Fcitx使用搜狗词库与皮肤
在 \(\texttt{Linux}\) 环境下,\(\texttt{Fcitx}\) 确实是最好用的开源输入法之一。然而 \(\texttt{Windows}\) 下的巨头输入法 —— 搜狗,对 \(\texttt{Linux}\) 的支持却并不算到位,迄今为止,大多数 \(\texttt{Linux}\) 的最新内核都无法使用搜狗,譬如 \(\texttt{Ubuntu 19.04}\) 。
所以,\(\texttt{Linux}\) 下原生的开源输入法,无疑是一切意外状况下最值得信赖的输入法。
不过,\(\texttt{Fcitx}\) 本身的拼音做得确实不好,如皮肤、词库等等,都远远不如搜狗输入法那么健全。
那么将搜狗的长处“拿来”,便是 \(\texttt{Linux}\) 用户自然而又令人愉悦的一个想法了。
搜狗词库使用
对于拼音用户而言,无论全双拼(音形除外),词库都是即为重要的。足够量的词库会极大降低你的选词时间!
Step1 下载搜狗词库
首先,第一件事情自然就是去到 搜狗输入法官网 下载你所需要的词库统一放到一个文件夹里去。
此时,文件夹的文件分布应该如下:
| filename.scel
| ...
| ...
| filename.scel
总之是一堆 scel 文件就是了。
Step2 scel -> org
如果你迫不及待地试图打开 scel 文件,你会发现根本读不了……
所以我们应当先将其转化为一个能正常阅读的格式 —— org。
首先,我们需要安装必需的工具:
sudo apt install fcitx-tools #ubuntu
sudo pacman -S fcitx-tools #arch
随后在目录下 mkdir org ,将转化后的文件放进去。随后执行如下 bash 命令来一一转化。
for scel in *.scels # 迭代器
do
scel2org ${scel} -o org/${scel}.org # 执行命令
done
随后你的 org 目录下就全是转化后的词库文件了,打开后是可读的!
此时,目录分布如下:
| filename.scel
| ...
| ...
| filename.scel
\ org
| filename.scel.org
| ...
| ...
| filename.scel.org
Step3 org -> mb -> fcitx
接下来就是将 org 文件转化成 \(\texttt{Fcitx}\) 可用文件的时候了!
首先 mkdir dict && cd dict 用来装最后的文件。
随后,我们需要将 默认词库 也下载下来。
接下来,执行转化命令:
cat ../org/*.org > tot.org
cat pyPhrase.org >> tot.org # 将所有词库汇总
sort tot.org > ord.org # 排序
uniq ord.org > final.org # 去重
最后的 final.org 就是我们的一个词库汇总了。
然后我们需要下载一个 字库 来最终合并。
执行 createPYMB gbkpy.org final.org 进行最后的转换。
之后会多出 pyERROR,pyPhrase.ok,pyphrase.mb,pybase.mb 几个文件,前两个没什么用,直接删掉没问题,剩下的 mb 文件就是我们的 \(\texttt{Fcitx}\) 词库文件了。
执行 mv *.mb ~/.config/fcitx/pinyin ,随后重启 \(\texttt{Fcitx}\) 即可。
搜狗皮肤使用
颜值也是及其重要的东西~
Fcitx 的默认皮肤就不像个人。
而搜狗的皮肤平台就十分壮观了,若能将搜狗的皮肤拿来用,体验确实好很多。
放点图,如果不想自己转换,想直接用我的资源请发邮件 CSYcaosiyu@gmail.com ,没人要的话我就懒得放了。
\(\texttt{Paper}\)
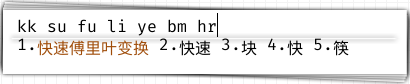
\(\texttt{简白}\)

\(\texttt{柔兰}\)

\(\texttt{晴天方格}\)

\(\texttt{洛天依}\)

Step1 下载皮肤与工具
先去 官网 下载皮肤。
然后 git clone https://github.com/VOID001/ssf2fcitx.git ,下载我们的开源工具(作者nb)。
sudo apt install cmake
cd ssf2fcitx
cmake ./
过程可能会有关 pkg 报错,作为合格的Linux用户当然是自己解决啦,执行 sudo apt install pkg-config 即可。
然后 make ,可能报错 unitypes.h not found ,直接 vim ssfextract.cpp ,删掉第 9 行的库引用即可。
最后 sudo make install
Step2 转化
其实作者的 github 上就有说明……
ssf2fcitx -i filename.ssf -o dirname 即可,随后 mv dirname ~/.config/fcitx/skin ,重启 \(\texttt{Fcitx}\) ,大功告成!
Fcitx使用搜狗词库与皮肤的更多相关文章
- Elementary OS 使用fcitx安装搜狗词库、搜狗输入法(Linux通用)
刚开始接触Linux的小伙伴可能比较懵逼,我要使用ibus输入法还是fcitx(小企鹅)输入法,其实这两种都不能说是输入法,Linux中输入法的使用是依赖于输入法框架的,其中搜狗输入法和百度输入法都是 ...
- 将搜狗词库.scel格式转化为.txt格式
由于项目中要用到词库,而下载的搜狗词库是.scel格式,所以就用python脚本将搜狗词库.scel格式文件转化为.txt格式文件. #!/bin/python # -*- coding: utf-8 ...
- CentOS安装搜狗词库
中文输入使用ibus-pinyin. 在ibus-pinyin里使用搜狗词库 # wget http://hslinuxextra.googlecode.com/files/sougou-phrase ...
- (转载)Windows下小狼毫输入法(Rime)的安装与配置(含导入搜狗词库)
div id="cnblogs_post_body" class="blogpost-body"> 最近彻底烦透了搜狗拼音输入法的各种流氓行为,自动升级不 ...
- 中州韵输入法(rime)导入搜狗词库
rime是一个非常优秀的输入法,linux平台下的反应速度远超搜狗,也没有隐私风险.2012年开始接触它,到后来抛弃了它,因为rime自带的词库真的太弱了,也懒得折腾.最近发现一个词库转换软件叫ime ...
- 解析搜狗词库(python)
#!/usr/bin/python # -*- coding: utf-8 -*- import struct import sys import binascii import pdb #搜狗的sc ...
- 将搜狗词库(.scel格式)转化为txt格式
参考:http://blog.csdn.net/zhangzhenhu/article/details/7014271 #!/usr/bin/python # -*- coding: utf-8 -* ...
- 使用Java将搜狗词库文件(文件后缀为.scel)转为.txt文件
要做一个根据词库进行筛选主要词汇的功能,去搜狗下载专业词汇词库时,发现是.scel文件,且通过转换工具(http://tools.bugscaner.com/sceltotxt/)转换为txt时报错如 ...
- 搜狗词库转txt
#环境需求 Python2 1 #!/bin/python # -*- coding: utf- -*- import struct import sys import binascii import ...
随机推荐
- CodeForces 103 D Time to Raid Cowavans
Time to Raid Cowavans 题意:一共有n头牛, 每头牛有一个重量,m次询问, 每次询问有a,b 求出 a,a+b,a+2b的牛的重量和. 题解:对于m次询问,b>sqrt(n) ...
- briup_jdbc自建工具类终极版
总结:此次构建工具类,难点在于查询,所需要的功能是 不管是 oracle还是mysql 都可以连接,并且 提供所需要的实体类,都可以将查询内容封装到实体类中去 遇到的难点 连接时,是从prppert ...
- grep : app :Is a directory
今天在查日志的时候用grep命令,遇到这样的一个问题,grep : app :Is a directory 用的grep命令是这样的:grep -10 '2019-08-14 21:22:39.252 ...
- Go操作kafka
Kafka是一种高吞吐量的分布式发布订阅消息系统,它可以处理消费者规模的网站中的所有动作流数据,具有高性能.持久化.多副本备份.横向扩展等特点.本文介绍了如何使用Go语言发送和接收kafka消息. s ...
- Vert.x 学习之MongoDB Client
Vert.x MongoDB Client 原文档:Vert.x MongoDB Client 组件介绍 您的 Vert.x 应用可以使用 Vert.x MongoDB Client(以下简称客户端) ...
- .Net基础篇_学习笔记_第六天_for循环的嵌套_乘法口诀表
using System; using System.Collections.Generic; using System.Linq; using System.Text; using System.T ...
- ActiveMQ的安装与使用。
1.什么是ActiveMQ ActiveMQ 是Apache出品,最流行的,能力强劲的开源消息总线.ActiveMQ 是一个完全支持JMS1.1和J2EE .4规范的 JMS Provider实现,尽 ...
- 松软科技课堂:SQL--RIGHTJOIN关键字
发布时间:2019/3/15 9:27:31 SQL RIGHT JOIN 关键字 RIGHT JOIN 关键字会右表 (table_name2) 那里返回所有的行,即使在左表 (table_name ...
- 安全性测试:OWASP ZAP 2.8 使用指南(三):ZAP代理设置
ZAP本地代理设置 如前文所言,ZAP的工作机制,是通过“中间代理”的形式实现. ZAP的代理设置可以从菜单中的:工具 - 选项 - Local Proxies加载. 在这里可以设置ZAP用来接受接入 ...
- 3分钟掌握GIt常用命令
一.常用命令 git config [-l] 配置 git --help 帮助 git diff 文件 比较文件修改的内容 git add . 添加当前目录所有文件到暂存区 git add --u ...