原生JS实现二叉搜索树(Binary Search Tree)
1.简述
二叉搜索树树(Binary Search Tree),它或者是一棵空树,或者是具有下列性质的二叉树: 若它的左子树不空,则左子树上所有结点的值均小于它的根结点的值; 若它的右子树不空,则右子树上所有结点的值均大于它的根结点的值; 它的左、右子树也分别为二叉排序树。
2.代码说明
首先先创建一个辅助节点类Node,它初始化了三个属性:节点值,左孩子,有孩子。
class Node {
constructor(value) {
this.value = value;
this.left = null;
this.right = null;
}
}
接着创建一个二叉搜索树类BST,它初始化了根节点为null。
class BST {
constructor() {
this.root = null;
}
}
然后,给这个BST类声明一些方法:
- insert(value):向树中插入一个节点值为value的节点。
- midOrderTraverse(callback):中序遍历树,并将树中的每个节点传入callback回调函数里。
- preOrderTraverse(callback):前序遍历树,并将树中的每个节点传入callback回调函数里。
- lastOrderTraverse(callback):后序遍历树,并将树中的每个节点传入callback回调函数里。
- minNodeInTree():查找树中节点值最小的节点。
- maxNodeInTree():查找树中节点值最大的节点。
- searchNodeInTree(value):判断树中是否存在某个节点值为value的节点
3.插入节点
要向树中插入一个新的节点(或项),要经历三个步骤。
- 第一步是创建用来表示新节点的Node类实例。只需要向构造函数传递我们想用来插入树的节点值,它的左指针和右指针的值会由构造函数自动设置为null。
- 第二步要验证这个插入操作是否为一种特殊情况。这个特殊情况就是我们要插入的节点是树的第一个节点。如果是,就将根节点指向新节点。
- 第三步是将节点加在非根节点的其他位置。
代码如下:
insert(value) {
var newNode = new Node(value);//实例化一个新节点
var root = this.root;
if (root == null) { //如果根节点不存在
this.root = newNode; //将这个新节点作为根节点
} else { //如果根节点存在
insertNode(root, newNode); //将这个新节点在根节点之后找到合适位置插入
}
}
如果是将节点加在非根节点的其他位置,那么这里为了方便起见,我们创建一个辅助函数:insertNode(node,newNode);
- 如果树非空,需要找到插入新节点的位置。因此,在调用insertNode方法时要通过参数传入树的根节点和要插入的节点。
- 如果新节点的键小于当前节点的键(现在,当前节点就是根节点),那么需要检查当前节点的左侧子节点。如果它没有左侧子节点,就在那里插入新的节点。如果有左侧子节点,需要通过递归调用insertNode方法继续找到树的下一层。在这里,下次将要比较的节点将会是当前节点的左侧子节点。
- 如果节点的键比当前节点的键大,同时当前节点没有右侧子节点,就在那里插入新的节点。如果有右侧子节点,同样需要递归调用insertNode方法,但是要用来和新节点比较的节点将会是右侧子节点。
/*
*函数名称:insertNode
*函数说明:将新节点newNode插入到node节点之后的合适位置
*函数参数:newNode,要插入的新节点
* node,node节点
*/
function insertNode(node, newNode) {
//如果newNode节点值小于node节点值,进入node节点左分支
if (newNode.value < node.value) {
//如果node节点左孩子为空
if (node.left == null) {
//将newNode赋给node节点左孩子,插入完毕。
node.left = newNode;
} else {
//如果node节点左孩子不为空,则继续向左孩子的左孩子递归
insertNode(node.left, newNode);
}
} else {
if (node.right == null) {
node.right = newNode;
} else {
insertNode(node.right, newNode);
}
}
}
有了插入节点的方法,那么接下来我们就可以创建出一颗二叉搜索树来。
let bst = new BST();
bst.insert(11);
bst.insert(7);
bst.insert(15);
bst.insert(5);
bst.insert(3);
bst.insert(9);
bst.insert(8);
bst.insert(10);
bst.insert(13);
bst.insert(12);
bst.insert(14);
bst.insert(20);
bst.insert(18);
bst.insert(25);
bst.insert(6);
console.log(bst)
在控制台打印,我们就可以画出这个树的样子:
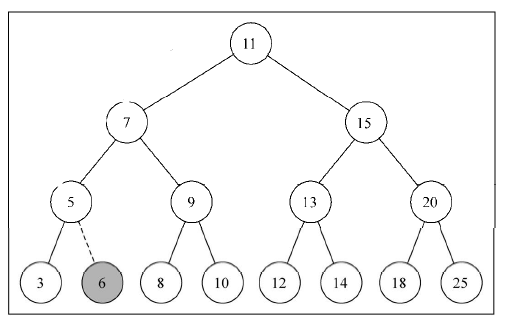
3.树的遍历
遍历一棵树是指访问树的每个节点并对它们进行某种操作的过程。访问树的所有节点有三种方式:中序、先序和后序。
3.1中序遍历
中序遍历是一种以上行顺序访问BST所有节点的遍历方式,也就是以从最小到最大的顺序访问所有节点。中序遍历的一种应用就是对树进行排序操作。中序遍历的执行顺序是先访问节点的左侧子节点,然后访问节点本身,最后是右侧子节点,其遍历路径如下图所示:
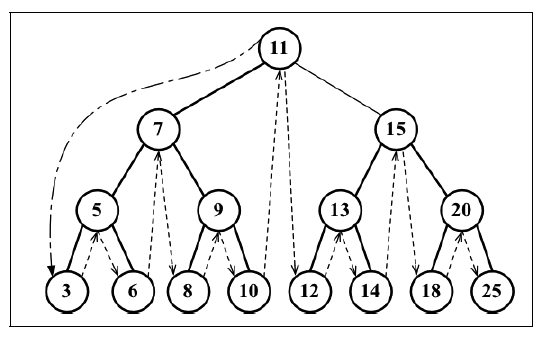
我们编写midOrderTraverse方法实现中序遍历树,该方法收一个回调函数作为参数。回调函数用来定义我们对遍历到的每个节点进行的操作。
// 中序遍历
midOrderTraverse(callback) {
midOrderTraverseNode(this.root, callback);
}
同时,为了递归方便,编写一个辅助函数midOrderTraverseNode:
// 中序遍历辅助函数
function midOrderTraverseNode(node, callback) {
if (node !== null) {
midOrderTraverseNode(node.left, callback);
callback(node);
midOrderTraverseNode(node.right, callback);
}
}
接下来,我们就可以测试一下我们编写代码的功能:以中序遍历上文构建好的二叉搜索树,并打印出每个节点的值。
//打印节点值得函数
function printNode(node) {
console.log(node.value);
}
bst.midOrderTraverse(printNode) //中序遍历
//输出结果:
//3 5 6 7 8 9 10 11 12 13 14 15 18 20 25
3.2先序遍历
先序遍历是以优先于后代节点的顺序访问每个节点的。先序遍历的一种应用是打印一个结构化的文档。先序遍历会先访问节点本身,然后再访问它的左侧子节点,最后是右侧子节点,其遍历路径如下图所示:
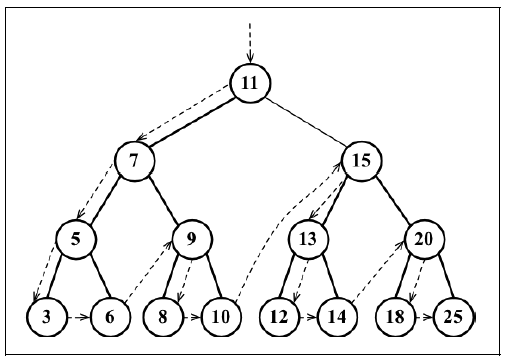
同中序遍历一样,先序遍历还是需要一个辅助函数:
// 先序遍历
preOrderTraverse(callback){
preOrderTraverseNode(this.root,callback)
}
// 先序遍历辅助函数
function preOrderTraverseNode(node,callback){
if (node !== null) {
callback(node);
preOrderTraverseNode(node.left, callback);
preOrderTraverseNode(node.right, callback);
}
}
测试:
//打印节点值得函数
function printNode(node) {
console.log(node.value);
}
bst.preOrderTraverse(printNode) //先序遍历
//输出结果:
//11 7 5 3 6 9 8 10 15 13 12 14 20 18 25
3.3后序遍历
后序遍历则是先访问节点的后代节点,再访问节点本身。后序遍历的一种应用是计算一个目录和它的子目录中所有文件所占空间的大小。后序遍历会先访问左侧子节点,然后是右侧子节点,最后是父节点本身。其遍历路径如下图所示:
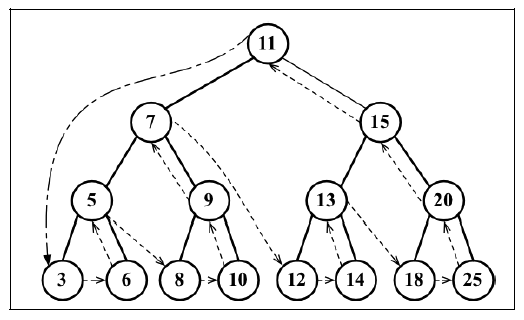
后序遍历还是需要一个辅助函数:
// 后序遍历
lastOrderTraverse(callback){
lastOrderTraverseNode(this.root,callback)
}
// 后序遍历辅助函数
function lastOrderTraverseNode(node,callback){
if (node !== null) {
lastOrderTraverseNode(node.left, callback);
lastOrderTraverseNode(node.right, callback);
callback(node);
}
}
测试:
//打印节点值得函数
function printNode(node) {
console.log(node.value);
}
bst.lastOrderTraverse(printNode) //先序遍历
//输出结果:
//3 6 5 8 10 9 7 12 14 13 18 25 20 15 11
3.4总结
通过以上,你会发现,中序、先序和后序遍历的实现方式是很相似的,唯一不同的是访问节点本身、访问左子节点、访问右子节点的顺序。
我们可以这样记忆:
以节点本身为参考,
- 访问顺序为:左——>节点本身——>右,节点本身在中间,即为中序遍历
- 访问顺序为:节点本身——>左——>右,节点本身在最前,即为先序遍历
- 访问顺序为:左——>右——>节点本身,节点本身在最前,即为后序遍历
4.搜索树中的值
4.1搜索树中最小值和最大值
我们知道,在二叉搜索树中,左子节点的值永远小于右子节点的值,所以,树的最小值一定是树的最后一层最左侧的节点,而树的最大值一定是树的最后一层最右侧的节点。
所以,搜索树中的最小值和最大值即就是搜索树中的最后一层最左侧节点和最右侧节点,代码如下:
// 查找树中节点值最小的节点
minNodeInTree(node){
if (node) {
while (node && node.left) {
node = node.left;
}
return node.value;
} else {
return null;
}
}
// 查找树中节点值最大的节点
maxNodeInTree(node){
if (node) {
while (node && node.right) {
node = node.right;
}
return node.value;
} else {
return null;
}
}
4.2搜索树中特定节点值
给定一个value值,找出这个值在树中对应的节点,如果该节点存在,则返回该节点,如果不存在,则返回null。
这里主要采用比较的方式。比较给出的value值与根节点值的大小,如果比根节点值小,则继续比较根节点左子节点的值;如果比根节点值大,则继续比较根节点右子节点的值;一直递归比较。。。一直比较到既不比节点值小,也不比节点值大,那说明给出的value就是该节点值,最后返回该节点。代码如下:
// 查找树中特定的节点值
searchNodeInTree(value) {
return searchNode(this.root, value);
}
// 查找特定节点辅助函数
function searchNode(node, value) {
if (node == null) {
return null;
}
if (value < node.value) {
return searchNode(node.left, value);
} else if (value > node.value) {
return searchNode(node.right, value);
} else {
return node;
}
}
完整代码请戳☞☞☞BinarySearchTree
(完)
原生JS实现二叉搜索树(Binary Search Tree)的更多相关文章
- 编程算法 - 二叉搜索树(binary search tree) 代码(C)
二叉搜索树(binary search tree) 代码(C) 本文地址: http://blog.csdn.net/caroline_wendy 二叉搜索树(binary search tree)能 ...
- 数据结构 《5》----二叉搜索树 ( Binary Search Tree )
二叉树的一个重要应用就是查找. 二叉搜索树 满足如下的性质: 左子树的关键字 < 节点的关键字 < 右子树的关键字 1. Find(x) 有了上述的性质后,我们就可以像二分查找那样查找给定 ...
- [Data Structure] 二叉搜索树(Binary Search Tree) - 笔记
1. 二叉搜索树,可以用作字典,或者优先队列. 2. 根节点 root 是树结构里面唯一一个其父节点为空的节点. 3. 二叉树搜索树的属性: 假设 x 是二叉搜索树的一个节点.如果 y 是 x 左子树 ...
- 二叉搜索树(Binary Search Tree)(Java实现)
@ 目录 1.二叉搜索树 1.1. 基本概念 1.2.树的节点(BinaryNode) 1.3.构造器和成员变量 1.3.公共方法(public method) 1.4.比较函数 1.5.contai ...
- 二叉搜索树(Binary Search Tree)实现及测试
转:http://blog.csdn.net/a19881029/article/details/24379339 实现代码: Node.java //节点类public class Node{ ...
- 二叉搜索树 (BST) 的创建以及遍历
二叉搜索树(Binary Search Tree) : 属于二叉树,其中每个节点都含有一个可以比较的键(如需要可以在键上关联值), 且每个节点的键都大于其左子树中的任意节点而小于右子树的任意节点的键. ...
- [LeetCode] Split BST 分割二叉搜索树
Given a Binary Search Tree (BST) with root node root, and a target value V, split the tree into two ...
- 自己动手实现java数据结构(六)二叉搜索树
1.二叉搜索树介绍 前面我们已经介绍过了向量和链表.有序向量可以以二分查找的方式高效的查找特定元素,而缺点是插入删除的效率较低(需要整体移动内部元素):链表的优点在于插入,删除元素时效率较高,但由于不 ...
- BinarySearchTree二叉搜索树的实现
/* 二叉搜索树(Binary Search Tree),(又:二叉查找树,二叉排序树)它或者是一棵空树,或者是具有下列性质的二叉树: 若它的左子树不空,则左子树上所有结点的值均小于它的根结点的值; ...
随机推荐
- React 项目引入 Dva
背景 现在手上在做的 React 项目因为年代久远,用的 Redux,写代码的体验不太好,所以想升级一下引入 dva.以往使用 dva 都是使用 dva-cli 直接生成 dva 项目,或者在使用 a ...
- 统计字符的个数,能够组成几个acmicpc
Problem F. String Input file: standard input Output file: standard ou ...
- 通过机器学习的线性回归算法预测股票走势(用Python实现)
在本人的新书里,将通过股票案例讲述Python知识点,让大家在学习Python的同时还能掌握相关的股票知识,所谓一举两得.这里给出以线性回归算法预测股票的案例,以此讲述通过Python的sklearn ...
- [USACO10NOV]购买饲料Buying Feed 单调队列优化DP
题目描述 约翰开车来到镇上,他要带 KKK 吨饲料回家.运送饲料是需要花钱的,如果他的车上有 XXX 吨饲料,每公里就要花费 X2X^2X2 元,开车D公里就需要 D×X2D\times X^2D×X ...
- Python eval() exec()
eval(str) 函数:将字符串 str 当成有效的表达式来求值并返回计算结果常见作用:1,计算字符串中有效的表达式,并返回结果In [55]: eval('pow(10,2)') # 函数Out[ ...
- JAVA动态代理 你真的完全了解Java动态代理吗?
网上讲JAVA动态代理,说的天花乱坠,发现一篇文章写的通俗易懂,特意转载过来 原文地址:https://www.jianshu.com/p/95970b089360 动态代理看起来好像是个什么高大上的 ...
- PHP5底层原理之垃圾回收机制
概念 垃圾回收机制 是一种内存动态分配的方案,它会自动释放程序不再使用的已分配的内存块. 垃圾回收机制 可以让程序员不必过分关心程序内存分配,从而将更多的精力投入到业务逻辑. 与之相关的一个概念,内存 ...
- 百万年薪python之路 -- MySQL数据库之 完整性约束
MySQL完整性约束 一. 介绍 为了防止不符合规范的数据进入数据库,在用户对数据进行插入.修改.删除等操作时,DBMS自动按照一定的约束条件对数据进行监测,使不符合规范的数据不能进入数据库,以确保数 ...
- ASP.NET WebApi+Vue前后端分离之允许启用跨域请求
前言: 这段时间接手了一个新需求,将一个ASP.NET MVC项目改成前后端分离项目.前端使用Vue,后端则是使用ASP.NET WebApi.在搭建完成前后端框架后,进行接口测试时发现了一个前后端分 ...
- Spring Boot2 系列教程(十八)Spring Boot 中自定义 SpringMVC 配置
用过 Spring Boot 的小伙伴都知道,我们只需要在项目中引入 spring-boot-starter-web 依赖,SpringMVC 的一整套东西就会自动给我们配置好,但是,真实的项目环境比 ...