关于CDH集群spark的三种安装方式简述
一、spark的命令行模式
1.第一种进入方式:执行 pyspark进入,执行exit()退出
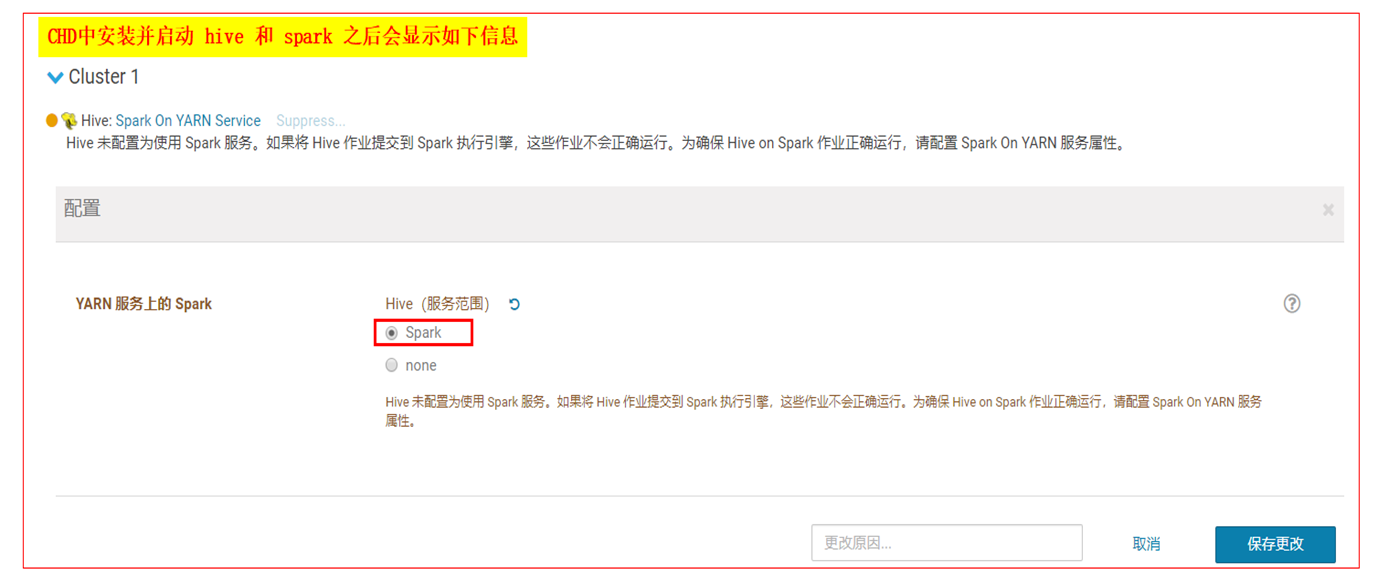
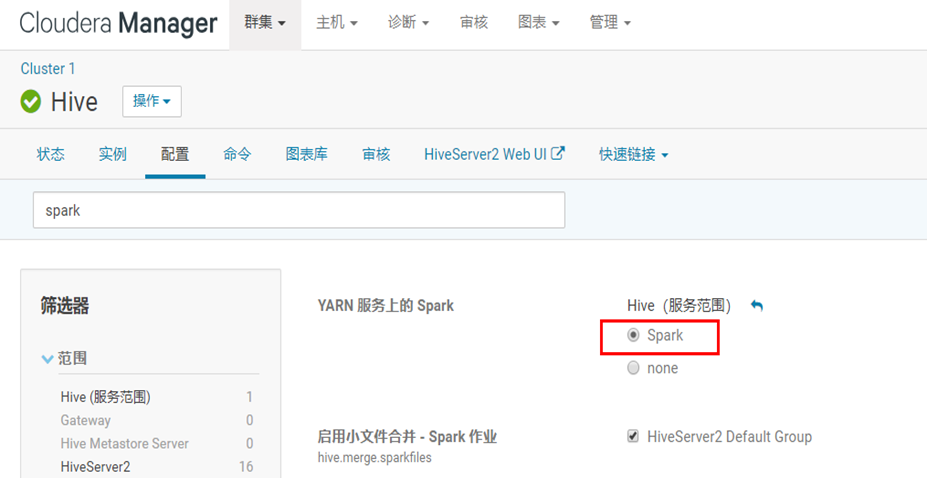
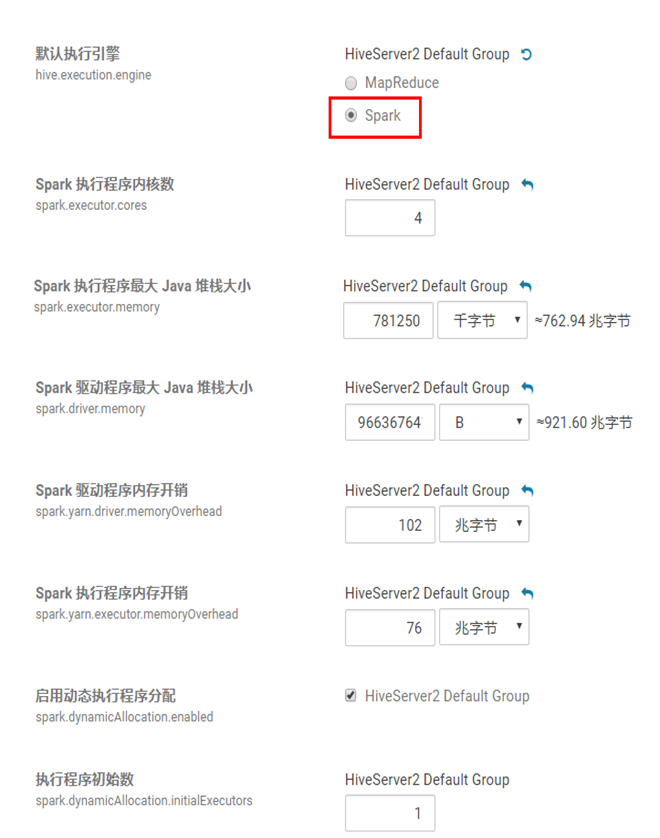
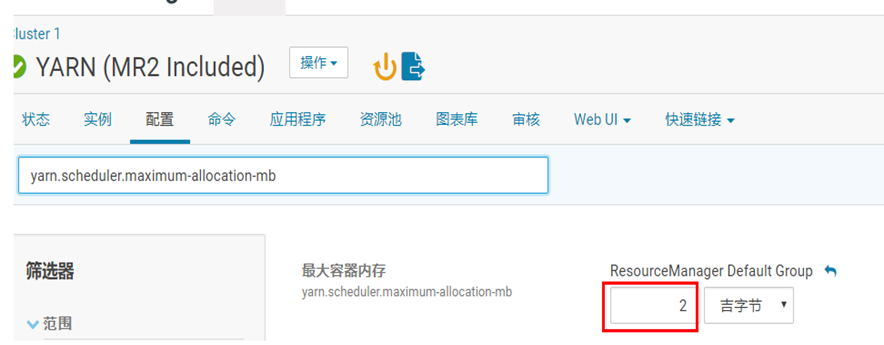
注意报错信息:java.lang.IllegalArgumentException: Required executor memory (1024+384 MB) is above the (最大阈值)max threshold (1024 MB) of this cluster!
表示 执行器的内存(1024+384 MB) 大于最大阈值(1024 MB)
Please check the values of 'yarn.scheduler.maximum-allocation-mb' and/or 'yarn.nodemanager.resource.memory-mb'

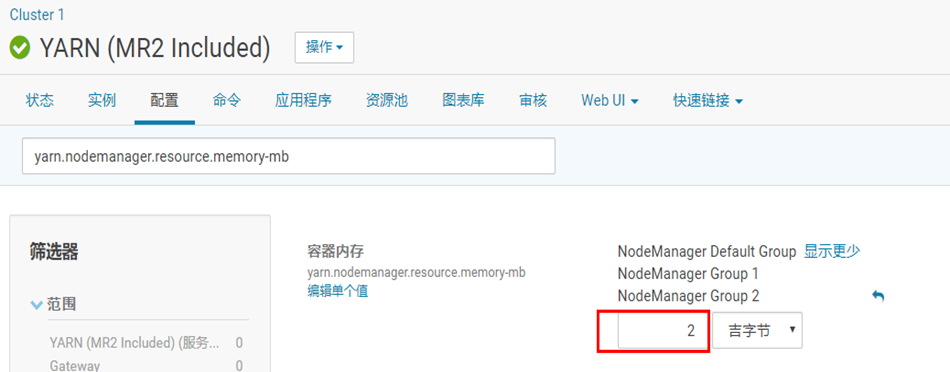
2.初始化RDD的方法
本地内存中已经有一份序列数据(比如python的list),可以通过sc.parallelize去初始化一个RDD。
当执行这个操作以后,list中的元素将被自动分块(partitioned),并且把每一块送到集群上的不同机器上。
import pyspark
from pyspark import SparkContext as sc
from pyspark import SparkConf
conf=SparkConf().setAppName("miniProject").setMaster("local[*]")
#任何Spark程序都是SparkContext开始的,SparkContext的初始化需要一个SparkConf对象,SparkConf包含了Spark集群配置的各种参数(比如主节点的URL)。
#初始化后,就可以使用SparkContext对象所包含的各种方法来创建和操作RDD和共享变量。
#Spark shell会自动初始化一个SparkContext(在Scala和Python下可以,但不支持Java)。
#getOrCreate表明可以视情况新建session或利用已有的session
sc=SparkContext.getOrCreate(conf)
# 利用list创建一个RDD;使用sc.parallelize可以把Python list,NumPy array或者Pandas Series,Pandas DataFrame转成Spark RDD。
rdd = sc.parallelize([1,2,3,4,5])
rdd 打印 ParallelCollectionRDD[0] at parallelize at PythonRDD.scala:195
# getNumPartitions() 方法查看list被分成了几部分
rdd.getNumPartitions() 打印结果:2
# glom().collect()查看分区状况
rdd.glom().collect() 打印结果: [[1, 2], [3, 4, 5]]
二、可直接执行 spark-shell,也可以执行 spark-shell --master local[2]
多线程方式:运行 spark-shell --master local[N] 读取 linux本地文件数据 。通过本地 N 个线程跑任务,只运行一个 SparkSubmit 进程,利用 spark-shell --master local[N] 读取本地数据文件实现单词计数master local[N]:采用本地单机版的来进行任务的计算,N是一个正整数,它表示本地采用N个线程来进行任务的计算,会生成一个SparkSubmit进程
关于CDH集群spark的三种安装方式简述的更多相关文章
- 减轻集群负载、三种k8s 替代openstack的解决方案
减轻集群负载.三种k8s 替代openstack的解决方案 待办 https://news.ycombinator.com/item?id=17013779 kubevirt https://host ...
- grub安装的 三种安装方式
1. 引言 grub是什么?最常态的理解,grub是一个bootloader或者是一个bootmanager,通过grub可以引导种类丰富的系统,如linux.freebsd.windows等.但一旦 ...
- 【转】vue.js三种安装方式
Vue.js(读音 /vjuː/, 类似于 view)是一个构建数据驱动的 web 界面的渐进式框架.Vue.js 的目标是通过尽可能简单的 API 实现响应的数据绑定和组合的视图组件.它不仅易于上手 ...
- vue.js三种安装方式
Vue.js(读音 /vjuː/, 类似于 view)是一个构建数据驱动的 web 界面的渐进式框架.Vue.js 的目标是通过尽可能简单的 API 实现响应的数据绑定和组合的视图组件.它不仅易于上手 ...
- Hive的三种安装方式(内嵌模式,本地模式远程模式)
一.安装模式介绍: Hive官网上介绍了Hive的3种安装方式,分别对应不同的应用场景. 1.内嵌模式(元数据保村在内嵌的derby种,允许一个会话链接,尝试多个会话链接时会报错) ...
- C++的三种继承方式简述
C++对父类(也称基类)的继承有三种方式,分别为:public继承.protected继承.private继承.三种继承方式的不同在于继承之后子类的成员函数的"可继承性质". 在说 ...
- 第1节 yarn:14、yarn集群当中的三种调度器
yarn当中的调度器介绍: 第一种调度器:FIFO Scheduler (队列调度器) 把应用按提交的顺序排成一个队列,这是一个先进先出队列,在进行资源分配的时候,先给队列中最头上的应用进行分配资源 ...
- Mongodb集群搭建的三种方式
转自:http://blog.csdn.net/luonanqin/article/details/8497860 MongoDB是时下流行的NoSql数据库,它的存储方式是文档式存储,并不是Key- ...
- Redis集群搭建的三种方式
一.Redis主从 1.1 Redis主从原理 和MySQL需要主从复制的原因一样,Redis虽然读取写入的速度都特别快,但是也会产生性能瓶颈,特别是在读压力上,为了分担压力,Redis支持主从复制. ...
随机推荐
- Spring学习之旅(十三)--使用NoSQL数据库
除了关系型数据库之外,现在还有一种 NoSQL 数据库非常流行,而 Spring 自然也没有放过对它的支持. NoSQL 数据库有很多种,如: MongoDBGenericJackson2JsonRe ...
- unity编辑器扩展_04(使用Selection获取选择的游戏物体)
代码: [MenuItem("Tools/GetChance", false, 1)] static void GetChance() { if (Sel ...
- CodeForces 989C
题意略. 思路:如图 详见代码: #include<bits/stdc++.h> #define maxn 55 using namespace std; char board[maxn] ...
- 🕸捕获与改写HTTPS请求
前言 本文站在 macOS 用户的角度下,分享一下对 HTTPS 进行请求拦截.对响应进行修改的经验. 要注意的是,本文介绍的工具虽然一定程度上对 Windows 用户也适用 ,但并非所有工具都是免费 ...
- HibernateSynchronizer的安装与使用
HibernateSynchronizer的作用是自动生成hibernate配置文件,即hibernate.cfg.xml文件,映射文件,Plain Object类文件和一些基础数据库操作文件. 安装 ...
- LR模型常见问题
信息速览 基础知识介绍-广义线性回归 逻辑斯蒂回归模型推导 逻辑斯蒂回归常见问题 补充知识信息点 基础知识: 机器学习对结果的形式分类: 分类算法 回归算法 LR:logistic regressio ...
- 1026-windy数+数位DP+记忆化搜索
1026: [SCOI2009]windy数 题意:数位DP模板题: 目前只理解了记忆化搜索,就想练练手, ------给递推写法留一个位子 ------ 注意这道题要判断前导0的情况,1 )可以加一 ...
- POJ 1797-Heavy Transportation-dijkstra小变形和POJ2253类似
传送门:http://poj.org/problem?id=1797 题意: 在起点和终点间找到一条路,使得经过的边的最小值是最大的: 和POJ2253类似,传送门:http://www.cnblog ...
- UVALive - 6667 Longest Chain CDQ3维问题
题意:现在有一个点堆, 一开始先给你m个点,然后再用题目中的rand函数生成剩下的n个点,问在这个点堆中可以找到的最长严格递增序列的长度是多少. 题解: 很常见的一个3维CDQ. 先按照z轴 sort ...
- 【Offer】[53-2] 【0~n-1中缺失的数字】
题目描述 思路分析 测试用例 Java代码 代码链接 题目描述 一个长度为n-1的递增排序数组中的所有数字都是唯一的,并且每个数字都在范围0~n-1之内.在范围0~n-1内的n个数字中有且只有一个数字 ...