Hive-2.3.6 安装
本安装依赖Haddop2.8安装
https://www.cnblogs.com/xibuhaohao/p/11772031.html
一、下载Hive与MySQL jdbc 连接驱动
apache-hive-2.3.6-bin.tar.gz 官方网站
mysql-connector-java-5.1.48.tar.gz oracle官网
二、解压安装Hive
1、使用Hadoop用户进行下面操作
2、解压缩
tar -vzxf apache-hive-2.3.6-bin.tar.gz -C /home/hadoop/

3、配置结点环境变量
cat .bash_profile
添加如下:
export HIVE_HOME=/home/hadoop/apache-hive-2.3.6-bin
export PATH=$PATH:$JAVA_HOME/bin:$HIVE_HOME/bin
source .bash_profile
4、hadoop下创建hive所用文件夹
1)创建hive所需文件目录
hadoop fs -mkdir -p /home/hadoop/hive/tmp
hadoop fs -mkdir -p /home/hadoop/hive/data
hadoop fs -chmod g+w /home/hadoop/hive/tmp
hadoop fs -chmod g+w /home/hadoop/hive/data
2)检查是否创建成功
hadoop fs -ls /home/hadoop/hive/

3)后面进入hive可能会爆出权限问题
hadoop fs -chmod -R 777 /home/hadoop/hive/tmp
hadoop fs -chmod -R 777 /home/hadoop/hive/data
5、将MySQL驱动copy至hive lib下面
cp mysql-connector-java-5.1.48.jar /home/hadoop/apache-hive-2.3.6-bin/lib/
6、MySQL创建hive所需database、user
create database metastore;
grant all on metastore.* to hive@'%' identified by 'hive';
grant all on metastore.* to hive@'localhost' identified by 'hive';
flush privileges;
cd /home/hadoop/apache-hive-2.3.6-bin/conf
1、修改hive-env.sh
cp hive-env.sh.template hive-env.sh
添加如下:
export JAVA_HOME=/usr/java/jdk1.8.0_221
export HADOOP_HOME=/home/hadoop/hadoop-2.8.5
2、增加hive-site.xml
<?xml version="1.0" encoding="UTF-8" standalone="no"?>
<property>
<name>hive.exec.scratchdir</name>
<value>/home/hadoop/hive/tmp</value>
</property>
<property>
<name>hive.metastore.warehouse.dir</name>
<value>/home/hadoop/hive/data</value>
</property>
<property>
<name>hive.querylog.location</name>
<value>/opt/apache-hive-2.3.6/log</value>
</property>
<property>
<name>javax.jdo.option.ConnectionURL</name>
<value>jdbc:mysql://172.16.100.173:3306/metastore?createDatabaseIfNotExist=true&characterEncoding=UTF-8&useSSL=false</value>
</property>
<property>
<name>javax.jdo.option.ConnectionDriverName</name>
<value>com.mysql.jdbc.Driver</value>
</property>
<property>
<name>javax.jdo.option.ConnectionUserName</name>
<value>hive</value>
</property>
<property>
<name>javax.jdo.option.ConnectionPassword</name>
<value>hive</value>
</property>
</configuration>
四、启动hive
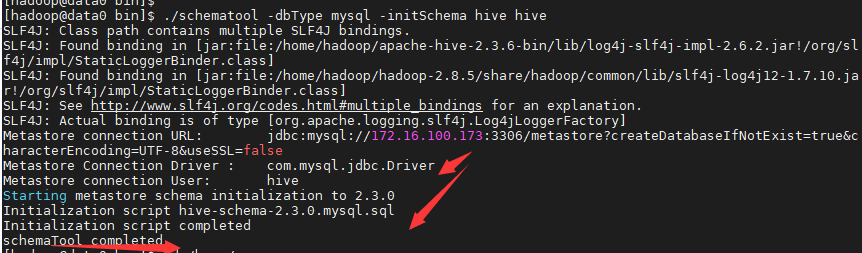
2、启动hive
hive --service metastore

4、一系列操作
hive> create database hdb;
OK
Time taken: 0.309 seconds
hive> show databases;
OK
default
hdb
Time taken: 0.039 seconds, Fetched: 2 row(s)
hive> use hdb;
OK
Time taken: 0.046 seconds
hive> create table htest(name string,age string);
OK
Time taken: 0.85 seconds
hive> show tables;
OK
htest
Time taken: 0.086 seconds, Fetched: 1 row(s)
hive> insert into htest values("xiaoxu","20");
WARNING: Hive-on-MR is deprecated in Hive 2 and may not be available in the future versions. Consider using a different execution engine (i.e. spark, tez) or using Hive 1.X releases.
Query ID = hadoop_20191101102915_f43688b4-25a2-4328-88e0-c13baa088cb7
Total jobs = 3
Launching Job 1 out of 3
Number of reduce tasks is set to 0 since there's no reduce operator
Starting Job = job_1572571873737_0001, Tracking URL = http://data0:8088/proxy/application_1572571873737_0001/
Kill Command = /home/hadoop/hadoop-2.8.5/bin/hadoop job -kill job_1572571873737_0001
Hadoop job information for Stage-1: number of mappers: 1; number of reducers: 0
2019-11-01 10:29:44,724 Stage-1 map = 0%, reduce = 0%
2019-11-01 10:30:00,685 Stage-1 map = 100%, reduce = 0%, Cumulative CPU 1.62 sec
MapReduce Total cumulative CPU time: 1 seconds 620 msec
Ended Job = job_1572571873737_0001
Stage-4 is selected by condition resolver.
Stage-3 is filtered out by condition resolver.
Stage-5 is filtered out by condition resolver.
Moving data to directory hdfs://data0:9000/home/hadoop/hive/data/hdb.db/htest/.hive-staging_hive_2019-11-01_10-29-15_934_2257241779559207950-1/-ext-10000
Loading data to table hdb.htest
MapReduce Jobs Launched:
Stage-Stage-1: Map: 1 Cumulative CPU: 1.62 sec HDFS Read: 4083 HDFS Write: 75 SUCCESS
Total MapReduce CPU Time Spent: 1 seconds 620 msec
OK
Time taken: 47.09 seconds
hive> select * from htest;
OK
xiaoxu 20
Time taken: 0.357 seconds, Fetched: 1 row(s)
hive>
再次查看则data有数据了
hadoop fs -ls /home/hadoop/hive/data/

Hive-2.3.6 安装的更多相关文章
- Hive的三种安装方式(内嵌模式,本地模式远程模式)
一.安装模式介绍: Hive官网上介绍了Hive的3种安装方式,分别对应不同的应用场景. 1.内嵌模式(元数据保村在内嵌的derby种,允许一个会话链接,尝试多个会话链接时会报错) ...
- Hive学习之一 《Hive的介绍和安装》
一.什么是Hive Hive是建立在 Hadoop 上的数据仓库基础构架.它提供了一系列的工具,可以用来进行数据提取转化加载(ETL),这是一种可以存储.查询和分析存储在 Hadoop 中的大规模数据 ...
- Hive基础概念、安装部署与基本使用
1. Hive简介 1.1 什么是Hive Hives是基于Hadoop的一个数据仓库工具,可以将结构化的数据文件映射为一张数据库表,并提供类SQL查询功能. 1.2 为什么使用Hive ① 直接使用 ...
- Hive/Hbase/Sqoop的安装教程
Hive/Hbase/Sqoop的安装教程 HIVE INSTALL 1.下载安装包:https://mirrors.tuna.tsinghua.edu.cn/apache/hive/hive-2.3 ...
- Hive 2.1.1安装配置
##前期工作 安装JDK 安装Hadoop 安装MySQL ##安装Hive ###下载Hive安装包 可以从 Apache 其中一个镜像站点中下载最新稳定版的 Hive, apache-hive-2 ...
- Hive的介绍及安装
简介 Hive 是基于 Hadoop 的一个数据仓库工具,可以将结构化的数据文件 映射为一张数据库表,并提供类 SQL 查询功能. 本质是将 SQL 转换为 MapReduce 程序. Hive组件 ...
- HIVE 2.1.0 安装教程。(数据源mysql)
前期工作 安装JDK 安装Hadoop 安装MySQL 安装Hive 下载Hive安装包 可以从 Apache 其中一个镜像站点中下载最新稳定版的 Hive, apache-hive-2.1.0-bi ...
- Mac OSX系统中Hadoop / Hive 与 spark 的安装与配置 环境搭建 记录
Mac OSX系统中Hadoop / Hive 与 spark 的安装与配置 环境搭建 记录 Hadoop 2.6 的安装与配置(伪分布式) 下载并解压缩 配置 .bash_profile : ...
- Hive[1] 初识 及 安装
本文前提是Hadoop & Java & mysql 数据库,已经安装配置好,并且 环境变量均已经配置到位 声明:本笔记参照 学习<Hive 编程指南>而来,如果有错误 ...
- Hive从概念到安装使用总结
一.Hive的基本概念 1.1 hive是什么? (1)Hive是建立在hadoop数据仓库基础之上的一个基础架构: (2)相当于hadoop之上的一个客户端,可以用来存储.查询和分析存储在hadoo ...
随机推荐
- Navicat12下载、激活工具、激活教程
Navicat12的下载地址如下:链接: https://pan.baidu.com/s/11CHIWO74M4-P6UG0aWsF7Q 提取码: bayk 打开激活工具Navicat_Keygen_ ...
- zap+日志分级分文件+按时间切割日志整合demo
实现功能 info debug 级别的日志输出到 /path/log/demo.log warn error .... 级别的日志输出到 /path/log/demo_error.lo ...
- go 学习笔记(4) import
package main import ( f "fmt" ) const NAME string = "imooc" var a string = " ...
- vue 项目中assets 和static的区别
一.Webpacked Assets 为了回答这个问题,我们首先需要了解Webpack如何处理静态资产.在 *.vue 组件中,所有模板和CSS都会被 vue-html-loader 及 css-lo ...
- Expanded, SingleChildScrollView, CustomScrollView, container, height, width
SingleChildScrollView, CustomScrollView, container, init: double.inifinity. then use Expanded to con ...
- OO——JML作业总结
目录 第三单元博客作业 JML语言理论基础 1.注释结构 2.JML表达式 3.方法规格 4.类型规格 应用工具链 JMLUnitNG使用实例 作业架构设计 第一次作业 第二次作业 第三次作业 BUG ...
- jQuery中的 AJAX
jQuery库中支持AJAX的操作,功能十分完善 详细请参考官方文档:https://www.jquery123.com/category/ajax/ 首先需要引入jquery文件!!! $.ajax ...
- 将h5用HBuilderX打包成安卓app后,document.documentElement.scrollTop的值始终为0或者document.body.scrollTop始终为0
let time = setInterval(() => { let scroll = document.documentElement.scrollTop || document.body.s ...
- Vue中v-model解析、sync修饰符解析
上善若水,水善利萬物而不爭.——<道德經> 简介 在平时开发是经常用到一些父子组件通信,经常用到props.vuex等等,这里面记录另外的三种方式v-model.sync是怎么使用,再说是 ...
- vs2017开启JavaScript智能提示
[工具]--[选项]--[文本编辑器]--[JavaScript]--[语言服务] 把第一个钩去掉即可,如果不需要提示就打上勾