text2pcap: 将hex转储文本转换为Wireshark可打开的pcap文件
简介
Text2pcap是一个读取ASCII hex转储的程序,它将描述的数据写入pcap或pcapng文件。text2pcap可以读取包含多个数据包的hexdumps,并构建多个数据包的捕获文件。text2pcap还能够生成虚拟以太网,IP和UDP,TCP或SCTP标头,以便仅从应用级数据的hexdump构建完全可处理的数据包转储。
用法
该工具集成在Wireshark安装包中,进入DoS切换到Wireshark安装目录(缺省:C:\Program Files\Wireshark)。使用命令: text2pcap [选项] <输入文件名> <输出文件名>
选项
-o hex | oct | dec
指定偏移的基数(十六进制,八进制或十进制)。默认为十六进制。详细介绍见后文注意事项。
-t <timefmt>
将包之前的文本视为日期/时间码; timefmt是strptime(3)支持的排序格式字符串。示例:时间“10:15:14.5476”的格式代码为“%H:%M:%S”。如果不指定时间,则使用当前系统时间。
-n
以pcapng格式而不是pcap格式写入文件。缺省为pcap格式
-l
指定此数据包的链路层标头类型。缺省为以太网(1)。有关可能的封装的完整列表,请参见http://www.tcpdump.org/linktypes.html。 请注意,如果转储是封装数据包的完整十六进制转储,并且您希望指定确切的封装类型,则应使用此选项。示例:-l 7用于封装BSD样式的ARCNet数据包。
-m <max-packet>
设置最大数据包长度,默认为262144.
-h
帮助选项
当捕获报文为非完整数据实(比如只有应用层数据),可以使用以下选项对报文头进行构造:
-e <l3pid>
在每个数据包之前包含一个虚拟以太网报头。以十六进制指定以太网头的L3PID。如果您的dump具有第3层标头和有效负载(例如IP标头),但没有第2层封装,请使用此选项。示例:-e 0x806指定ARP数据包。对于IP数据包,您也可以使用-l 101来指示Wireshark的原始IP数据包,而不是生成虚假的以太网头。请注意,-l 101不适用于任何非IP第3层数据包(例如ARP),而使用-e生成虚拟以太网头适用于任何类型的L3数据包。
-i <proto>
在每个数据包之前包含虚拟IP头。以十进制指定数据包的IP协议。如果转储是IP数据包的有效负载(即具有完整的L4信息)但每个数据包没有IP头,请使用此选项。请注意,每个数据包也会自动包含适当的以太网标头。示例:-i 46指定RSVP数据包(IP协议46)。有关分配的Internet协议号的完整列表,请参见http://www.iana.org/assignments/protocol-numbers/protocol-numbers.xhtml。
-4 <srcip>,<destip>
使用指定的IPv4 目的和源地址预先添加虚拟IP头。此选项应附带以下选项之一:-i,-s,-S,-T,-u使用此选项可应用“自定义”IP地址。示例:-4 10.0.0.1,10.0.0.2对所有IP数据包使用10.0.0.1和10.0.0.2。
-6 <srcip>,<destip>
使用指定的IPv6目标和源地址预先添加虚拟IP头。此选项应附带以下选项之一:-i,-s,-S,-T,-u使用此选项可应用“自定义”IP地址。示例:-6 fe80 :: 202:b3ff:fe1e:8329,2001:0db8:85a3 :: 8a2e:0370:7334使用fe80 :: 202:b3ff:fe1e:8329和2001:0db8:85a3 :: 8a2e:0370 :7334表示所有IP数据包。
-T <srcport>,<destport>
在每个数据包之前包含虚拟TCP标头。以十进制指定数据包的源和目标TCP端口。如果转储是数据包的TCP有效负载但不包含任何TCP,IP或以太网标头,请使用此选项。请注意,每个数据包都会自动包含适当的以太网和IP标头。序号将从0开始。
-u <srcport>,<destport>
在每个数据包之前包含虚拟UDP标头。以十进制指定数据包的源和目标UDP端口。如果转储是数据包的UDP有效负载但不包含任何UDP,IP或以太网标头,请使用此选项。请注意,每个数据包都会自动包含适当的以太网和IP标头。示例:-u1000,69使数据包看起来像TFTP / UDP数据包。
说明
一个标准的hex dump报文应该如下:

如上图所示是wireshark官方文档中的hex dump示例,标红的地方即为偏移量(offset),缺省为16进制,每一个新数据包以偏移量0开头第一行一共16字节,因此第二行的偏移量为16,对应到十六进制即为:0x00010。
此外还有几个地方需要注意:
1、每行的宽度或字节数没有限制。此外,行末尾的文本转储也会被忽略。
2、字节/十六进制数可以是大写或小写。
3、忽略偏移之前的任何文本,包括电子邮件转发字符'>'。
4、字节串行之间的任何文本行都将被忽略。
5、偏移量用于跟踪字节,因此偏移量必须正确。
6、任何只有字节而没有前导偏移的行都将被忽略。
7、偏移被识别为长于两个字符的十六进制数。
8、忽略字节后的任何文本(例如字符转储),此文本中的任何十六进制数也会被忽略。
9、偏移量为零表示启动新数据包,因此具有一系列hexdumps的单个文本文件可以转换为具有多个数据包的抓包文件。
示例
接下来通过root-me上的一道题目演示如何将hex dump文本转换为pcap文件。题目地址为:https://www.root-me.org/en/Challenges/Network/ETHERNET-frame ,其中所涉及到的报文为:
00 05 73 a0 00 00 e0 69 95 d8 5a 13 86 dd 60 00
00 00 00 9b 06 40 26 07 53 00 00 60 2a bc 00 00
00 00 ba de c0 de 20 01 41 d0 00 02 42 33 00 00
00 00 00 00 00 04 96 74 00 50 bc ea 7d b8 00 c1
d7 03 80 18 00 e1 cf a0 00 00 01 01 08 0a 09 3e
69 b9 17 a1 7e d3 47 45 54 20 2f 20 48 54 54 50
2f 31 2e 31 0d 0a 41 75 74 68 6f 72 69 7a 61 74
69 6f 6e 3a 20 42 61 73 69 63 20 59 32 39 75 5a
6d 6b 36 5a 47 56 75 64 47 6c 68 62 41 3d 3d 0d
0a 55 73 65 72 2d 41 67 65 6e 74 3a 20 49 6e 73
61 6e 65 42 72 6f 77 73 65 72 0d 0a 48 6f 73 74
3a 20 77 77 77 2e 6d 79 69 70 76 36 2e 6f 72 67
0d 0a 41 63 63 65 70 74 3a 20 2a 2f 2a 0d 0a 0d
0a
根据提示可知该报文为以太网类型的报文,我们可以使用缺省参数进行转换而无需通过-l指定链路层类型。
结合上一节中的说明可知,该报文没有设置偏移字段,因此我们需要手工设置偏移字段,偏移字段需要大于2个字符,这里我们设置成4个字符,报文的开始偏移量一定要设置为0,每行16个字节,正好第二位加一:
0000 00 05 73 a0 00 00 e0 69 95 d8 5a 13 86 dd 60 00
0010 00 00 00 9b 06 40 26 07 53 00 00 60 2a bc 00 00
0020 00 00 ba de c0 de 20 01 41 d0 00 02 42 33 00 00
0030 00 00 00 00 00 04 96 74 00 50 bc ea 7d b8 00 c1
0040 d7 03 80 18 00 e1 cf a0 00 00 01 01 08 0a 09 3e
0050 69 b9 17 a1 7e d3 47 45 54 20 2f 20 48 54 54 50
0060 2f 31 2e 31 0d 0a 41 75 74 68 6f 72 69 7a 61 74
0070 69 6f 6e 3a 20 42 61 73 69 63 20 59 32 39 75 5a
0080 6d 6b 36 5a 47 56 75 64 47 6c 68 62 41 3d 3d 0d
0090 0a 55 73 65 72 2d 41 67 65 6e 74 3a 20 49 6e 73
00a0 61 6e 65 42 72 6f 77 73 65 72 0d 0a 48 6f 73 74
00b0 3a 20 77 77 77 2e 6d 79 69 70 76 36 2e 6f 72 67
00c0 0d 0a 41 63 63 65 70 74 3a 20 2a 2f 2a 0d 0a 0d
00d0 0a
00d1
将以上报文保存到txt文本,使用缺省参数进行转换:
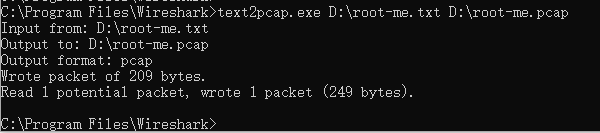
此时我们使用wireshark打开刚刚生成的pcap文件:
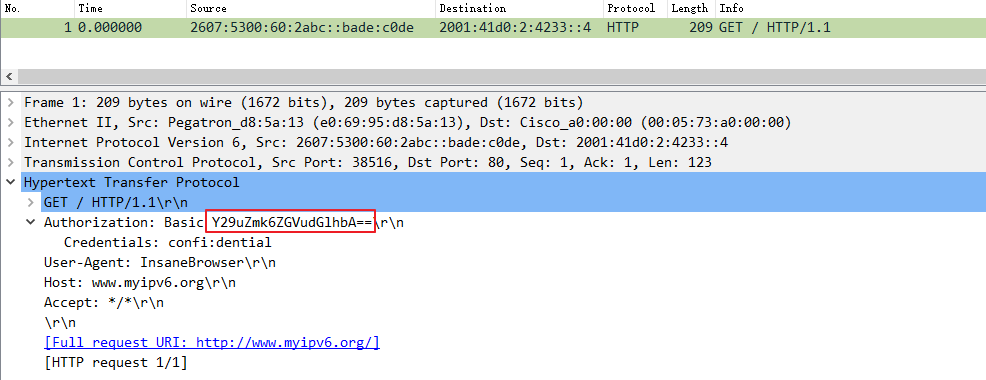
可以看到报文被完整的解析出来,上图中标红的字段经过base64解码后即为该题目的password。
另外一种方法亦可将hex dump文本解析为pcap。打开wireshark——点击文件——从hex转储文件导入:

如果手工设置了或者hex转储文件自带偏移量则可以选择偏移量为16进制,如果hex dump文件没有偏移值则偏移量选择无也可以正常导入文件:

参考资料:https://www.wireshark.org/docs/man-pages/text2pcap.html
text2pcap: 将hex转储文本转换为Wireshark可打开的pcap文件的更多相关文章
- JSON文本转换为JSONArray 转换为 List<Object>
package com.beijxing.TestMain; import java.io.File; import java.io.IOException; import java.util.Arr ...
- 利用Code128字体将文本转换为code128条形码
利用Code128字体将文本转换为code128条形码[转] 最近在做仓储的项目,许多的打印文件都包含条形码,之前一直使用C39P24DhTt字体直接转换为39码,但是最近要求使用code128编 ...
- 将txt文本转换为excel格式
将txt文本转换为excel格式,中间使用的列分割为 tab 键 一.使用xlwt模块 注:Excel 2003 一个工作表行数限制65536,列数限制256 需要模块:xlwt 模块安装:xlwt ...
- 用Excel如何将文本转换为数字的七种方法
用Excel如何将文本转换为数字的七种方法 当下,很多工作都会用到Excel,下面本文分步介绍了如何将包含文本的Excel单元格转换为包含数字的单元格. 概述: 当导入在另一程序(如 dBASE 或 ...
- 一招教你如何在Python中使用Torchmoji将文本转换为表情符号
很难找到关于如何使用Python使用DeepMoji的教程.我已经尝试了几次,后来又出现了几次错误,于是决定使用替代版本:torchMoji. TorchMoji是DeepMoji的pyTorch实现 ...
- 将rgb表示方式转换为hex表示方式-------------将hex表示方式转换为rgb表示方式(这里返回rgb数组组合)
/** * kevin 2021.1.4 * 将rgb表示方式转换为hex表示方式 * @param {string} rgbColor 传过来的hex格式的颜色 * @returns { ...
- 【Azure 环境】在Windows环境中抓取网络包(netsh trace)后,如何转换为Wireshark格式以便进行分析
问题描述 如何在Windows环境中,不安装第三方软件的情况下(使用Windows内置指令),如何抓取网络包呢?并且如何转换为Wireshark 格式呢? 操作步骤 1) 以管理员模式打开CMD,使用 ...
- 将 Word 文本转换为表格
文本转换为表格的功能,首先点击"插入"选项卡"表格"组中的"表格"下拉按钮,打开下拉列表中选择"文本转换成表格"选项.
- Qt文本读写之一:输入输出设备和文件操作
一.输入输出设备 QIODevice类是Qt中所有I/O设备的基础接口类,为诸如QFile.QBuffer和 QTcpSocket等支持读/写数据块的设备提供了一个抽象接口.QIODevice类是抽象 ...
随机推荐
- 又拍云叶靖:OpenResty 在又拍云存储中的应用
2019 年 7 月 6 日,OpenResty 社区联合又拍云,举办 OpenResty × Open Talk 全国巡回沙龙·上海站,又拍云平台开发部负责人叶靖在活动上做了<OpenRest ...
- 11、增强型for循环对二维数组的输出(test8.java)
由于笔者原因,这部分知识,尚不能整理出代码,笔者会好好学习增强型for循环中迭代起的相关知识,在笔者有能力,书写好这段代码后,将对本篇文章,进行二次修改,也同时欢迎大家与笔者交流,共同学习,共同进步. ...
- C语言编程入门之--第五章C语言基本运算和表达式-part2
5.1.4 再来一个C库函数getchar吸收回车键 回车键也是一个字符,在使用scanf的时候,输入完毕要按下回车键,这时候回车键也会被输入到stdin流中,会搞乱我们的程序. 注意:stdin是输 ...
- scapy构造打印ARP数据包
ARP格式: 用于以太网的ARP请求/应答分组格式 各字段含义: 帧类型:表示数据部分用什么协议封装(0800表示IP,0806表示ARP,8035表示RARP). 硬件类型:表示硬件地址的类型(其中 ...
- Python3基本数据类型之列表
1.初识列表 列表(List)是Python3中的"容器型"数据类型. 列表通过中括号把一堆数据括起来的方式形成,列表的长度不限. 列表里面的元素可以是不同的数据类型,但是一般是相 ...
- MYSQL--表与表之间的关系、修改表的相关操作
表与表之间的操作: 如果所有信息都在一张表中: 1.表的结构不清晰 2.浪费硬盘空间 3.表的扩展性变得极差(致命的缺点) 确立表与表之间的关系.一定要换位思考(必须在两者考虑清楚之后才能得出结论) ...
- ElasticSearch:常用的基础查询与过滤器
match_all(获取所有索引文档) quert_string(获取包含指定关键字文档) 默认查询_all字段,_all字段是由所有字段组合而成的,可以通过description:关键字,获取通过请 ...
- python 28 网络协议
目录 网络协议 1. C/S.B/S 架构 1.1 C/S 架构: 1.2 B/S 架构: 2. 网络通信原理 3. OSI七层协议(TCP/IP五层): 3.1 物理层: 3.2 数据链路层: 3. ...
- egret之纹理填充模式(上下填充)
首先,我们准备两张图片,一张作为背景“瓶子”,一张作位填充物“饮料”. 在皮肤里我们设置右边图片的填充模式为“repeat”,修改Y的缩放为:-1.,调整图片位置使之与地图重合,如下: 现在,我们可以 ...
- 【IDEA】在IDEA中使用@Slf4j报错,找不到log
题:在IDEA中使用@Slf4j报错,找不到log 解决方法:需要在IDEA中安装插件lombok 详细步骤: 1.File->Settings 2.Plugins->Browse rep ...