(转)消息队列 Kafka 的基本知识及 .NET Core 客户端
原文地址:https://www.cnblogs.com/savorboard/p/dotnetcore-kafka.html
前言
最新项目中要用到消息队列来做消息的传输,之所以选着 Kafka 是因为要配合其他 java 项目中,所以就对 Kafka 了解了一下,也算是做个笔记吧。
本篇不谈论 Kafka 和其他的一些消息队列的区别,包括性能及其使用方式。
简介
Kafka 是一个实现了分布式的、具有分区、以及复制的日志的一个服务。它通过一套独特的设计提供了消息系统中间件的功能。它是一种发布订阅功能的消息系统。
一些名词
如果要使用 Kafka ,那么在 Kafka 中有一些名词需要知道,文本不讨论这些名词是否在其他消息队列中具有相同的含义。所有名词均是针对于 Kafka。
Message
消息,就是要发送的内容,一般包装成一个消息对象。
Topic
通俗来讲的话,就是放置“消息”的地方,也就是说消息投递的一个容器。假如把消息看作是信封的话,那么 Topic 就是一个邮筒,如下图所示:

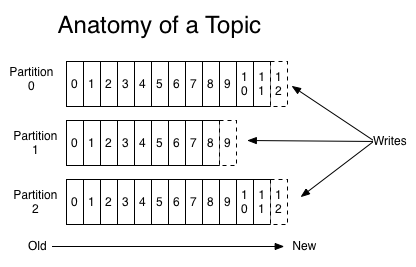
Partition && Log
Partition 分区,可以理解为一个逻辑上的分区,像是我们电脑的磁盘 C:, D:, E: 盘一样,
Kafka 为每个分区维护着一份日志Log文件。
每个分区是一个有序的,不可修改的,消息组成的队列。 当消息过来的时候,会被追加到日志文件中,这个追加是根据 commit 命令来执行的。
分区中的每一条消息都有一个编号,叫做 offset id,这个 id 在当前分区中是唯一的,并且是递增的。
日志,就是用来记录分区中接收到的消息,因为每一个 Topic 可以同时向一个或者多个分区投递消息,所以实际在存储日志的时候,每个分区会对应一个日志目录,其命名规则一般为 <topic_name>-<partition_id>, 目录中就是一个分区的一份 commit log 日志文件。
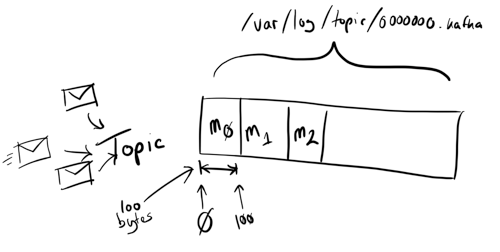
Kafka
集群会保存一个时间段内所有被发布出来的信息,无论这个消息是否已经被消费过,这个时间段是可以配置的。比如日志保存时间段被设置为2天,那么2天以内发布的消息都是可以消费的;而之前的消息为了释放空间将会抛弃掉。Kafka的性能与数据量不相干,所以保存大量的消息数据不会造成性能问题。
对日志进行分区主要是为了以下几个目的:第一、这可以让log的伸缩能力超过单台服务器上线,每个独立的partition的大小受限于单台服务器的容积,但是一个topic可以有很多partition从而使得它有能力处理任意大小的数据。第二、在并行处理方面这可以作为一个独立的单元。
生产者 Producers
和其他消息队列一样,生产者通常都是消息的产生方。
在 Kafka 中它决定消息发送到指定Topic的哪个分区上。
消费者 Consumers
消费者就是消息的使用者,在消费者端也有几个名词需要区分一下。
一般消息队列有两种模式的消费方式,分别是 队列模式 和 订阅模式。
队列模式:一对一,就是一个消息只能被一个消费者消费,不能重复消费。一般情况队列支持存在多个消费者,但是对于一个消息,只会有一个消费者可以消费它。
订阅模式:一对多,一个消息可能被多次消费,消息生产者将消息发布到Topic中,只要是订阅改Topic的消费者都可以消费。
Consumer && Subscriber
Group: 组,是一个消费者的集合,每一组都有一个或者多个消费者,Kafka 中在一个组内,消息只能被消费一次。
在发布订阅模式中,消费者是以组的方式进行订阅的,就是Consumer Group,他们的关系如下图:

每个发布到Topic上的消息都会被投递到每个订阅了此Topic的消费者组中的某一个消费者,也就是每个组都会被投递,但是每个组都只会有一个消费者消费这个消息。
开头介绍了Kafka 是 发布-订阅 功能的消息队列,所以在Kafka中,队列模式是通过单个消费者组实现的,也就是整个结构中只有一个消费者组,消费者之间负载均衡。
Kafka 集群
Borker: Kafka 集群有多个服务器组成,每个服务器称做一个 Broker。同一个Topic的消息按照一定的key和算法被分区存储在不同的Broker上。

上图引用自:http://blog.csdn.net/lizhitao
因为 Kafka 的集群它是通过将分区散布到各个Server的实现的,也就是说集群中每个服务器他们都是彼此共享分区的数据和请求,每个分区的日志文件被复制成指定分数,分散在各个集群机器,这样来实现的故障转移。
对于每一个分区都会有一个服务器作为它的 "leader" 并且有零个或者多个服务器作为"followers" 。leader
服务器负责处理关于这个 partition 所有的读写请求, followers 服务器则被动的复制 leader 服务器。如果有 leader
服务器失效,那么 followers 服务器将有一台被自动选举成为新的 leader 。每个服务器作为某些 partition 的
leader 的同时也作为其它服务器的 follower ,从而实现了集群的负载均衡。
-----------------------------------------------------分割线-----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------
上面是原文对kafka的介绍,因原文代码部分使用的是Rdkafka,现在已被Confluent.Kafka替代,所以代码部分不贴了(想看的见开头的原文链接)。
- 建议需要的直接使用Confluent.Kafka
Confluent.Kafka 说明:https://docs.confluent.io/current/clients/confluent-kafka-dotnet/api/Confluent.Kafka.ProducerConfig.html
Confluent.Kafka 地址:https://github.com/confluentinc/confluent-kafka-dotnet
- 在测试中用到了 async和await
async和await参考:https://www.cnblogs.com/cjm123/articles/9927338.html
(转)消息队列 Kafka 的基本知识及 .NET Core 客户端的更多相关文章
- 消息队列 Kafka 的基本知识及 .NET Core 客户端
前言 最新项目中要用到消息队列来做消息的传输,之所以选着 Kafka 是因为要配合其他 java 项目中,所以就对 Kafka 了解了一下,也算是做个笔记吧. 本篇不谈论 Kafka 和其他的一些消息 ...
- 分布式消息队列 Kafka
分布式消息队列 Kafka 2016-02-25 杜亦舒 Kafka是一个高吞吐量的.分布式的消息系统,由Linkedin开发,开发语言为scala具有高吞吐.可扩展.分布式等特点 适用场景 活动数据 ...
- 消息队列kafka
消息队列kafka 为什么用消息队列 举例 比如在一个企业里,技术老大接到boss的任务,技术老大把这个任务拆分成多个小任务,完成所有的小任务就算搞定整个任务了. 那么在执行这些小任务的时候,可能 ...
- 消息队列-Kafka学习
Kafka是一个分布式的消息队列,学习见Apache Kafka文档,中文翻译见Kafka分享,一个简单的入门例子见kafka代码入门实例.本文只针对自己感兴趣的点记录下. 1.架构 Producer ...
- 消息队列Kafka学习记录
Kafka其实只是众多消息队列中的一种,对于Kafka的具体释义我这里就不多说了,详见:http://baike.baidu.com/link?url=HWFYszYuMdP_lueFH5bmYnlm ...
- 基于Docker搭建分布式消息队列Kafka
本文基于Docker搭建一套单节点的Kafka消息队列,Kafka依赖Zookeeper为其管理集群信息,虽然本例不涉及集群,但是该有的组件都还是会有,典型的kafka分布式架构如下图所示.本例搭建的 ...
- Kafka 消息队列系列之分布式消息队列Kafka
介绍 ApacheKafka®是一个分布式流媒体平台.这到底是什么意思呢?我们认为流媒体平台具有三个关键功能:它可以让你发布和订阅记录流.在这方面,它类似于消息队列或企业消息传递系统.它允许您以容 ...
- 消息队列——Kafka基本使用及原理分析
文章目录 一.什么是Kafka 二.Kafka的基本使用 1. 单机环境搭建及命令行的基本使用 2. 集群搭建 3. Java API的基本使用 三.Kafka原理浅析 1. topic和partit ...
- 消息队列——kafka
原文:再过半小时,你就能明白kafka的工作原理了 会出现什么情况呢? 1.为了这个女朋友,我请假回去拿(老板不批). 2.小哥一直在你楼下等(小哥还有其他的快递要送). 3.周末再送(显然等不及). ...
随机推荐
- win10重装win7 无法引导
品牌机win10回滚win7 无法引导 BIOS设置 按键盘上的右方向键(→)选择到"Exit" 按键盘上的下方向键(↓)选择到 "OS Optimized Defaul ...
- webpack4.0构建项目流程
webpack4.0构建项目流程,具体的就不一一唠叨了,这里给出构建流程步骤: 流程大图: 下载高清大图
- 第08组 Alpha冲刺(4/4)
小李的博客 作业博客 作业链接 组员1李昕晖(组长) 过去两天完成了哪些任务 文字/口头描述 11月20日了解各个小组的进度与难以攻破的地方,晚上安排开会,安排新的冲刺任务. 实现地图功能 展示Git ...
- MyBatis(七):mybatis Java API编程实现增、删、改、查的用法
最近工作中用到了mybatis的Java API方式进行开发,顺便也整理下该功能的用法,接下来会针对基本部分进行学习: 1)Java API处理一对多.多对一的用法: 2)增.删.改.查的用法: 3) ...
- Windows curl开启注意事项
php.ini 开启curl扩展 设置有时候开启之后,curl还是不行:将php目录下的libssh2.dll复制到apache/bin下.(基本上可以成功) 如果没有开启成功,将php安装目录下 ...
- 【深入学习linux】Linux系统安装
1. 配置内存大小,和设置镜像文件,开启虚拟机,点击虚拟机,立即按F2,会出现下图 2. 选择 Boot 菜单,默认是以硬盘进行启动,但是硬盘目前为空,则不能启动,需要改成以光盘形式启动即 CD-RO ...
- Densely semantically aligned person re-identification
Densely semantically aligned person re-identification https://arxiv.org/abs/1812.08967
- 【MySQL】Mysql模糊查询like提速优化
一般情况下like模糊查询的写法为(field已建立索引): SELECT `column` FROM `table` WHERE `field` like '%keyword%'; 上面的语句用ex ...
- kotlin基础 函数编写规则
- 查看ssh有没有被黑的IP
#grep "Failed password " /var/log/auth.log | awk '{print $11}' | sort | uniq -c | sort -nr ...