elk安装与搭建
Elasticsearch安装配置
·下载elasticsearch.tar.gz包,解压压缩包。(此处为单机版es,集群请参考 https://www.cnblogs.com/lazycxy/p/9468074.html)
·创建ES用户和组(创建elsearch用户组及elsearch用户),因为使用root用户执行ES程序,将会出现错误;所以这里需要创建单独的用户去执行ES 文件;命令如下:
命令一:groupadd elsearch
命令二:useradd elsearch -g elsearch
命令三:chown -R elsearch:elsearch elasticsearch-5.6.3 //该命令是更改该文件夹下所属的用户组的权限
·修改ES的配置文件,使用cd命令进入到config 文件下,执行 vi elasticsearch.yml 命令
命令一:vi elasticsearch.yml
修改如图所示三处配置,保存退出。
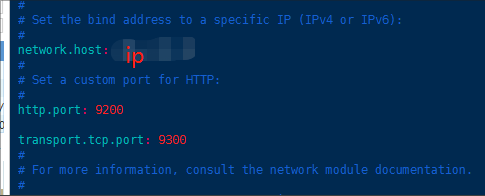
·切换到elsearch用户,启动elasticsearch;命令如下:
命令一:su elsearch
命令二:./elasticsearch (执行 ./elasticesrarch -d 是后台运行)
错误一:
此时会提示 vm.max_map_count [65530] is too low 这个值设置的太小,需要修改vm.max_map_count这个变量的值,切换到root用户修改配置sysctl.conf 增加配置值: vm.max_map_count=655360 执行命令 sysctl -p 这样就可以了,然后切到elsearch用户,重新启动ES服务 就可以了

错误二:
代表进程不够用了
解决方案: 切到root 用户:进入到security目录下的limits.conf;执行命令 vim /etc/security/limits.conf 在文件的末尾添加下面的参数值:
* soft nofile 65536
* hard nofile 131072
* soft nproc 2048
* hard nproc 4096

前面的*符号必须带上,然后重新启动服务器即可。执行完成后可以使用命令 ulimit -n 查看进程数
最终切换到elsearch用户,启动es服务即可。

Kibana安装配置
在浏览器中输入ip:port查看是否启动成功,如图所示,单机elasticsearch启动成功
·下载Kibana.tar.gz包,解压压缩包。
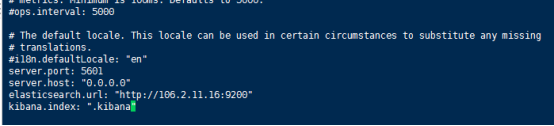
·修改kibana.yml配置文件
vim kibana.yml 编辑配置文件,在最后面加上如下配置就行:
server.port: 5601
server.host: "0.0.0.0"
elasticsearch.url: "http://ip:9200"
//这里ip:port要和es配置文件中填写的一致
kibana.index: ".kibana"
·启动完毕,可以浏览器输入url:服务器外网ip:5601 查看是否成功启动:· 启动服务:cd命令进入bin目录,执行sh kibana & 命令 后台启动kibana

logstash 安装配置
·下载logstash.tar.gz包,解压压缩包。
·进入bin目录,创建配置文件logstash1.conf
cd logstash-6.4.2/bin/进入bin目录
新建文件 vim logstash1.conf ,写入内容(监听tomcat的日志):
input {
file {
path => "tomcat应用目录/logs/*.log" //此处代表监控的日志文件
start_position => beginning
}
}
filter {
}
output {
elasticsearch {
hosts => "ip:9200"
}
}
启动logstash:sh logstash -f logstash1.conf
至此 elk的环境就安装好了,kibana怎么去统计分析日志,将在下一篇文章讲解
elk安装与搭建的更多相关文章
- spring mvc+ELK从头开始搭建日志平台
最近由于之前协助前公司做了点力所能及的事情,居然收到了一份贵重的端午礼物,是给我女儿的一个乐高积木,整个有7大包物件,我花了接近一天的时间一砖一瓦的组织起来,虽然很辛苦但是能够从过程中体验到乐趣.这次 ...
- ELK平台的搭建
ELK是指Elasticsearch + Logstash + Kibaba三个组件的组合.本文讲解一个基于日志文件的ELK平台的搭建过程,有关ELK的原理以及更多其他信息,会在接下来的文章中继续研究 ...
- ELK - MAC环境搭建
ELK - MAC环境搭建 本文旨在记录elasticsearch.logstash.kibana在mac下的安装与启动. 写在前面 ELK的官方文档对与它们的使用方法已经讲的非常清楚了,这里只对相关 ...
- [elk]停电日志离线恢复故障处理-elk环境极速搭建
es数据手动导入 周末停电了两天,发现两天的日志没导入: 原因: 1. elk开启没设启动 2.日志入库时间是当前时间,不是日志本身的time字段 - 导入步骤 1. 先把日志拖下来 2. 事先需要干 ...
- 搭建ELK日志分析平台(上)—— ELK介绍及搭建 Elasticsearch 分布式集群
笔记内容:搭建ELK日志分析平台(上)-- ELK介绍及搭建 Elasticsearch 分布式集群笔记日期:2018-03-02 27.1 ELK介绍 27.2 ELK安装准备工作 27.3 安装e ...
- ELK 安装Beat
章节 ELK 介绍 ELK 安装Elasticsearch ELK 安装Kibana ELK 安装Beat ELK 安装Logstash Beat是数据采集工具,安装在服务器上,将采集到的数据发送给E ...
- ELK扫盲及搭建
1. ELK部署说明 1.1ELK介绍: 1.1.1 ELK是什么? ELK是三个开源软件的缩写,分别表示:ElasticSearch , Logstash, Kibana , 它们都是开源软件,EL ...
- ELK+FileBeat+Log4Net搭建日志系统
ELK+FileBeat+Log4Net搭建日志系统 来源:https://www.zybuluo.com/muyanfeixiang/note/608470 标签(空格分隔): ELK Log4Ne ...
- ELK安装配置及nginx日志分析
一.ELK简介1.组成ELK是Elasticsearch.Logstash.Kibana三个开源软件的组合.在实时数据检索和分析场合,三者通常是配合使用,而且又都先后归于 Elastic.co 公司名 ...
随机推荐
- HHyperledger Fabric 之 TLS (fabric-java-sdk)使用grpcs方式访问fabric
我在很多fabric的技术群中,很多使用javasdk连接fabric的同友,初始的时候很多都没有成功的使用TLS进行区块链交易: 是sdk不支持,还是我们没有找到解决方案? 其实不然,我这里使用的是 ...
- C#开发OPC Client程序
前一段时间写了一个OPC Client程序,现在将简单介绍一下程序开发方法.测试环境最后将我写的程序开源到Github上去. 一.开发方法 我这里用的是一个OPC动态库OPCAutomation.dl ...
- MyEclipse 2016 Stable 1.0破解教程
一.下载所需文件 1. Windows最新版: MyEclipse 2016 Stable 1.0离线安装包(文件大小:1.52GB)--完整安装包,无需在线下载http://pan.baidu.co ...
- 《VR入门系列教程》之21---使用Unity开发GearVR应用
使用Unity开发GearVR应用 上一章我们介绍了如何运用Unity3D开发Oculus Rift应用,当然,这个便宜且强大的游戏引擎也可以用于GearVR的应用开发,这时我们需要用到Ocu ...
- 小白学python-day04-作业-九九乘法表相关
作业内容: 作业一: 作业二: 作业三: (1) (2) \n换行 \t制表符 end="" 代表打印不换行,双引号里面可以在结果之间加字符. print() 代表换行打印,使用时 ...
- 初学者的linux - 基本知识篇
1.Linux系统结构 Linux是一套免费使用和自由传播的类Unix操作系统,它是一种倒树结构. “/”就是系统的顶级目录,称作根目录,“/bin,/root,/home,/etc.."这 ...
- spring 注解验证@NotNull等使用方法
@Null 被注释的元素必须为null@NotNull 被注释的元素不能为null@AssertTrue 被注释的元素必须为true@AssertFalse 被注释的元素必须为false@Min(va ...
- Appium自动化测试环境搭建
前言 Appium是一个开源的自动化测试框架,支持跨平台,支持多种编程语言,可用于原生,混合和移动web应用程序,使用webdriver驱动ios,android应用程序.那么为了学习app自动化测试 ...
- 利用模板生成html页面(NVelocity)
公司的网站需要有些新闻,每次的新闻格式都是一样的,而不想每次都查询操作,所以想把这些新闻的页面保存成静态的html,之后搜索了下就找到了这个模板引擎,当然其他的模板引擎可以的,例如:Razor,自己写 ...
- Windows的 IIS 部署django项目
Windows的 IIS 部署django项目 1.安装Windows的IIS 功能(win10为例): (1)进入控制面板 :选择大图标 进入程序和功能 (2)启用或者关闭Windows功能 ...