<泛> 多路快排
今天写一个多路快排函数模板,与STL容器兼容的。
我们默认为升序排序
因为,STL容器均为逾尾容器,所以我们这里采用的参数也是逾尾的参数
一、二路快排
基本思路
给你一个序列,先选择一个数作为基数,我们要做的是把小于该基数的数字放于左侧,大于该基数的数字放于右侧,最后将此基数放于中间,形成新的序列,我们把左侧序列和右侧序列分别像之前那样做,最后得到的序列即为顺序序列。
过程演示
比如给你一个序列 4 3 1 5 4 7 9 1 8 0
我们采用双指针扫描法,红色代表左指针所指位置,绿色代表右指针所指位置
我们选取一个数作为基数,假设选第一个数,即 flag 为 4
那么,我们把这个位置空出来,用null表示
则,一开始的序列图为
null 3 1 5 4 7 9 1 8 0 flag is 4
我们从右指针开始遍历,找到第一个小于flag的数字,填入坑中,然后左指针++,指向下一位然后开始遍历
0 1 5 4 7 9 1 8 null
0 3 5 4 7 9 1 8 null
0 3 1 4 7 9 1 8 null
0 3 1 null 4 7 9 1 5
0 3 1 null 4 7 9 8 5
0 3 1 1 7 9 null 8 5
0 3 1 1 4 7 9 null 8 5
0 3 1 1 4 null 7 8 5
右指针指向9,9>flag,继续左移,然后红绿指针相遇,结束
我们把flag放入null,即形成了新的序列
0 3 1 1 4 4 9 7 8 5
我们把左侧序列0 3 1 1 4
和右侧序列9 7 8 5
分别如上做,即可得到有序序列
C++模板代码:
template<typename value_type, typename value_Ptr>
void quick_sort(value_Ptr begin, value_Ptr end) //逾尾
{
if (begin == end)return; value_type flag = *begin; value_Ptr l = begin, r = end;
r--;
while (l < r)
{
while (l < r && *r > flag)r--;
if (l < r)*(l++) = *r;
while (l < r && *l < flag)l++;
if (l < r)*(r--) = *l;
}
*l = flag;
quick_sort<value_type>(begin, l);
quick_sort<value_type>(l + , end);
}
测试以及使用
#include <iostream>
#include <vector>
using namespace std; int main()
{
ios::sync_with_stdio(false); int list[]{ ,,,,,,,,, };
vector<int> v{ list,list + }; quick_sort<int>(list + , list + );
quick_sort<int>(v.begin(), v.end());
for (auto it : v)cout << it << " ";
cout << endl;
for (auto it : list)cout << it << " ";
cout << endl; char list_[]{ 'r','c','','A','z','b','','','r', '' };
vector<char>v_{ list_,list_ + }; quick_sort<char>(list_ + , list_ + );
quick_sort<char>(v_.begin(), v_.end());
for (auto it : v_)cout << it << " ";
cout << endl;
for (auto it : list_)cout << it << " ";
cout << endl;
}
测试结果
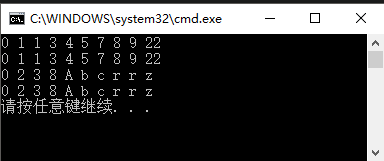
效率为O(N * logN)
如果序列中有很多重复的元素,那么,那一长串的重复值就相当于一个非递减序列,按理说是不需要排序的,但是上述无法识别此情况,它依旧会把这一长串不必处理的序列进行处理,无疑将函数执行效率大打折扣
这时,我们就需要引入三路快排
二、三路快排
基本思路
给你一个序列,我们选择一个基数作为标准,小于基数的元素放于左侧区间,等于基数的元素放于中间区间,大于基数的元素放于右侧区间
整理好之后,我们将左侧区间和右侧区间如上做。
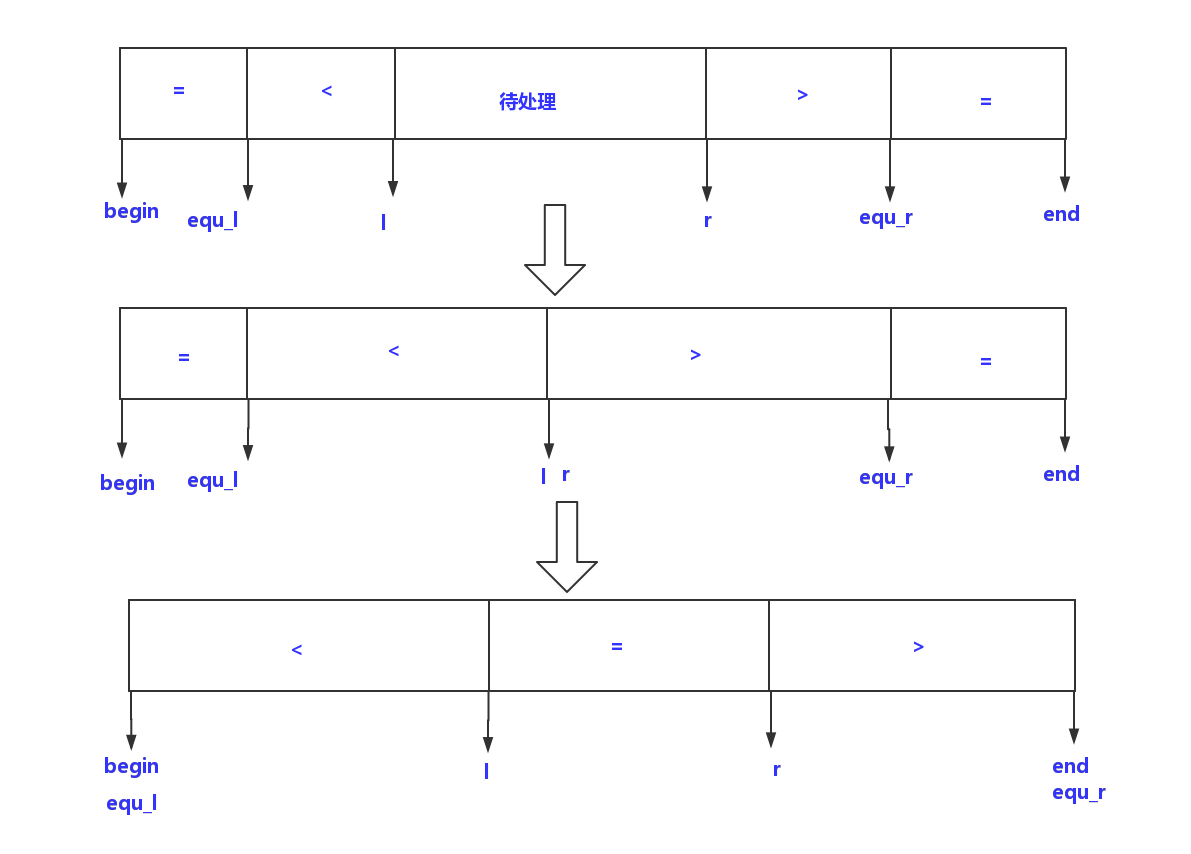
过程描述
我们用四指针扫描
l r 用于扫描待处理的序列
equ_l equ_r 用于记录两侧相等的区间
equ_l = l = begin
r 和equ_r指向右侧
让l r向中间遍历,遇到不等于的情况和快排一样,留一个空位,依次填补即可,遇到相等的情况,左指针指向的值等于基数,那么就放于equ_l处,且equ_l++,右边同理
当l r 相遇时,我们让四指针分别向两端移动,equ_l 所指的元素依次和 l 所指的元素交换,右侧同理,即可得到我们想要的序列,即 < = >
之后,我们将<区间和>区间分别如上做,即可得到有序序列
泛型模板代码:
template<typename value_type, typename value_Ptr>
void Tri_quick(const value_Ptr& begin, const value_Ptr& end)
{
static auto swap = [](value_type& l, value_type& r)
{
if (l == r)return;
value_type t{ l };
l = r;
r = t;
};
value_Ptr equ_l = begin, equ_r = end, l = begin, r = end;
if (begin >= end || begin >= end - )return; //上式:如果第二个条件成立的话,表达式1中的 ++l 就会解析 end 迭代器
value_type flag = *l;
while (l < r)
{
while (l < r && *(++l) < flag)if (l == end - )break; // 表达式1
while (l < r && flag < *(--r));
if (*l != *r) swap(*l, *r);
if (*l == flag) swap(*(++equ_l), *l);
if (*r == flag) swap(*(--equ_r), *r);
}
if (*l > flag)l--;
//此时l==r,可能l的值大于flag,我们不换,但是前面的一定小于等于flag,所以我们--
while (equ_l > begin)swap(*(equ_l--), *(l--));
//选择大于是因为equ_l如果为容器的begin迭代器,那么不允许--操作
swap(*equ_l, *l);
//所以begin迭代器另做处理
while (equ_r < end)swap(*(equ_r++), *(r++));
Tri_quick<value_type>(begin, l);
Tri_quick<value_type>(r, end);
}
测试及使用
#include <iostream>
#include <vector>
using namespace std; int main()
{
ios::sync_with_stdio(false);
int list[]{ ,,,,,,,,, };
vector<int> v{ list,list + };
Tri_quick<int>(list + , list + );
for (auto it : list)cout << it << " ";
cout << endl;
Tri_quick<int>(v.begin(), v.end());
for (auto it : v)cout << it << " ";
cout << endl; char list_[]{ 'r','c','','A','z','b','','','r', '' };
vector<char>v_{ list_,list_ + }; Tri_quick<char>(list_ + , list_ + );
Tri_quick<char>(v_.begin(), v_.end());
for (auto it : v_)cout << it << " ";
cout << endl;
for (auto it : list_)cout << it << " ";
cout << endl;
}
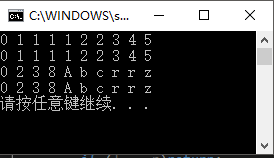
注:三路快排中即使没有重复元素,那也最差退化到二路快排的效率,效率不会低于二路快排
这就是今天的多路快排,关于快排有很多不适应的情况,也有很多优化的算法,关于其他的算法,大家可以去其他地方学习,这里不做赘述
如果有什么问题,请于下方评论区留言。
感谢您的阅读,生活愉快~
<泛> 多路快排的更多相关文章
- Java常见的几种排序算法-插入、选择、冒泡、快排、堆排等
本文就是介绍一些常见的排序算法.排序是一个非常常见的应用场景,很多时候,我们需要根据自己需要排序的数据类型,来自定义排序算法,但是,在这里,我们只介绍这些基础排序算法,包括:插入排序.选择排序.冒泡排 ...
- 网站快速收录/站点快速收录/seo快排技术/seo快速排名/泛域名快速收录/泛目录快速收录
泛目录技术是目前最快速最有效的办法,增加站点的收录方面,这里推荐莲花泛目录 莲花泛目录,完善的技术支持,代码亲自编写,独立研发.业界领先. (这个是seo关键词,请无视,直接看下面的泛目程序介绍)网站 ...
- F#之旅4 - 小实践之快排
参考文章:https://swlaschin.gitbooks.io/fsharpforfunandprofit/content/posts/fvsc-quicksort.html F#之旅4 - 小 ...
- 快排 快速排序 qsort quicksort C语言
现在网上搜到的快排和我以前打的不太一样,感觉有点复杂,我用的快排是FreePascal里/demo/text/qsort.pp的风格,感觉特别简洁. #include<stdio.h> # ...
- iOS常见算法(二分法 冒泡 选择 快排)
二分法: 平均时间复杂度:O(log2n) int halfFuntion(int a[], int length, int number) { int start = 0; int end = l ...
- C++ 快排
// 进行一轮快排并返回当前的中间数 int getMiddle( int* arr, int low, int high ) { auto swaparr = [&]( int i, int ...
- 先贴上代码:Random快排,快排的非递归实现
设要排序的数组是A[0]……A[N-1],首先任意选取一个数据(通常选用数组的第一个数)作为主元,然后将所有比它小的数都放到它前面,所有比它大的数都放到它后面,这个过程称为一趟快速排序.值得注意的是, ...
- ACM/ICPC 之 快排+归并排序-记录顺序对(TSH OJ-LightHouse(灯塔))
TsingHua OJ 上不能使用<algorithm>头文件,因此需要手写快排(刚开始写的时候自己就出了很多问题....),另外本题需要在给横坐标排序后,需要记录纵坐标的顺序对的数量,因 ...
- 数组第K小数问题 及其对于 快排和堆排 的相关优化比较
题目描述 给定一个整数数组a[0,...,n-1],求数组中第k小数 输入描述 首先输入数组长度n和k,其中1<=n<=5000, 1<=k<=n 然后输出n个整形元素,每个数 ...
随机推荐
- SVN搭建和使用
原文出处: http://www.cnblogs.com/tugenhua0707/p/3969558.html SVN简介: 为什么要使用SVN? 程序员在编写程序的过程中,每个程序员都会生成很多不 ...
- [转载]查询json数据结构的8种方式
http://wangxinghaoaccp.blog.163.com/blog/static/1158102362012111812255980/ 你有没有对“在复杂的JSON数据结构中查找匹配内容 ...
- JS回调函数的应用,原来这么简单!
JS的回调函数很简单,看代码: 在a.js中 var myback = null; function load(obj){ myback = obj; } function save(){ // 后台 ...
- 【转】.NET+AE开发中常见几种非托管对象的释放
尝试读取或写入受保护的内存.这通常指示其他内存已损坏. 今天在开发时遇到一个问题:" 未处理 System.AccessViolationException Message="尝试 ...
- 技术分享:如何在PowerShell脚本中嵌入EXE文件
技术分享:如何在PowerShell脚本中嵌入EXE文件 我在尝试解决一个问题,即在客户端攻击中只使用纯 PowerShell 脚本作为攻击负荷.使用 PowerShell 运行恶意代码具有很多优点, ...
- 20165227 学习基础和C语言基础调查
学习基础和C语言基础调查 技能学习经验和感悟 你有什么技能比大多人(超过90%以上)更好? 如果非要说出来一个的话,那就是篮球了.从热爱篮球,到热爱打篮球,经历挫折阻碍,不断反思学习,一步一步地向前迈 ...
- Dream------spark--spark集群的环境搭建
1.下载安装scala http://www.scala-lang.org/download/2.11.6.html 2.解压下载后的文件,配置环境变量:编辑/etc/profile文件,添加如下 ...
- 41 - 数据库-pymysql41 - 数据库-pymysql-DBUtils
目录 1 Python操作数据库 2 安装模块 3 基本使用 3.1 创建一个连接 3.2 连接数据库 3.3 游标 3.3.1 利用游标操作数据库 3.3.2 事务管理 3.3.3 执行SQL语句 ...
- juery下拉刷新,ajax请求,div加载更多元素(一)
;//设置当前页数 var flag=true; //滑动加载 $(function(){ var winH = $(window).height(); //页面可视区域高度 $(window).sc ...
- oracle11g字符集问题之一
select * from T_WORK_EXPERIENCE t where ROLE=N'被雇佣者' 因为ROLE为NVARCHAR2(30),所以要加N.pl/sql developer 中可以 ...