ZooKeeper学习笔记(二)——内部原理
zookeeper学习笔记(二)——内部原理
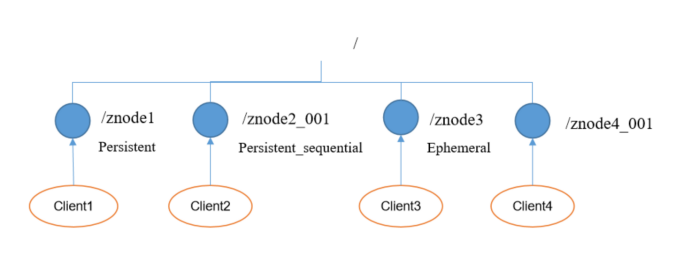
1. zookeeper的节点的类型
总的来说可以分为持久型和短暂型,主要区别如下:
- 持久:客户端与服务器端断开连接的以后,创建的节点不会被删除;
- 持久化目录节点:客户端与zookeeper断开连接之后,该节点依旧会存在;
- 持久化顺序编号目录节点:客户端与zookeeper断开连接之后,该节点依旧会存在,只是zookeeper会给该节点名称进行顺序编号;
- 短暂:客户端和服务端断开连接之后,创建的节点自己删除
- 临时目录节点:客户端与zookeeper断开连接之后,该节点会被删除;
- 临时顺序编号节点:客户端与zookeeper断开连接之后,该节点被删除,只是zookeeper给该节点名称进行顺序编号。
要说明的是创建znode的时候设置的顺序标识,znode名称后边会附加一个值,顺序号只是一个单调递增的计数器,由父节点维护。
在分布式系统中,顺序号可以被用于所有的事件进行全局的排序,这样客户端可以通过顺序号推断事件的顺序。
2. Stat结构体
1)czxid-创建节点的事务zxid,每次修改ZooKeeper状态都会收到一个zxid形式的时间戳,也就是ZooKeeper事务ID。事务ID是ZooKeeper中所有修改总的次序。每个修改都有唯一的zxid,如果zxid1小于zxid2,那么zxid1在zxid2之前发生。
2)ctime - znode被创建的毫秒数(从1970年开始)
3)mzxid - znode最后更新的事务zxid
4)mtime - znode最后修改的毫秒数(从1970年开始)
5)pZxid-znode最后更新的子节点zxid
6)cversion - znode子节点变化号,znode子节点修改次数
7)dataversion - znode数据变化号
8)aclVersion - znode访问控制列表的变化号
9)ephemeralOwner- 如果是临时节点,这个是znode拥有者的session id。如果非临时节点则是0。
10)dataLength- znode的数据长度
11)numChildren - znode子节点数量
3. 监听器原理(重点内容)
我们在之前已经了解过,注册进zookeeper的客户端会监听它所关心的节点,当节点发生变化的时候,zookeeper会通知给客户端。zookeeper主要是为了统一分布式系统中各个节点的工作状态,在资源冲突的情况下协调提供节点资源抢占,提供给每个节点了解整个集群所处状态的途径。这一切的实现都依赖于zookeeper中的事件监听和通知机制。
大致原理:zookeeper维护着一个watchList,里面是对某个节点的观察者对象,一旦发生变化,就会遍历这个watchList,挨个通知它们。
通过追踪代码,来看一下zookeeper的异步通信原理:
首先代码在执行的时候创建了一个
Zookeeper对象
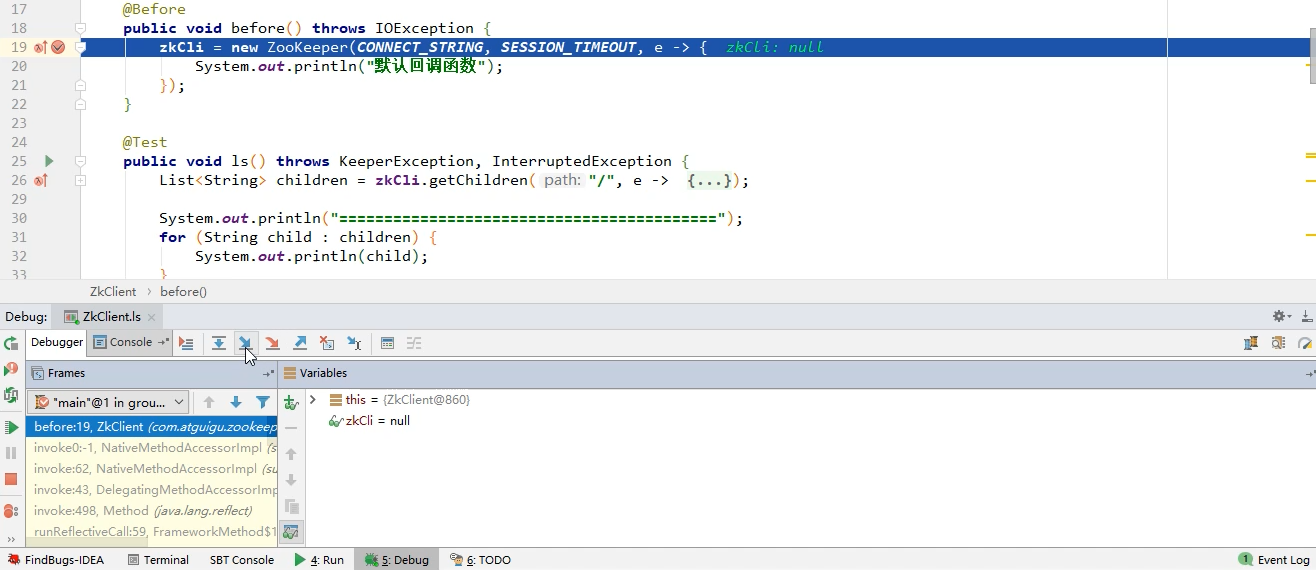
代码进入到了
Zookeeper()方法,可以看到它是在调用自己的另外一个构造方法:

继续跟进:这个方法里面生成了两个线程,zookeeper的客户端和服务端通信时异步的,异步一定有子线程

这是两个
Thread的子类
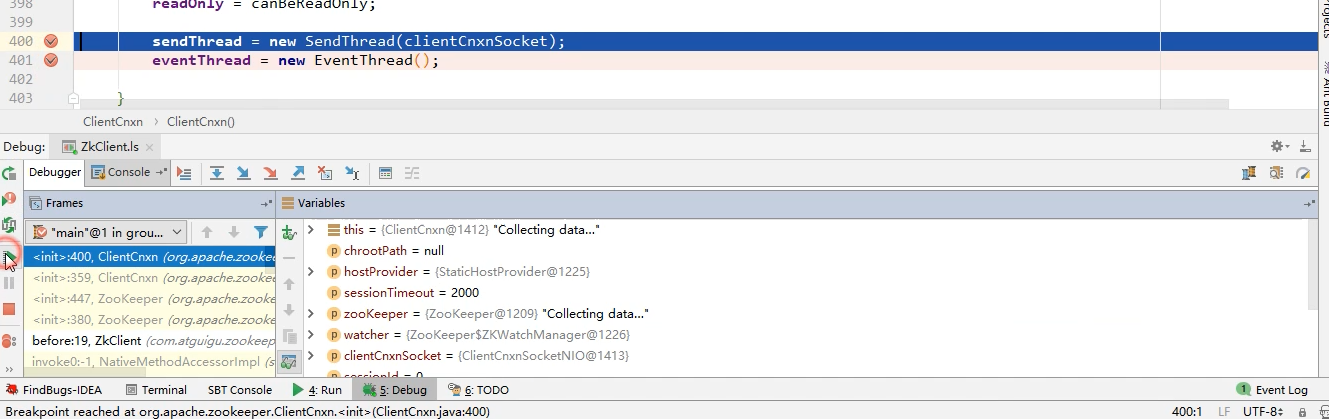
在原来创建创建
ClientCnxn的方法下边,有一个start方法:

继续跟进去:
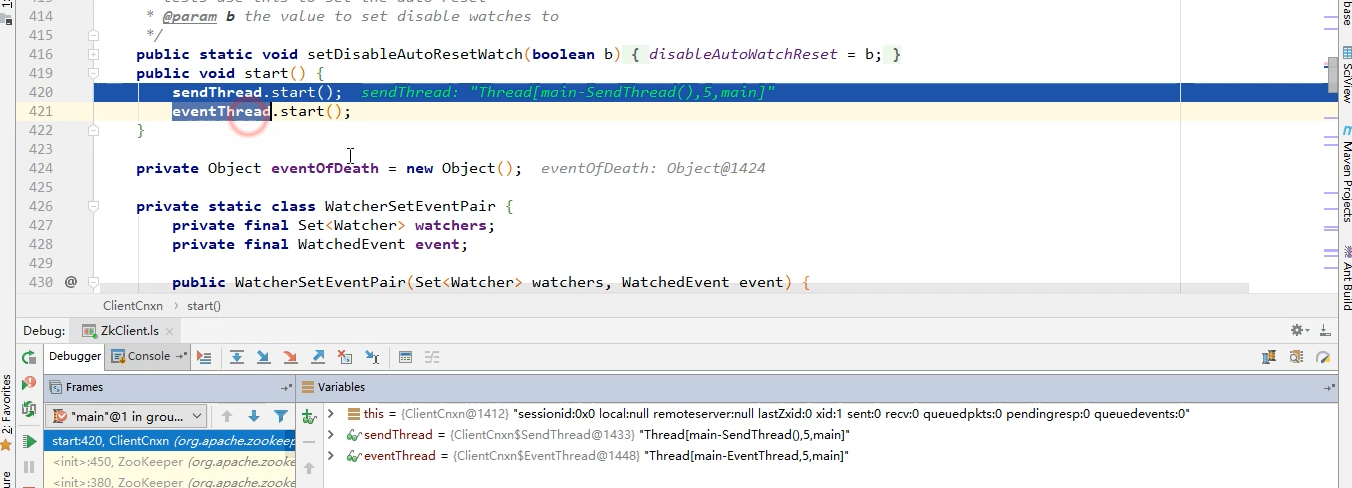
ok~到这可以清楚的看到,我们在创建Zookeeper对象的时候就生成了两个子线程,sendTread和eventThread
总结:所有的注册请求都是通过sendThread发给服务端的,而eventThread就是等待着服务端的通知,一旦接收到了通知,就去回调Process()方法。
一个形象的小栗子:
A老板有两个小秘书,一个叫sendThread,另一个叫做eventThread。有一天A老板要给B老板发消息,那么sendThread小秘书就会去执行老板的发消息任务,而eventThread就等着B老板的回信,它一旦接收到回信,就去通知A老板~ 。

4. ZooKeeper的ZAB理论(重点)
zookeeper是如何保证在分布式高并发情况下数据读写有序并且全局一致的?
通过ZAB协议保证的:Zookeeper Atomic Broadcast ,即Zookeeper 原子广播。
主要内容就是两个部分:① 没有leader选leader【崩溃恢复】,② 有leader就开始干活【正常读写】
那么接下来就讨论,怎么选leader 有了leader之后怎么干活~
4.1 选举机制
4.1.1 zookeeper集群中节点的状态:
- Looking :集群刚启动时,所有的节点都是Looking状态,即寻找leader状态。该状态无法对外提供服务,其他状态都可以。
- Abserving: 为了快速扩展集群,在小范围内leader带着follower投票执行写,投票成功后通知给observers去写,保证了扩展集群时写的性能。【适用场景:集群大 、跨数据中心】
- Following: follower
- Leading:leader
1)半数机制:集群中半数以上机器存活,集群可用。所以Zookeeper适合安装奇数台服务器。
2)Zookeeper虽然在配置文件中并没有指定Master和Slave。但是,Zookeeper工作时,是有一个节点为Leader,其他则为Follower,Leader是通过内部的选举机制临时产生的。
3)以一个简单的例子来说明整个选举的过程。
假设有五台服务器组成的Zookeeper集群,它们的id从1-5,同时它们都是最新启动的,也就是没有历史数据,在存放数据量这一点上,都是一样的。假设这些服务器依序启动,来看看会发生什么,如图所示。

(1)服务器1启动,发起一次选举。服务器1厚颜无耻投自己一票。此时服务器1票数一票,不够半数以上(3票),选举无法完成,服务器1状态保持为LOOKING;
(2)服务器2启动,再发起一次选举。服务器1和2分别投自己一票并交换选票信息:此时服务器1发现服务器2的ID比自己目前投票推举的(服务器1)大,更改选票为推举服务器2。此时服务器1票数0票,服务器2票数2票,没有半数以上结果,选举无法完成,服务器1,2状态保持LOOKING
(3)服务器3启动,发起一次选举。此时服务器1和2都会更改选票为服务器3。此次投票结果:服务器1为0票,服务器2为0票,服务器3为3票。此时服务器3的票数已经超过半数,服务器3当选Leader。服务器1,2更改状态为FOLLOWING,服务器3更改状态为LEADING;
(4)服务器4启动,发起一次选举。此时服务器1,2,3已经不是LOOKING状态,不会更改选票信息。交换选票信息结果:服务器3为3票,服务器4为1票。此时服务器4服从多数,更改选票信息为服务器3,并更改状态为FOLLOWING;
(5)服务器5启动,同4一样当小弟。
注意:选leader时先比较zxid(数据版本),再比较myid。
4.2 写数据流程
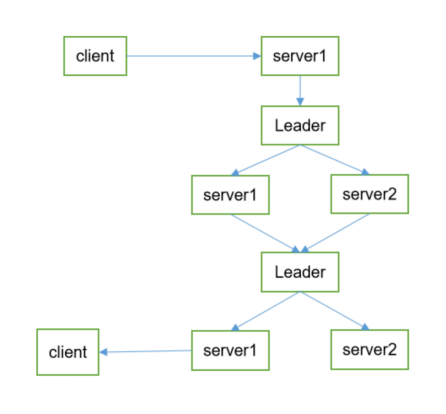
1)Client 向 ZooKeeper 的 Server1 上写数据,发送一个写请求。
2)如果Server1不是Leader,那么Server1 会把接受到的请求进一步转发给Leader,因为每个ZooKeeper的Server里面有一个是Leader。这个Leader 会将写请求广播给各个Server,比如Server1和Server2,各个Server会将该写请求加入待写队列,并向Leader发送成功信息。
3)当Leader收到半数以上 Server 的成功信息,说明该写操作可以执行。Leader会向各个Server 发送提交信息,各个Server收到信息后会落实队列里的写请求,此时写成功。
4)Server1会进一步通知 Client 数据写成功了,这时就认为整个写操作成功。
ZooKeeper学习笔记(二)——内部原理的更多相关文章
- ZooKeeper学习笔记二:API基本使用
Grey ZooKeeper学习笔记二:API基本使用 准备工作 搭建一个zk集群,参考ZooKeeper学习笔记一:集群搭建. 确保项目可以访问集群的每个节点 新建一个基于jdk1.8的maven项 ...
- 【原】Learning Spark (Python版) 学习笔记(三)----工作原理、调优与Spark SQL
周末的任务是更新Learning Spark系列第三篇,以为自己写不完了,但为了改正拖延症,还是得完成给自己定的任务啊 = =.这三章主要讲Spark的运行过程(本地+集群),性能调优以及Spark ...
- AJax 学习笔记二(onreadystatechange的作用)
AJax 学习笔记二(onreadystatechange的作用) 当发送一个请求后,客户端无法确定什么时候会完成这个请求,所以需要用事件机制来捕获请求的状态XMLHttpRequest对象提供了on ...
- [Firefly引擎][学习笔记二][已完结]卡牌游戏开发模型的设计
源地址:http://bbs.9miao.com/thread-44603-1-1.html 在此补充一下Socket的验证机制:socket登陆验证.会采用session会话超时的机制做心跳接口验证 ...
- ZooKeeper 学习笔记
ZooKeeper学习笔记 1. zookeeper基本概念 zookeeper是一个分布式的,开放源码的分布式应用程序协调服务,是hadoop和Habase的重要组件,是为分布式应用提供一致性服 ...
- 机器学习实战(Machine Learning in Action)学习笔记————03.决策树原理、源码解析及测试
机器学习实战(Machine Learning in Action)学习笔记————03.决策树原理.源码解析及测试 关键字:决策树.python.源码解析.测试作者:米仓山下时间:2018-10-2 ...
- amazeui学习笔记二(进阶开发3)--HTML/CSS规范Rules
amazeui学习笔记二(进阶开发3)--HTML/CSS规范Rules 一.总结 1.am:以 am 为命名空间 2.模块状态: {命名空间}-{模块名}-{状态描述} 3.子模块: {命名空间}- ...
- Zookeeper学习笔记(中)
Zookeeper学习笔记(中) Zookeeper的基本原理和基本实现 深入了解ZK的基本原理 ZK的一致性: ZAB 协议: Zookeeper 原子消息广播协议 ZK通过选举保证 leader ...
- 纯JS实现KeyboardNav(学习笔记)二
纯JS实现KeyboardNav(学习笔记)二 这篇博客只是自己的学习笔记,供日后复习所用,没有经过精心排版,也没有按逻辑编写 这篇主要是添加css,优化js编写逻辑和代码排版 GitHub项目源码 ...
随机推荐
- create-react-app不支持less的解决方式
进入node_modules\react-scripts\config目录 修改webpack.config.dev.js跟webpack.config.prod.js中关于loader的配置即可,注 ...
- 关于org.apache.lucene.queryParser.ParseException: Encountered "" 解决方法
现象: org.apache.lucene.queryParser.ParseException: Encountered "<EOF>" at line 1, col ...
- 利用Windows内置工具winsat测试硬盘速度(SSD&机械盘对比)
利用Windows内置工具winsat测试硬盘速度(SSD&机械盘对比) 以下是红色内容是在命令行运行: C:\Users\Administrator>winsat diskWindow ...
- js正则判断字符串中是否包含特殊字符和空格
字符串只能是数字.字母和中文组成,不能包含特殊符号和空格. /^[\u4e00-\u9fa5_a-zA-Z0-9]+$/
- http请求的header的一个小细节
今天前后端联调的时候无论如何后端都搜不到前端的token,以为是公司全局网关拦截了token,最后发现也不是,最终在无意之中发现http请求的header的key不能带有下划线,比如app_token ...
- Unity资源商店 Asset store下载文件夹的位置
Win10 C:\Users\用户名\AppData\Roaming\Unity\Asset Store-5.x\ Mac OS X ~/Library/Unity/Asset Store
- Video Architecture Search
Video Architecture Search 2019-10-20 06:48:26 This blog is from: https://ai.googleblog.com/2019/10/v ...
- p7zip p7zip -d 7z
- spark 监控--WebUi、Metrics System(转载)
转载自:https://www.cnblogs.com/barrenlake/p/4364644.html Spark 监控相关的部分有WebUi 及 Metrics System; WebUi用于展 ...
- 大幅度改变celery日志外观,修改成日志可点击跳转和鲜艳五彩日志,解决脚本中已添加handler的logger和框架日志重复记录问题。
大幅度改变celery日志外观,修改成日志可点击跳转和鲜艳五彩日志,解决脚本中已添加handler的logger和框架日志重复记录问题.打猴子补丁. 先把脚本中的所有logger的handlers全部 ...