转载:GBDT算法梳理
学习内容:
前向分布算法
负梯度拟合
损失函数
回归
二分类,多分类
正则化
优缺点
sklearn参数
应用场景
转自:https://zhuanlan.zhihu.com/p/58105824
GBDT是一种采用加法模型(即基函数的线性组合)与前向分步算法并以决策树作为基函数的提升方法。通俗来说就是,该算法由多棵决策树组成,所有树的结论加起来形成最终答案。
一、前向分步算法(考虑加法模型)
要理解GBDT算法,得先来了解一下什么是前向分步算法。下面一起来瞧瞧。
加法模型是这样的:
(就是基学习器的一种线性组合啦)
其中, 为基函数,
为基函数的参数,
为基函数的系数。
在给定训练数据及损失函数 的条件下,学习加法模型成为损失函数极小化问题:
(同时求解那么多参数,好复杂)
前向分步算法求解这一优化问题的思路:因为学习的是加法模型,如果能够从前向后,每一步只学习一个基函数及其系数,逐步去逼近上述的目标函数式,就可简化优化的复杂度,每一步只需优化如下损失函数:
(每步学习一个基函数和系数)
前向分步算法流程:
--------------------------------------------------------------------------------------------
输入:训练数据集T=({ });损失函数L(y,f(x));基函数集{
};
输出:加法模型f(x)
(1) 初始化
(2) 对m=1,2,...,M
(a) 极小化损失函数
得到参数
(b)更新
(3)得到加法模型
------------------------------------------------------------------------------------------
可见,前向分步算法将同时求解从m=1到M所有参数 的优化问题简化成逐步求解各个
的优化问题了。
二、负梯度拟合
1.提升树算法
了解完前向分步算法,再来看看什么是提升树算法。
提升方法实际采用加法模型与前向分步算法,以决策树作为基函数的提升方法称为提升树。注意,这里的决策树为CART回归树,不是分类树。当问题是分类问题时,采用的决策树模型为分类回归树。为什么要采用决策树作为基函数呢?它有以下优缺点:
优点
- 可解释性强
- 可处理混合类型特征
- 具有伸缩不变性(不用归一化特征)
- 有特征组合的作用
- 可自然处理缺失值
- 对异常点鲁棒
- 有特征选择作用
- 可扩展性强,容易并行
缺点
- 缺乏平滑性(回归预测时输出值只能是输出有限的若干种数值)
- 不适合处理高维稀疏数据
由于树的线性组合可以很好地拟合训练数据,即使数据中的输入与输出之间的关系很复杂也是如此。
提升树模型可表示为:
其中, 表示决策树;
为决策树的参数;M为树的个数;M为树的个数。
针对不同的问题,提升树算法的形式有所不同,其主要区别在于使用的损失函数不同。而损失函数的不同,决策树要拟合的值也会不同。就一般而言,对于回归问题的提升树算法来说,若损失函数是平方损失函数,每一步只需简单拟合当前模型的残差。
下面看一下在回归问题下,损失函数为平方损失函数的算法流程:
--------------------------------------------------------------------------------------------
输入:训练数据集T={ },
;
输出:提升树
(1)初始化
(2)对m=1,2,...,M
(a)计算残差
(b)拟合残差 学习一个回归树,得到
(c)更新
(3)得到回归问题提升树
--------------------------------------------------------------------------------------------
2.梯度提升
提升树用加法模型与前向分布算法实现学习的优化过程。当损失函数为平方损失和指数损失函数时,每一步优化是很简单的。但对于一般损失函数而言,往往每一步都不那么容易。对于这问题,Freidman提出了梯度提升算法。这是利用最速下降法的近似方法,其关键是利用损失函数的负梯度在当前模型的值:
作为回归问题在当前模型的残差的近似值,拟合一个回归树。
为什么要拟合负梯度呢?这就涉及到泰勒公式和梯度下降法了。
泰勒公式的形式是这样的:
- 定义:泰勒公式是一个用函数在某点的信息描述其附近取值的公式。
- 基本形式:
- 一阶泰勒展开:
梯度下降法
在机器学习任务中,需要最小化损失函数 ,其中
是要求解的模型参数。梯度下降法常用来求解这种无约束最优化问题,它是一种迭代方法:选择初值
,不断迭代更新
的值,进行损失函数极小化。
- 迭代公式:
- 将
在
处进行一阶泰勒展开:
- 要使得
,可取:
,则:
,这里
是步长,一般直接赋值一个小的数。
相对的,在函数空间里,有
此处把 看成提升树算法的第t步损失函数的值,
为第t-1步损失函数值,要使
,则需要
,此处
为当前模型的负梯度值,即第t步的回归树需要拟合的值。
至于GBDT的具体算法流程,在后续回归与分类问题会分开说明。
三、损失函数
在GBDT算法中,损失函数的选择十分重要。针对不同的问题,损失函数有不同的选择。
1.对于分类算法,其损失函数一般由对数损失函数和指数损失函数两种。
(1)指数损失函数表达式:
(2)对数损失函数可分为二分类和多分类两种。
2.对于回归算法,常用损失函数有如下4种。
(1)平方损失函数:
(2)绝对损失函数:
对应负梯度误差为:
(3)Huber损失,它是均方差和绝对损失的折中产物,对于远离中心的异常点,采用绝对损失误差,而对于靠近中心的点则采用平方损失。这个界限一般用分位数点度量。损失函数如下
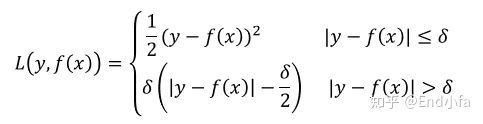
对应的负梯度误差为:
(4)分位数损失。它对应的是分位数回归的损失函数,表达式为:
其中 为分位数,需要我们在回归之前指定。对应的负梯度误差为:
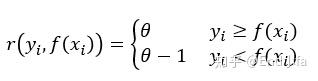
对于Huber损失和分位数损失,主要用于健壮回归,也就是减少异常点对损失函数的影响。
四、回归问题
梯度提升算法(回归问题)流程:
--------------------------------------------------------------------------------------------
输入:训练数据集T={ },
;损失函数L(y,f(x));
输出:回归树
(1)初始化
注:估计使损失函数极小化的常数值,它是只有一个根结点的树
(2)对m=1,2,...,M
(a)对i=1,2,...N,计算
注: 计算损失函数在当前模型的值,作为残差的估计
(b)对 拟合一个回归树,得到第m棵树的叶结点区域
,j=1,2,...,J
(c)对j=1,2,...,J,计算
注:在损失函数极小化条件下,估计出相应叶结点区域的值
(d)更新
(3)得到回归树
--------------------------------------------------------------------------------------------
五、分类问题(二分类与多分类)
这里看看GBDT分类算法,GBDT的分类算法从思想上和GBDT的回归算法没有区别,但是由于样本输出不是连续的值,而是离散的类别,导致我们无法直接从输出类别去拟合输出类别的误差。
为了解决这个问题,主要有两个方法,一个是用指数损失函数,此时GBDT退化为Adaboost算法。另一种方法用类似逻辑回归的对数似然函数的方法。也就是说,我们用的是类别的预测概率值和真实概率值的差来拟合损失。此处仅讨论用对数似然函数的GBDT分类。对于对数似然损失函数,我们有又有二元分类和的多元分类的区别。
1.二分类GBDT算法
对于二分类GBDT,如果用类似逻辑回归的对数似然损失函数,则损失函数为:
其中 {-1,1}。此时的负梯度误差为:
对于生成的决策树,我们各个叶子节点的最佳负梯度拟合值为
由于上式比较难优化,我们一般使用近似值代替
除了负梯度计算和叶子节点的最佳负梯度拟合的线性搜索,二分类GBDT与GBDT回归算法过程相同。
2.多分类GBDT算法
多分类GBDT比二分类GBDT复杂些,对应的是多元逻辑回归和二元逻辑回归的复杂度差别。假设类别数为K,则此时我们的对数似然损失函数为:
其中如果样本输出类别为k,则 =1.第k类的概率
的表达式为:
集合上两式,我们可以计算出第t轮的第i个样本对应类别l的负梯度误差为:
观察上式可以看出,其实这里的误差就是样本i对应类别l的真实概率和t-1轮预测概率的差值。
对于生成的决策树,我们各个叶子节点的最佳负梯度拟合值为:
由于上式比较难优化,我们一般使用近似值代替
除了负梯度计算和叶子节点的最佳负梯度拟合的线性搜索,多分类GBDT与二分类GBDT以及GBDT回归算法过程相同。
六、正则化
- 对GBDT进行正则化来防止过拟合,主要有三种形式。
1.给每棵数的输出结果乘上一个步长a(learning rate)。
对于前面的弱学习器的迭代:
加上正则化项,则有
此处,a的取值范围为(0,1]。对于同样的训练集学习效果,较小的a意味着需要更多的弱学习器的迭代次数。通常我们用步长和迭代最大次数一起决定算法的拟合效果。
2.第二种正则化的方式就是通过子采样比例(subsample)。取值范围为(0,1]。
GBDT这里的做法是在每一轮建树时,样本是从原始训练集中采用无放回随机抽样的方式产生,与随机森立的有放回抽样产生采样集的方式不同。若取值为1,则采用全部样本进行训练,若取值小于1,则不选取全部样本进行训练。选择小于1的比例可以减少方差,防止过拟合,但可能会增加样本拟合的偏差。取值要适中,推荐[0.5,0.8]。
3.第三种是对弱学习器即CART回归树进行正则化剪枝。(如控制树的最大深度、节点的最少样本数、最大叶子节点数、节点分支的最小样本数等)
七、GBDT优缺点
1.GBDT优点
- 可以灵活处理各种类型的数据,包括连续值和离散值。
- 在相对较少的调参时间情况下,预测的准确率也比较高,相对SVM而言。
- 在使用一些健壮的损失函数,对异常值得鲁棒性非常强。比如Huber损失函数和Quantile损失函数。
2.GBDT缺点
- 由于弱学习器之间存在较强依赖关系,难以并行训练。可以通过自采样的SGBT来达到部分并行。
八、sklearn参数
在scikit-learning中,GradientBoostingClassifier对应GBDT的分类算法,GradientBoostingRegressor对应GBDT的回归算法。
具体算法参数情况如下:
GradientBoostingRegressor(loss=’ls’, learning_rate=0.1, n_estimators=100,
subsample=1.0, criterion=’friedman_mse’, min_samples_split=2,
min_samples_leaf=1, min_weight_fraction_leaf=0.0, max_depth=3,
min_impurity_decrease=0.0, min_impurity_split=None, init=None,
random_state=None, max_features=None, alpha=0.9, verbose=0,
max_leaf_nodes=None, warm_start=False, presort=’auto’,
validation_fraction=0.1, n_iter_no_change=None, tol=0.0001)
参数说明:
- n_estimators:弱学习器的最大迭代次数,也就是最大弱学习器的个数。
- learning_rate:步长,即每个学习器的权重缩减系数a,属于GBDT正则化方化手段之一。
- subsample:子采样,取值(0,1]。决定是否对原始数据集进行采样以及采样的比例,也是GBDT正则化手段之一。
- init:我们初始化的时候的弱学习器。若不设置,则使用默认的。
- loss:损失函数,可选{'ls'-平方损失函数,'lad'绝对损失函数-,'huber'-huber损失函数,'quantile'-分位数损失函数},默认'ls'。
- alpha:当我们在使用Huber损失"Huber"和分位数损失"quantile"时,需要指定相应的值。默认是0.9,若噪声点比较多,可适当降低这个分位数值。
- criterion:决策树节搜索最优分割点的准则,默认是"friedman_mse",可选"mse"-均方误差与'mae"-绝对误差。
- max_features:划分时考虑的最大特征数,就是特征抽样的意思,默认考虑全部特征。
- max_depth:树的最大深度。
- min_samples_split:内部节点再划分所需最小样本数。
- min_samples_leaf:叶子节点最少样本数。
- max_leaf_nodes:最大叶子节点数。
- min_impurity_split:节点划分最小不纯度。
- presort:是否预先对数据进行排序以加快最优分割点搜索的速度。默认是预先排序,若是稀疏数据,则不会预先排序,另外,稀疏数据不能设置为True。
- validationfraction:为提前停止而预留的验证数据比例。当n_iter_no_change设置时才能用。
- n_iter_no_change:当验证分数没有提高时,用于决定是否使用早期停止来终止训练。
八、GBDT应用场景
GBDT几乎可以用于所有回归问题(线性/非线性),相对loigstic regression仅能用于线性回归,GBDT的适用面非常广。亦可用于分类问题。
转载:GBDT算法梳理的更多相关文章
- 进阶:2.GBDT算法梳理
GBDT算法梳理 学习内容: 1.前向分布算法 2.负梯度拟合 3.损失函数 4.回归 5.二分类,多分类 6.正则化 7.优缺点 8.sklearn参数 9.应用场景 1.前向分布算法 在学习模型时 ...
- GBDT算法梳理
1.GBDT(Gradient Boosting Decision Tree)思想 Boosting : 给定初始训练数据,由此训练出第一个基学习器: 根据基学习器的表现对样本进行调整,在之前学习器做 ...
- GBDT算法原理深入解析
GBDT算法原理深入解析 标签: 机器学习 集成学习 GBM GBDT XGBoost 梯度提升(Gradient boosting)是一种用于回归.分类和排序任务的机器学习技术,属于Boosting ...
- 机器学习系列------1. GBDT算法的原理
GBDT算法是一种监督学习算法.监督学习算法需要解决如下两个问题: 1.损失函数尽可能的小,这样使得目标函数能够尽可能的符合样本 2.正则化函数对训练结果进行惩罚,避免过拟合,这样在预测的时候才能够准 ...
- 机器学习技法-GBDT算法
课程地址:https://class.coursera.org/ntumltwo-002/lecture 之前看过别人的竞赛视频,知道GBDT这个算法应用十分广泛.林在第八讲,简单的介绍了AdaBoo ...
- 工业级GBDT算法︱微软开源 的LightGBM(R包正在开发....)
看完一篇介绍文章后,第一个直觉就是这算法已经配得上工业级属性.日前看到微软已经公开了这一算法,而且已经发开python版本,本人觉得等hadoop+Spark这些平台配齐之后,就可以大规模宣传啦~如果 ...
- GBDT 算法:原理篇
本文由云+社区发表 GBDT 是常用的机器学习算法之一,因其出色的特征自动组合能力和高效的运算大受欢迎. 这里简单介绍一下 GBDT 算法的原理,后续再写一个实战篇. 1.决策树的分类 决策树分为两大 ...
- GBDT算法
GBDT通过多轮迭代,每轮迭代产生一个弱分类器,其中弱分类器通常选择为CART树,每个分类器在上一轮分类器的残差基础上进行训练. 对于GBDT算法,其中重要的知识点为: 1.GBDT是梯度下降法从参数 ...
- 梯度提升树GBDT算法
转自https://zhuanlan.zhihu.com/p/29802325 本文对Boosting家族中一个重要的算法梯度提升树(Gradient Boosting Decison Tree, 简 ...
随机推荐
- ethereumjs/ethereumjs-account-2-test
ethereumjs-account/test/index.js const Account = require('../index.js') const tape = require('tape') ...
- centos安装swoole
编译安装swoole: cd && wget https://github.com/swoole/swoole-src/archive/1.8.6-stable.tar.gz ...
- JVM(二)GC算法和垃圾收集器
前言 垃圾收集器(Garbage Collection)通常被成为GC,诞生于1960年MIT的Lisp语言.上一篇介绍了Java运行时区域的各个部分,其中程序计数器.虚拟机栈.本地方法栈3个区域随线 ...
- json2.js的作用与使用示例
工作中,如果公司要求你兼容ie6.7,那么你可以辞职了,开个玩笑: 关于json,本文不作介绍,介绍一下json字符串和对象的相互转换: 在各大主浏览器及ie8+,我们可以使用内置方法JSON.str ...
- 学习笔记·斜率优化 [HNOI2008]玩具装箱
\(qwq\)今天\(rqy\)给窝萌这些蒟蒻讲了斜率优化--大概是他掉打窝萌掉打累了吧顺便偷了\(rqy\)讲课用的图 \(Step \ \ 1\) 一点小转化 事实上斜率优化是专门用来处理这样一类 ...
- HDU 1074 Doing Homework 状压dp(第一道入门题)
Doing Homework Time Limit: 2000/1000 MS (Java/Others) Memory Limit: 65536/32768 K (Java/Others)To ...
- kubernetes 日志定制查阅 - 排错 -- 好用的命令
You can use kubectl logs to retrieve logs from a previous instantiation of a container with --previo ...
- CentOS 6.4 编译安装 gcc 4.8.1
今天在isocpp上看到“GCC 4.8.1 released, C++11 feature complete”这个消息,非常兴奋.终于有一个全面支持C++11语言特性的编译器了! 当然了,gcc仅仅 ...
- virtualbox虚拟机与物理机windows文件共享
必须安装virtualbox的增强功能包(VBoxGuestAdditions) 1.打开Linux系统,选择 设备->安装增强增强功能 2.等待其自动安装,当出现press return to ...
- Linux文本编辑器-vi/vim
vi是Linux命令行界面下的文字编辑器,vim是vi的增强版(Vi IMproved),完全兼容 可以理解成普通的txt文本与word文档之间的差距. 注:还有一款全屏编辑器是nano,可以了解下 ...