新的Coordinator不会为此发起新的Rebalance操作。
(3)如果Failure发生在阶段3,新的Coordinator可能只收到部分而非全部Consumer的JoinGroupRequest。Failover完成后,它可能收到部分Consumer的HeartRequest及另外部分Consumer的JoinGroupRequest。与第1种情况类似,它将发起新一轮的Rebalance操作。
(4)如果Failure发生在阶段4,即它将新的Group Generation ID和Group成员信息写入Zookeeper后。新的Generation ID和Group成员信息以一个原子操作一次性写入Zookeeper。Failover完成后,Consumer会发送HeartbeatRequest给新的Coordinator,并包含旧的Generation ID。此时新的Coordinator通过在HeartbeatResponse中返回IllegalGeneration错误码发起新的一轮Rebalance。这也解释了为什么每次HeartbeatRequest中都需要包含Generation ID和Consumer ID。
(5)如果Failure发生在阶段5,旧的Coordinator可能只向Group中的部分Consumer发送了JoinGroupResponse。收到JoinGroupResponse的Consumer在下次向已经失效的Coordinator发送HeartbeatRequest或者提交Offset时会检测到它已经失败。此时,它将检测新的Coordinator并向其发送带有新的Generation ID 的HeartbeatRequest。而未收到JoinGroupResponse的Consumer将检测新的Coordinator并向其发送JoinGroupRequest,这将促使新的Coordinator发起新一轮的Rebalance。
Kafka设计解析(四)Kafka Consumer设计解析的更多相关文章
- Kafka设计解析(四)- Kafka Consumer设计解析
本文转发自Jason’s Blog,原文链接 http://www.jasongj.com/2015/08/09/KafkaColumn4 摘要 本文主要介绍了Kafka High Level Con ...
- Kafka学习笔记之Kafka Consumer设计解析
0x00 摘要 本文主要介绍了Kafka High Level Consumer,Consumer Group,Consumer Rebalance,Low Level Consumer实现的语义,以 ...
- Kafka详解四:Kafka的设计思想、理念
问题导读 1.Kafka的设计基本思想是什么?2.Kafka消息转运过程中是如何确保消息的可靠性的? 本节主要从整体角度介绍Kafka的设计思想,其中的每个理念都可以深入研究,以后我可能会发专题文章做 ...
- kafka具体解释四:Kafka的设计思想、理念
版权声明:本文为博主原创文章,未经博主同意不得转载. https://blog.csdn.net/suifeng3051/article/details/37606001 本节主要从总体角度 ...
- Kafka(三)Kafka的高可用与生产消费过程解析
一 Kafka HA设计解析 1.1 为何需要Replication 在Kafka在0.8以前的版本中,是没有Replication的,一旦某一个Broker宕机,则其上所有的Partition数据 ...
- kafka之二:Kafka 设计与原理详解
一.Kafka简介 本文综合了我之前写的kafka相关文章,可作为一个全面了解学习kafka的培训学习资料. 转载请注明出处 : 本文链接 1.1 背景历史 当今社会各种应用系统诸如商业.社交.搜索. ...
- 中间件 | kafka简介、使用场景、设计原理、主要配置及集群搭建
开源Java学习 公众号 一.入门 1.简介 Kafka is a distributed,partitioned,replicated commit logservice.它提供了类似于JMS的特性 ...
- Kafka实战分析(一)- 设计、部署规划及其调优
1. Kafka概要设计 kafka在设计之初就需要考虑以下4个方面的问题: 吞吐量/延时 消息持久化 负载均衡和故障转移 伸缩性 1.1 吞吐量/延时 对于任何一个消息引擎而言,吞吐量都是至关重要的 ...
- kafka 异步双活方案 mirror maker2 深度解析
mirror maker2背景 通常情况下,我们都是使用一套kafka集群处理业务.但有些情况需要使用另一套kafka集群来进行数据同步和备份.在kafka早先版本的时候,kafka针对这种场景就有推 ...
随机推荐
- cakephp引入其他控制器封装方法
- C#基础 继承和实例化
有代码如下,问输出的是多少: class Program { static void Main(string[] args) { B b = new B(); Console.ReadKey(); } ...
- P2P文件上传
采用uploadify上传 官网:http://www.uploadify.com/ (有H5版本和flash版本,H5收费,所以暂时用flash) uploadify的重要配置属性(http:/ ...
- 0ctf2018 pwn
前言 对 0ctf2018 的 pwn 做一个总结 正文 babystack 漏洞 非常直接的 栈溢出 ssize_t sub_804843B() { char buf; // [esp+0h] [e ...
- redis 管道技术 pipeline 简介
redis数据库的主要瓶颈是网络速度,其次是内存与cpu.在应用允许的情况下,优先使用pipeline批量操作.pipeline批量发出请求/一次性获取响应:不是发出多个请求,每个请求都阻塞等待响应, ...
- sql 流程函数
create table salary (userid int,salary decimal(9,2)); -- mysqlinsert into salary values(1,1000),(2,2 ...
- Docker 网络基础介绍
[编者按]本文作者为 Mesosphere 开发大使 Michael Hausenblas,主要介绍配置 Docker 单主机网络的基本知识.文章系国内 ITOM 管理平台 OneAPM 编译呈现. ...
- elipse安装php
在用eclipse作为PHP的开发IDE工具时,如果下载的Eclipse不带有PHP功能,则需要我们自己来给Eclipse升级.不过也可以下载eclipseForPHP 在Eclipse的help菜单 ...
- poj2182 逆推暴力
题意 告诉有n头牛,每头牛有一个编号1~n,再一次烂醉之后,奶牛们没有按照编号排队:告诉你对于第i头奶牛,在它之前有多少头奶牛比它的编号小(i>1,因为第1头奶牛的数据永远为0,故题中省略),求 ...
- asp.net中的<%%>的使用
在asp.net中常见的<%%>方式有如下几种: <%%>.<%=%>.<%:%>.<%#%>.<%$%>.<%@%> ...