深度研究:回归模型评价指标R2_score
回归模型的性能的评价指标主要有:RMSE(平方根误差)、MAE(平均绝对误差)、MSE(平均平方误差)、R2_score。但是当量纲不同时,RMSE、MAE、MSE难以衡量模型效果好坏。这就需要用到R2_score,实际使用时,会遇到许多问题,今天我们深度研究一下。
预备知识
搞清楚R2_score计算之前,我们还需要了解几个统计学概念。
若用$y_i$表示真实的观测值,用$\bar{y}$表示真实观测值的平均值,用$\hat{y_i}$表示预测值,则:
回归平方和:SSR
$$SSR = \sum_{i=1}^{n}(\hat{y_i} - \bar{y})^2$$
即估计值与平均值的误差,反映自变量与因变量之间的相关程度的偏差平方和
残差平方和:SSE
$$SSE = \sum_{i=1}^{n}(y_i-\hat{y_i} )^2$$
即估计值与真实值的误差,反映模型拟合程度
总离差平方和:SST
$$SST =SSR + SSE= \sum_{i=1}^{n}(y_i - \bar{y})^2$$
即平均值与真实值的误差,反映与数学期望的偏离程度
R2_score计算公式
R^2 score,即决定系数,反映因变量的全部变异能通过回归关系被自变量解释的比例。计算公式:
$$R^2=1-\frac{SSE}{SST}$$
即
$$R^2 = 1 - \frac{\sum_{i=1}^{n} (y_i - \hat{y}_i)2}{\sum_{i=1}{n} (y_i - \bar{y})^2}$$
进一步化简
$$R^2 = 1 - \frac{\sum\limits_i(y_i - y_i)^2 / n}{\sum\limits_i(y_i - \hat{y})^2 / n} = 1 - \frac{RMSE}{Var}$$
分子就变成了常用的评价指标均方误差MSE,分母就变成了方差。
对于$R^2$可以通俗地理解为使用均值作为误差基准,看预测误差是否大于或者小于均值基准误差。
R2_score = 1,样本中预测值和真实值完全相等,没有任何误差,表示回归分析中自变量对因变量的解释越好。
R2_score = 0。此时分子等于分母,样本的每项预测值都等于均值。
R2_score不是r的平方,也可能为负数(分子>分母),模型等于盲猜,还不如直接计算目标变量的平均值。
r2_score使用方法
根据公式,我们可以写出r2_score实现代码
1- mean_squared_error(y_test,y_preditc)/ np.var(y_test)
也可以直接调用sklearn.metrics中的r2_score
sklearn.metrics.r2_score(y_true, y_pred, sample_weight=None, multioutput='uniform_average')
#y_true:观测值
#y_pred:预测值
#sample_weight:样本权重,默认None
#multioutput:多维输入输出,可选‘raw_values’, ‘uniform_average’, ‘variance_weighted’或None。默认为’uniform_average’;
raw_values:分别返回各维度得分
uniform_average:各输出维度得分的平均
variance_weighted:对所有输出的分数进行平均,并根据每个输出的方差进行加权。
sklearn.metrics.r2_score使用方法
import matplotlib.pyplot as plt
import numpy as np
from sklearn import datasets, linear_model
from sklearn.metrics import r2_score
#导入数据
diabetes_X, diabetes_y = datasets.load_diabetes(return_X_y=True)
diabetes_X = diabetes_X[:, np.newaxis, 2]
#划分测试集验证集
diabetes_X_train = diabetes_X[:-20]
diabetes_X_test = diabetes_X[-20:]
diabetes_y_train = diabetes_y[:-20]
diabetes_y_test = diabetes_y[-20:]
# 创建线性回归模型
regr = linear_model.LinearRegression()
# 训练模型
regr.fit(diabetes_X_train, diabetes_y_train)
# 预测
diabetes_y_pred = regr.predict(diabetes_X_test)
# 模型评价
print('r2_score: %.2f'
% r2_score(diabetes_y_test, diabetes_y_pred))
# 绘制预测效果图
plt.scatter(diabetes_X_test, diabetes_y_test, color='black')
plt.plot(diabetes_X_test, diabetes_y_pred, color='blue', linewidth=3)
plt.xticks(())
plt.yticks(())
plt.show()
r2_score: 0.47
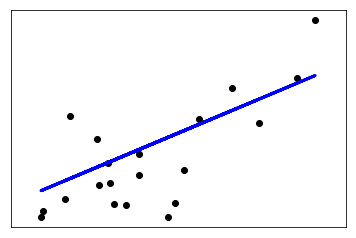
r2_score偏小,预测效果一般。
注意事项
1、$R^2$ 一般用在线性模型中(非线性模型也可以用)
2、$R^2$不能完全反映模型预测能力的高低,某个实际观测的自变量取值范围很窄,但此时所建模型的R2 很大,但这并不代表模型在外推应用时的效果肯定会很好。
3、数据集的样本越大,R²越大,因此,不同数据集的模型结果比较会有一定的误差,此时可以使用Adjusted R-Square (校正决定系数),能对添加的非显著变量给出惩罚:
$$R2_{\text{Adj}}=1-(1-R2)\frac{n-p-1}{n-1}$$
n是样本的个数,p是变量的个数
Reference
https://scikit-learn.org
https://zhuanlan.zhihu.com/p/36305931
https://www.jianshu.com/p/9ee85fdad150
https://blog.csdn.net/Dear_D/article/details/86144696
https://blog.csdn.net/shy19890510/article/details/79375062
深度研究:回归模型评价指标R2_score的更多相关文章
- 深度学习实践系列(1)- 从零搭建notMNIST逻辑回归模型
MNIST 被喻为深度学习中的Hello World示例,由Yann LeCun等大神组织收集的一个手写数字的数据集,有60000个训练集和10000个验证集,是个非常适合初学者入门的训练集.这个网站 ...
- 回归模型的性能评价指标(Regression Model Performance Evaluation Metric)
回归模型的性能评价指标(Performance Evaluation Metric)通常有: 1. 平均绝对误差(Mean Absolute Error, MAE):真实目标y与估计值y-hat之间差 ...
- 如何在R语言中使用Logistic回归模型
在日常学习或工作中经常会使用线性回归模型对某一事物进行预测,例如预测房价.身高.GDP.学生成绩等,发现这些被预测的变量都属于连续型变量.然而有些情况下,被预测变量可能是二元变量,即成功或失败.流失或 ...
- SPSS数据分析—配对Logistic回归模型
Lofistic回归模型也可以用于配对资料,但是其分析方法和操作方法均与之前介绍的不同,具体表现 在以下几个方面1.每个配对组共有同一个回归参数,也就是说协变量在不同配对组中的作用相同2.常数项随着配 ...
- Poisson回归模型
Poisson回归模型也是用来分析列联表和分类数据的一种方法,它实际上也是对数线性模型的一种,不同点是对数线性模型假定频数分布为多项式分布,而泊松回归模型假定频数分布为泊松分布. 首先我们来认识一下泊 ...
- logistic回归模型
一.模型简介 线性回归默认因变量为连续变量,而实际分析中,有时候会遇到因变量为分类变量的情况,例如阴性阳性.性别.血型等.此时如果还使用前面介绍的线性回归模型进行拟合的话,会出现问题,以二分类变量为例 ...
- 机器学习之路:python 集成回归模型 随机森林回归RandomForestRegressor 极端随机森林回归ExtraTreesRegressor GradientBoostingRegressor回归 预测波士顿房价
python3 学习机器学习api 使用了三种集成回归模型 git: https://github.com/linyi0604/MachineLearning 代码: from sklearn.dat ...
- Spark机器学习5·回归模型(pyspark)
分类模型的预测目标是:类别编号 回归模型的预测目标是:实数变量 回归模型种类 线性模型 最小二乘回归模型 应用L2正则化时--岭回归(ridge regression) 应用L1正则化时--LASSO ...
- Softmax回归——logistic回归模型在多分类问题上的推广
Softmax回归 Contents [hide] 1 简介 2 代价函数 3 Softmax回归模型参数化的特点 4 权重衰减 5 Softmax回归与Logistic 回归的关系 6 Softma ...
随机推荐
- Can't connect to MySQL server on 'localhost' (10061),连接Navicat报错问题解决
今天,装了Mysql 1.1.7后,连接Navicat 时报错,后来找了一阵,发现问题所在. 原因是我在安装时把默认端口号3306修改成了3303, 连接时,把默认端口也修改下就好啦.
- 识别手写数字增强版100% - pytorch从入门到入道(一)
手写数字识别,神经网络领域的“hello world”例子,通过pytorch一步步构建,通过训练与调整,达到“100%”准确率 1.快速开始 1.1 定义神经网络类,继承torch.nn.Modul ...
- C语言程序设计100例之(8):尼科彻斯定理
例8 尼科彻斯定理 题目描述 尼科彻斯定理可以叙述为:任何一个整数的立方都可以表示成一串连续的奇数的和.需要注意的是,这些奇数一定是连续的,如:1,3,5,7,9,…. 例如,对于整数5,5*5 ...
- python函数的基本语法<一>
函数: 一次定义,多次调用,函数可以变相看成变量函数的阶段: 1.定义阶段 2调用阶段 形参和实参: 定义阶段的参数叫形参,调用阶段的参数叫实参 函数的几种基本用法: #多变量 def test(na ...
- C语言程序设计100例之(10):最大公约数
例10 最大公约数 问题描述 有三个正整数a,b,c(0<a,b,c<10^6),其中c不等于b.若a和c的最大公约数为b,现已知a和b,求满足条件的最小的c. 输入数据 第 ...
- netty服务端的创建
服务端的创建 示例代码 netty源码中有一个netty-example项目,不妨以经典的EchoServer作为楔子. // 步骤1 EventLoopGroup bossGroup = new N ...
- 力扣(LeetCode)二进制求和 个人题解
给定两个二进制字符串,返回他们的和(用二进制表示). 输入为非空字符串且只包含数字 1 和 0. 示例 1: 输入: a = "11", b = "1" 输出: ...
- python:类5——Python 的类的下划线命名有什么不同?
首先是单下划线开头,这个被常用于模块中,在一个模块中以单下划线开头的变量和函数被默认当作内部函数,如果使用 from a_module import * 导入时,这部分变量和函数不会被导入.不过值得注 ...
- oracle实现"limit"功能
转载于http://blog.sina.com.cn/s/blog_67e2758d0100s3oc.html oracle数据库不支持mysql中limit功能,但可以通过rownum来限制返回的结 ...
- 【故障公告】数据库服务器 CPU 近 100% 引发的故障(源于 .NET Core 3.0 的一个 bug)
非常抱歉,这次故障给您带来麻烦了,请您谅解. 今天早上 10:54 左右,我们所使用的数据库服务(阿里云 RDS 实例 SQL Server 2016 标准版)CPU 突然飙升至 90% 以上,应用日 ...