[Spark] 03 - Programming
入门知识
PySpark MLlib
一、基本介绍
这里是MLlib,但目前推荐使用ml库直接针对DataFrame,这里使用老库,主要是为了“了解”。
Apache Spark提供了一个名为 MLlib 的机器学习API。PySpark也在Python中使用这个机器学习API。它支持不同类型的算法,如下所述
mllib.classification - spark.mllib 包支持二进制分类,多类分类和回归分析的各种方法。分类中一些最流行的算法是 随机森林,朴素贝叶斯,决策树 等。
mllib.clustering - 聚类是一种无监督的学习问题,您可以根据某些相似概念将实体的子集彼此分组。
mllib.fpm - 频繁模式匹配是挖掘频繁项,项集,子序列或其他子结构,这些通常是分析大规模数据集的第一步。 多年来,这一直是数据挖掘领域的一个活跃的研究课题。
mllib.linalg - 线性代数的MLlib实用程序。
mllib.recommendation - 协同过滤通常用于推荐系统。 这些技术旨在填写用户项关联矩阵的缺失条目。
spark.mllib - 它目前支持基于模型的协同过滤,其中用户和产品由一小组可用于预测缺失条目的潜在因素描述。 spark.mllib使用交替最小二乘(ALS)算法来学习这些潜在因素。
mllib.regression - 线性回归属于回归算法族。 回归的目标是找到变量之间的关系和依赖关系。使用线性回归模型和模型摘要的界面类似于逻辑回归案例。
二、代码示范
提供了一个简单的数据集。
使用数据集 - test.data 1,1,5.0
1,2,1.0
1,3,5.0
1,4,1.0
2,1,5.0
2,2,1.0
2,3,5.0
2,4,1.0
3,1,1.0
3,2,5.0
3,3,1.0
3,4,5.0
4,1,1.0
4,2,5.0
4,3,1.0
4,4,5.0
数据集
from __future__ import print_function
from pyspark import SparkContext
# 这里使用了mllib,比较老的api,最新的是ml。
from pyspark.mllib.recommendation import ALS, MatrixFactorizationModel, Rating
if __name__ == "__main__":
sc = SparkContext(appName="Pspark mllib Example")
data = sc.textFile("test.data") # 训练模型
ratings = data.map(lambda s: s.split(',')).map(lambda x: Rating(int(x[0]), int(x[1]), float(x[2])))
rank = 10
numIterations = 10
model = ALS.train(ratings, rank, numIterations) # 测试模型
testdata = ratings.map(lambda p: (p[0], p[1]))
predictions = model.predictAll(testdata).map(lambda r: ((r[0], r[1]), r[2]))
ratesAndPreds = ratings.map(lambda r: ((r[0], r[1]), r[2])).join(predictions)
MSE = ratesAndPreds.map(lambda r: (r[1][0] - r[1][1])**2).mean()
print("Mean Squared Error = " + str(MSE)) # Save and load model
model.save(sc, "target/tmp/myCollaborativeFilter")
sameModel = MatrixFactorizationModel.load(sc, "target/tmp/myCollaborativeFilter")
三、spark.ml 库
Ref: http://spark.apache.org/docs/latest/ml-guide.html
As of Spark 2.0, the RDD-based APIs in the spark.mllib package have entered maintenance mode. The primary Machine Learning API for Spark is now the DataFrame-based API in the spark.ml package.
- spark.mllib: 数据抽象是rdd。
- spark.ml: 数据抽象是dataframe。
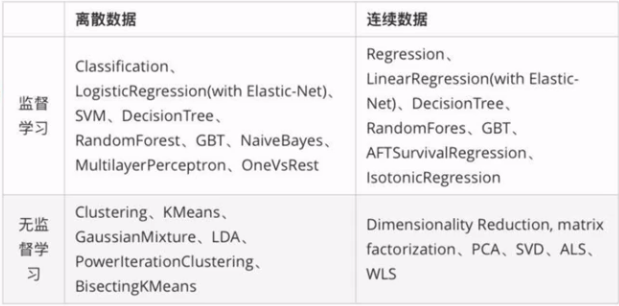
NLP基础
一、TF-IDF 单词的重要性
第一步,分拆单词,构成单词集合
from pyspark.ml.feature import HashingTF, IDF, Tokenizer
sentenceData = spark.createDataFrame([
(0, "..."),
(1, "..."),
...
]).toDF("label", "sentence") tokenizer = Tokenizer(inputCol="sentence", outputCol="words")
wordsData = tokenizer.transform(sentenceData)
wordsData.show()
可见,多出了最后一列:

第二步,Hash成为特征向量
hashingTF = HashingTF(inputCol="words", outputCol="rawFeatures", numFeatures=2000)
featurizedData = hashingTF.transform(wordsData)
featurizedData.select("words", "rawFeatures").show(truncate=False)
第三步,IDF构造
idf = IDF(InputCol="rawFeatures", outputCol="features")
idfModel = idf.fit(featurizedData)
第四步,调权重
rescaledData = idfModel.transform(featurizedData)
rescaledData.select("feature", "label").show(truncate=False)
二、Word2Vec 单词的向量化
org.apache.spark.ml.feature包:
- StringIndexer
- IndexToString
- OneHotEncoder
- VectorIndexer
方法一,StringIndexer
频率最高的为0。IndexToString(),是反操作。
from pyspark.ml.feature import StringIndexer # 构建一个DataFrame, 设置StringIndexer的输入列和输出列的名字
df = spark.createDataFrame([(0, "a"), (1, "b"), (2, "c"), (3, "a"), (4, "a"), (5, "c")], ["id", "category"])
indexer = StringIndexer(inputCol="category", outputCol="categoryIndex") # 训练并转换
model = indexer.fit(df)
indexed = model.transform(df) indexed.show()

方法二,VectorIndexer
from pyspark.ml.feature import VectorIndexer
from pyspark.ml.linalg import Vector, Vectors df = spark.createDataFrame([ \
(Vectors.dense(-1.0, 1.0, 1.0), ),
(Vectors.dense(-1.0, 3.0, 1.0), ),
(Vectors.dense( 0.0, 5.0, 1.0), )], ["features"]) indexer = VectorIndexer(inputCol="features", outputCol="indexed", maxCategories=2)
indexerModel = indexer.fit(df)
categoricalFeatures = indexerModel.categoryMaps.keys()
转换后查看。
indexed = indexerModel.transform(df)
indexed.show()
第一列,只有两种,认为是类别特征,故转换;
第二列,有三种,不认为是类别特征,故保持;
第三列,只有一种,认为是列别特征,故转换。

工作流 Pipeline
Logistic 回归分类器
(1) 获得 SparkSesson
from pyspark.sql import SparkSession
spark = SparkSession.builder.master("local").appName("WordCount").getOrCreate()
(2) 准备 train 数据

(3) 构建流水线
tokenizer = Tokenizer(inputCol="text", outputCol="words")
hashingTF = HashingTF(inputCol=tokenizer.getOutputCol(), outputCol="features")
lr = LogisticRegression(maxIter=10, regParam=0.001) pipeline = Pipeline(stages=[tokenizer, hashingTF, lr])
model = pipeline.fit(training)
(4) 测试并预测

开始预测以上这些数据,得到预测结果。
prediction = model.transform(test)
selected = prediction.select("id", "text", "probability", "prediction") for row in selected.collect():
rid, text, prob, prediction= row
print("(%d, %s) --> prob=%s, prediction=%f" % (rid, text, str(prob), prediction))玩儿
决策树分类器
(1) 引用包

(2) 构造数据
def f(x):
rel = {}
rel['feature'] = Vectors.dense(float(x[0]), float(x[1]), float(x[2]), float(x[3]))
ref['label'] = str(x[4])
return rel data = spark.sparkContext.textFile("file:///usr/local/spark/iris.txt").
map(lambda line: line.split(',')).
map(lambda p: Row(**f(p))).
toDF() # 成为二维表
(3) 转换器

(4) 分类模型
dtClassfier = DecisionTreeClassifier(). \
setLabelCol("indexedLabel"). \
setFeaturesCol("indexedFeatures")
(5) 构建流水线
dtPipeline = Pipeline().setStages([labelIndexer, featureIndexer, dtClassifier, labelConverter]) dtPipelineModel = dtPipeline.fit(trainingData)
dtPredictions = dtPipelineModel.transform(testData)
dtPredictions.select("predictedLabel", "label", "features").show(20)

(6) 评估模型
evaluator = MulticlassClassificationEvaluator(). \
setLabelCol("indexedLabel"). \
setPredictionCol("prediction") dtAccuracy = evaluator.evaluate(dtPredictions)
AWS ETL Pipeline
一、学习资源
Ref: 使用 AWS Glue 和 Amazon Athena 实现无服务器的自主型机器学习
Ref: AWS Glue 常见问题
Extract is the process of reading data from a database. In this stage, the data is collected, often from multiple and different types of sources.
Transform is the process of converting the extracted data from its previous form into the form it needs to be in so that it can be placed into another database. Transformation occurs by using rules or lookup tables or by combining the data with other data.
Load is the process of writing the data into the target database.
二、代码示范
ETL具备pipeline的思想,这里没用,但可以加上。
import sys
from awsglue.utils import getResolvedOptions
from awsglue.context import GlueContext
from awsglue.job import Job
from awsglue.transforms import SelectFields
from awsglue.transforms import RenameField
from awsglue.dynamicframe import DynamicFrame, DynamicFrameReader, DynamicFrameWriter, DynamicFrameCollection
from pyspark.context import SparkContext
from pyspark.ml.regression import LinearRegression
from pyspark.ml.feature import VectorAssembler
from pyspark.ml.regression import LinearRegression
from pyspark.ml.clustering import KMeans args = getResolvedOptions(sys.argv, ['JOB_NAME']) #JOB INPUT DATA
destination = "s3://luiscarosnaprds/gluescripts/results/ClusterResults3.parquet"
namespace = "nyc-transportation-version2"
tablename = "green"
# 固定套路
sc = SparkContext()
glueContext = GlueContext(sc)
job = Job(glueContext)
job.init(args['JOB_NAME'], args) #Load table and select fields
datasource0 = glueContext.create_dynamic_frame.from_catalog(name_space = namespace, table_name = tablename) SelectFields0 = SelectFields.apply(frame = datasource0, paths=["trip_distance","fare_amount","pickup_longitude","pickup_latitude" ])
DataFrame0 = DynamicFrame.toDF(SelectFields0) # 变成了二维表
#------------------------------------------------------------
#Filter some unwanted values
DataFrameFiltered = DataFrame0.filter("pickup_latitude > 40.472278 AND pickup_latitude < 41.160886 AND pickup_longitude > -74.300074 AND pickup_longitude < -71.844077")
#Select features and convert to SparkML required format
features = ["pickup_longitude","pickup_latitude"]
assembler = VectorAssembler(inputCols=features,outputCol='features')
assembled_df = assembler.transform(DataFrameFiltered) #Fit and Run Kmeans
kmeans = KMeans(k=100, seed=1)
model = kmeans.fit(assembled_df)
transformed = model.transform(assembled_df) #Save data to destination
transformed.write.mode('overwrite').parquet(destination)
job.commit()
End.
[Spark] 03 - Programming的更多相关文章
- Spark Streaming Programming Guide
参考,http://spark.incubator.apache.org/docs/latest/streaming-programming-guide.html Overview SparkStre ...
- <Spark><Advanced Programming>
Introduction 介绍两种共享变量的方式: accumulators:聚集信息 broadcast variables:高效地分布large values 介绍对高setup costs任务的 ...
- spark第六篇:Spark Streaming Programming Guide
预览 Spark Streaming是Spark核心API的扩展,支持高扩展,高吞吐量,实时数据流的容错流处理.数据可以从Kafka,Flume或TCP socket等许多来源获取,并且可以使用复杂的 ...
- [Spark] 07 - Spark Streaming Programming
Streaming programming 一.编程套路 编写Streaming程序的套路 创建DStream,也就定义了输入源. 对DStream进行一些 “转换操作” 和 "输出操作&q ...
- [Spark] Scala programming - basic level
环境配置 IDE: https://www.jetbrains.com/idea/ 子雨大数据之Spark入门教程(Scala版) /* implement */ 语言特性 Online compil ...
- [AI] 深度数据 - Data
Data Engineering Data Pipeline Outline [DE] How to learn Big Data[了解大数据] [DE] Pipeline for Data Eng ...
- Spark踩坑记——数据库(Hbase+Mysql)
[TOC] 前言 在使用Spark Streaming的过程中对于计算产生结果的进行持久化时,我们往往需要操作数据库,去统计或者改变一些值.最近一个实时消费者处理任务,在使用spark streami ...
- Spark Streaming容错的改进和零数据丢失
本文来自Spark Streaming项目带头人 Tathagata Das的博客文章,他现在就职于Databricks公司.过去曾在UC Berkeley的AMPLab实验室进行大数据和Spark ...
- sparklyr包--实现R与Spark接口
1.sparklyr包简介 Rstudio公司发布的sparklyr包具有以下几个功能: 实现R与Spark的连接: sparklyr包提供了一个完整的dplyr后端,可筛选并聚合Spark数据集,接 ...
随机推荐
- Windows Server 2008磁盘管理
下面学习一下磁盘管理,基本磁盘 分区 空间只能是同一块磁盘的空间,动态磁盘 卷 空间可以是多块硬盘上的空间,怎么创建 RAID-0 条带卷 读写快 无容错 适合存放不太重要的数据 ,RAID-1 ...
- 番茄日志发布1.0.3版本-增加Kafka支持
番茄日志(TomatoLog)能做什么 可能你是第一次听说TomatoLog,没关系,我可以从头告诉你,通过了解番茄日志,希望能帮助有需要的朋友,番茄日志处理将大大降低你采集.分析.处理日志的过程. ...
- 【记录】SpringBoot 2.X整合Log4j没有输出INFO、DEBUG等日志信息解决方案
由于批量更新的时候一直无法定位问题出处,就去服务器定位日志,奈何日志一直无法输出,为了能够更好的定位问题,痛定思痛后逐步排查最终解决问题.如有客官看到此处,请不要盲目对号入座,我的项目环境或许与你有区 ...
- windows安装elasticsearch服务以及elasticsearch5.6.10集群的配置(elasticsearch5.6.10配置跟1.1.1的配置不太相同,有些1.1.1版本下的配置指令在5.6.10中不能使用)
1.下载elasticsearch5.6.10安装包 下载地址为: https://artifacts.elastic.co/downloads/elasticsearch/elasticsearc ...
- java短信验证和注册
最近公司需要用到短信验证注册,所以申请了阿里云的短信服务.我的项目是分布式的spring boot 原理: 利用第三方发送短信 获取回执消息,然后存入缓存里面 将用户填写的验证码与缓存里面的验证码对比 ...
- java学习之- 线程运行状态
标签(空格分隔): 线程运行状态 线程的运行状态: 如下是是我编写的一个图,大家可以作为参考: 1.new一个thread子类也是创建了一个线程: 2.创建完毕之后start()-----运行, 3. ...
- 使用jQuery.extend创建一个简单的选项卡插件
选项卡样式如图,请忽略丑陋的样式,样式可以随意更改 主要是基于jquery的extend扩展出的一个简单的选项卡插件,注意:这里封装的类使用的是es6中的class,所以不兼容ie8等低版本浏览器呦! ...
- FZU - 1914
题意略. 思路: 我们应该着重关注负数对当前数列的影响,由于前缀和的性质,我们都是从当前数字向前加,这其实也是在枚举以哪个下标作为开头. 详见代码: #include<stdio.h> # ...
- Java基础之多态和泛型浅析
Java基础之多态和泛型浅析 一.前言: 楼主看了许多资料后,算是对多态和泛型有了一些浅显的理解,这里做一简单总结 二.什么是多态? 多态(Polymorphism)按字面的意思就是“多种状态”.在面 ...
- Springboot学习与mybatis逆向生成工具
最近H2数据库越用越觉得方便,在不同办公处无缝继续demo的感觉就是爽. 今天接上一篇Springboot简洁整合mybatis,补上sts(即eclipse)使用mybatis generato ...