python爬虫登陆问题
根据腾讯课堂网页登陆问题进行解说(需要安装谷歌浏览器):
1、导入库
import requests
from selenium import webdriver
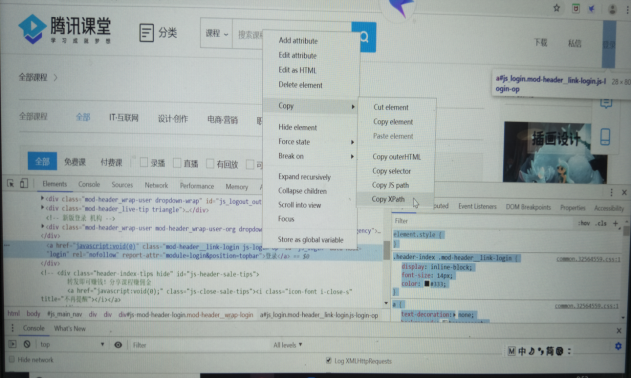
2、根据腾讯课堂链接,进入页面,获取页面中登陆的xpath,并进行点击操作。

获取xpath的方法是:在如上所示箭头所指登陆位置右击操作,点击检查,获取以下页面。在登陆所在标签处右击进行复制xpath。
driver = webdriver.Chrome()
driver.get("https://ke.qq.com/course/403521")
driver.find_element_by_xpath('//*[@id="js_login"]').click()
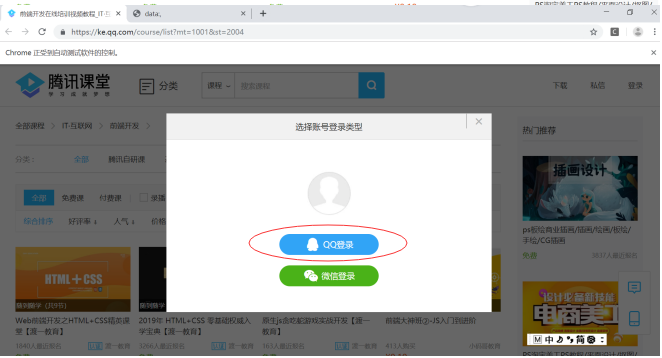
3、进入登陆页面之后获取登陆方式,本次选择使用qq进行登陆,获取qq登陆的xpath并进行点击操作。
driver.find_element_by_xpath('/html/body/div[4]/div/div[2]/div[2]/a[1]').click()
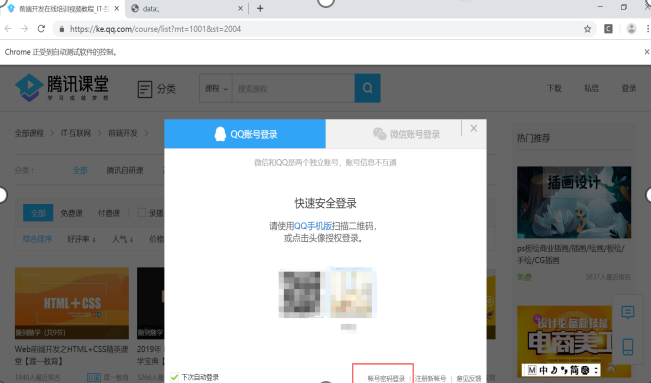
4、点击使用账号密码登陆。在该登陆过程中出现以下错误。

主要原因是无法找到我们定位的xpath,需要先找到定位元素所处的frame,并从frame中寻找该元素。
driver.switch_to_frame("login_frame_qq")//引号中添加frame标签中的name或id值
driver.find_element_by_xpath('//*[@id="switcher_plogin"]').click()
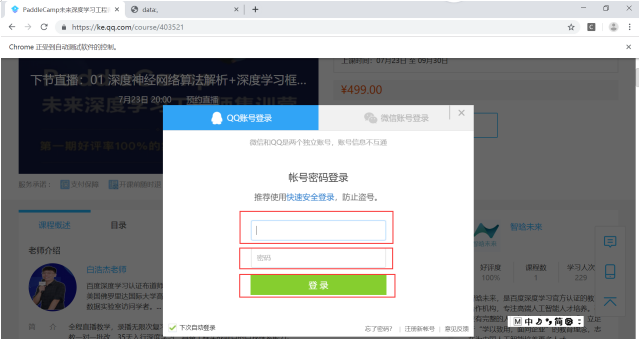
5、获取到输入账号密码以及登陆位置的xpath。当运行时再次出现定位不到xpath的情况,使用第四步的方法依旧没能成功,提示所在框架不对,估计是跟第4步的frame标签的name相同的原因吧。最后的解决方法是:先回到最外层框架,之后进入要定位元素的框架,最后对账号密码进行定位。
driver.switch_to.default_content()//回到最外层框架
driver.switch_to_frame("login_frame_qq")//进入定位元素的框架
driver.find_element_by_xpath('//*[@id="u"]').clear()
driver.find_element_by_xpath('//*[@id="u"]').send_keys("输入自己的账号")
driver.find_element_by_xpath('//*[@id="p"]').clear()
driver.find_element_by_xpath('//*[@id="p"]').send_keys("输入自己的密码")
6、点击登陆按钮,至此就已经进入网页版的腾讯课堂了。
driver.find_element_by_xpath('//*[@id="login_button"]').click()
完整代码如下:
import requests
from selenium import webdriver driver = webdriver.Chrome()
driver.get("https://ke.qq.com/course/403521")
driver.find_element_by_xpath('//*[@id="js_login"]').click()
time.sleep(5)//等待响应
driver.find_element_by_xpath('/html/body/div[4]/div/div[2]/div[2]/a[1]').click()
time.sleep(2)
driver.switch_to_frame("login_frame_qq")//引号中添加frame标签中的name或id值
driver.find_element_by_xpath('//*[@id="switcher_plogin"]').click()
time.sleep(2)
driver.switch_to.default_content()//回到最外层框架
driver.switch_to_frame("login_frame_qq")//进入定位元素的框架
driver.find_element_by_xpath('//*[@id="u"]').clear()
driver.find_element_by_xpath('//*[@id="u"]').send_keys("输入自己的账号")
driver.find_element_by_xpath('//*[@id="p"]').clear()
driver.find_element_by_xpath('//*[@id="p"]').send_keys("输入自己的密码")
driver.find_element_by_xpath('//*[@id="login_button"]').click()
本次实验使用的是Jupyter进行的分段操作,如果合并代码进行实验应改变sleep时间,确保页面已经更新。如有问题,欢迎批评指正,谢谢。
python爬虫登陆问题的更多相关文章
- Python 爬虫模拟登陆知乎
在之前写过一篇使用python爬虫爬取电影天堂资源的博客,重点是如何解析页面和提高爬虫的效率.由于电影天堂上的资源获取权限是所有人都一样的,所以不需要进行登录验证操作,写完那篇文章后又花了些时间研究了 ...
- python爬虫模拟登陆
python爬虫模拟登陆 学习了:https://www.cnblogs.com/chenxiaohan/p/7654667.html 用的这个 学习了:https://www.cnblogs.co ...
- Python模拟登陆新浪微博
上篇介绍了新浪微博的登陆过程,这节使用Python编写一个模拟登陆的程序.讲解与程序如下: 1.主函数(WeiboMain.py): import urllib2 import cookielib i ...
- python爬虫成长之路(一):抓取证券之星的股票数据
获取数据是数据分析中必不可少的一部分,而网络爬虫是是获取数据的一个重要渠道之一.鉴于此,我拾起了Python这把利器,开启了网络爬虫之路. 本篇使用的版本为python3.5,意在抓取证券之星上当天所 ...
- python爬虫学习(7) —— 爬取你的AC代码
上一篇文章中,我们介绍了python爬虫利器--requests,并且拿HDU做了小测试. 这篇文章,我们来爬取一下自己AC的代码. 1 确定ac代码对应的页面 如下图所示,我们一般情况可以通过该顺序 ...
- python爬虫学习(6) —— 神器 Requests
Requests 是使用 Apache2 Licensed 许可证的 HTTP 库.用 Python 编写,真正的为人类着想. Python 标准库中的 urllib2 模块提供了你所需要的大多数 H ...
- python爬虫学习 —— 总目录
开篇 作为一个C党,接触python之后学习了爬虫. 和AC算法题的快感类似,从网络上爬取各种数据也很有意思. 准备写一系列文章,整理一下学习历程,也给后来者提供一点便利. 我是目录 听说你叫爬虫 - ...
- [Python爬虫] Selenium实现自动登录163邮箱和Locating Elements介绍
前三篇文章介绍了安装过程和通过Selenium实现访问Firefox浏览器并自动搜索"Eastmount"关键字及截图的功能.而这篇文章主要简单介绍如何实现自动登录163邮箱,同时 ...
- python爬虫抓网页的总结
python爬虫抓网页的总结 更多 python 爬虫 学用python也有3个多月了,用得最多的还是各类爬虫脚本:写过抓代理本机验证的脚本,写过在discuz论坛中自动登录自动发贴的脚本,写过自 ...
随机推荐
- 2-19-使用apache搭建web网站
1 搭建一台测试web服务器 案例: 部门内部搭建一台WEB服务器,采用的IP地址和端口为192.168.10.34:80,首页采用index.html 文件.管理员E-mail地址为 xuegod@ ...
- QT 窗体控件的透明度设置(三种方法)
整个窗体 当设置QT的窗体(QMainWindow, QDialog)时,直接用 targetForm->setWindowOpacity() 函数即可实现,效果为窗体及窗体内所有控件都透明 ...
- 在WPF中减少逻辑与UI元素的耦合
原文:在WPF中减少逻辑与UI元素的耦合 在WPF中减少逻辑与UI元素的耦合 周银辉 1, 避免在逻辑中引用界面元素,别把后台数据强加给UI 一个糟糕的案例 比如说主界 ...
- kafka 遇到的错
D:\cluster\kafka_2.->.\bin\windows\kafka-topics.bat --create --zookeeper localhost: --replication ...
- storm和kafka的wordCount
这个是在window环境下面安装的kafka 下载pom依赖 <dependency> <groupId>org.apache.storm</groupId> &l ...
- 数据库连接池之_c3p0
C3p0 1,手动设置参数 @Test public void demo1(){ Connection connection =null; PreparedStatement preparedStat ...
- Android零基础入门第77节:Activity任务栈和启动模式
通过前面的学习,Activity的基本使用都已掌握,接下来一起来学习更高级的一些内容. Android采用任务栈(Task)的方式来管理Activity的实例.当启动一个应用时,Android就会为之 ...
- 一个 Qt 显示图片的控件(继承QWidget,使用QPixmap记录图像,最后在paintEvent进行绘制,可缩放)
Qt 中没有专门显示图片的控件,通常我们会使用QLabel来显示图片.但是QLabel 显示图片的能力还是有点弱.比如不支持图像的缩放一类的功能,使用起来不是很方便.因此我就自己写了个简单的类. 我这 ...
- delphi控件安装(安装ODAC、TeeChart、TServerSocket、TWSocketServer、TComm)
一.oracle插件安装delphi7如何安装oracle access控件 假设ODAC主目录在 D:\dzj\odac Delphi7主目录在 D:\Program Files\Borland\D ...
- 95+强悍的jQuery图形效果插件
现在的网站越来越离不开图形,好的图像效果能让你的网站增色不少.通过JQuery图形效果插件可以很容易的给你的网站添加一些很酷的效果. 使用JQuery插件其实比想象的要容易很多,效果也超乎想象.在本文 ...