R数据挖掘 第三篇:聚类的评估(簇数确定和轮廓系数)和可视化
在实际的聚类应用中,通常使用k-均值和k-中心化算法来进行聚类分析,这两种算法都需要输入簇数,为了保证聚类的质量,应该首先确定最佳的簇数,并使用轮廓系数来评估聚类的结果。
一,k-均值法确定最佳的簇数
通常情况下,使用肘方法(elbow)以确定聚类的最佳的簇数,肘方法之所以是有效的,是基于以下观察:增加簇数有助于降低每个簇的簇内方差之和,给定k>0,计算簇内方差和var(k),绘制var关于k的曲线,曲线的第一个(或最显著的)拐点暗示正确的簇数。
1,使用sjc.elbow()函数计算肘值
sjPlot包中sjc.elbow()函数实现了肘方法,用于计算k-均值聚类分析的肘值,以确定最佳的簇数:
library(sjPlot)
sjc.elbow(data, steps = 15, show.diff = FALSE)
参数注释:
- steps:最大的肘值的数量
- show.diff:默认值是FALSE,额外绘制一个图,连接每个肘值,用于显示各个肘值之间的差异,改图有助于识别“肘部”,暗示“正确的”簇数。
sjc.elbow()函数用于绘制k-均值聚类分析的肘值,该函数在指定的数据框计算k-均值聚类分析,产生两个图形:一个图形具有不同的肘值,另一个图形是连接y轴上的每个“步”,即在相邻的肘值之间绘制连线,第二个图中曲线的拐点可能暗示“正确的”簇数。
绘制k均值聚类分析的肘部值。 该函数计算所提供的数据帧上的k均值聚类分析,并产生两个图:一个具有不同的肘值,另一个图绘制在y轴上的每个“步”(即在肘值之间)之间的差异。 第二个图的增加可能表明肘部标准。
library(effects)
library(sjPlot)
library(ggplot2) sjc.elbow(data,show.diff = FALSE)
从下面的肘值图中,可以看出曲线的拐点大致在5附近:
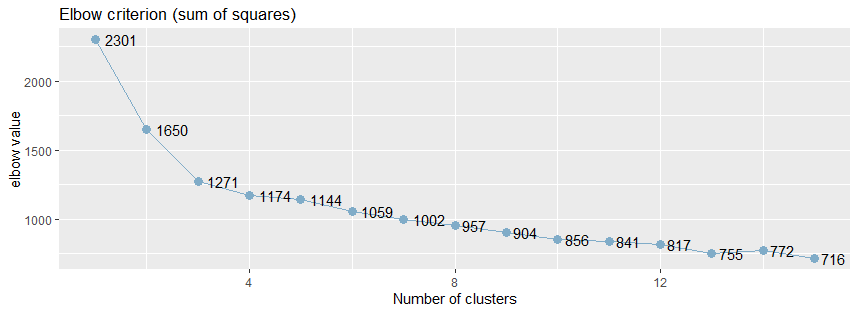
2,使用NbClust()函数来验证肘值
从上面肘值图中,可以看到曲线的拐点是3,还可以使用NbClust包种的NbClust()函数,默认情况下,该函数提供了26个不同的指标来帮助确定簇的最终数目。
NbClust(data = NULL, diss = NULL, distance = "euclidean", min.nc = , max.nc = , method = NULL, index = "all", alphaBeale = 0.1)
参数注释:
- diss:相异性矩阵(dissimilarity matrix),默认值是NULL,如果diss参数不为NULL,那么忽略distance参数。
- distance:用于计算相异性矩阵的距离度量,有效值是: "euclidean", "maximum", "manhattan", "canberra", "binary", "minkowski" 和"NULL"。如果distance不是NULL,diss(相异性矩阵)参数必须为NULL。
- min.nc:最小的簇数
- max.nc:最大的簇数
- method:用于聚类分析的方法,有效值是:"ward.D", "ward.D2", "single", "complete", "average", "mcquitty", "median", "centroid", "kmeans"
- index:用于计算的指标,NbClust()函数提供了30个指数,默认值是"all",是指除GAP、Gamma、Gplus 和 Tau之外的26个指标。
- alphaBeale:Beale指数的显著性值
利用NbClust()函数来确定k-均值聚类的最佳簇数:
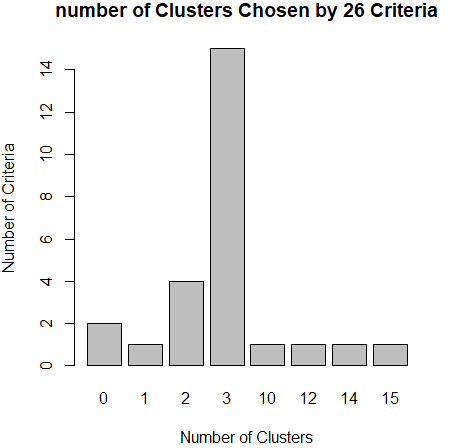
library(NbClust) nc <- NbClust(data,min.nc = 2,max.nc = 15,method = "kmeans")
barplot(table(nc$Best.nc[1,]),xlab="Number of Clusters",ylab="Number of Criteria",main="number of Clusters Chosen by 26 Criteria")
从条形图种,可以看到支持簇数为3的指标(Criteria)的数量是最多的,因此,基本上可以确定,k-均值聚类的簇数目是3。
二,k-中心化确定最佳簇数
k-中心化聚类有两种实现方法,PAM和CLARA,PAM适合在小型数据集上运行,CLARA算法基于抽样,不考虑整个数据集,而是使用数据集的一个随机样本,然后使用PAM方法计算样本的最佳中心点。
通过fpc包中的pamk()函数得到最佳簇数:
pamk(data,krange=:,criterion="asw", usepam=TRUE,
scaling=FALSE, alpha=0.001, diss=inherits(data, "dist"),
critout=FALSE, ns=, seed=NULL, ...)
参数注释:
- krange:整数向量,用于表示簇的数量
- criterion:有效值是:"asw"(默认值)、 "multiasw" 和 "ch"
- usepam:逻辑值,如果设置为TRUE,那么使用pam算法,如果为FALSE,那么使用clara算法。
- scaling:逻辑值,是否对数据进行缩放(标准化),如果设置为FALSE,那么不对data参数做任何缩放;如果设置为TRUE,那么对data参数通过把(中间)变量除以它们的均方根来完成缩放。
- diss:逻辑值,如果设置为TRUE,表示data参数是相异性矩阵;如果设置为FALSE,那么data参数是观测矩阵。
使用pamk()函数获得PAM或CLARA聚类的最佳簇数:
library(fpc)
pamk.best <- pamk(dataset)
pamk.best$nc
通过cluster包中的clusplot()函数来查看聚类的结果:
library(cluster)
clusplot(pam(dataset, pamk.best$nc))
三,评估聚类的质量(轮廓系数)
使用数据集中对象之间的相似性度量来评估聚类的质量,轮廓系数(silhouette coefficient)就是这种相似性度量,是簇的密集与分散程度的评价指标。轮廓系数的值在-1和1之间,该值越接近于1,簇越紧凑,聚类越好。当轮廓系数接近1时,簇内紧凑,并远离其他簇。
如果轮廓系数sil 接近1,则说明样本聚类合理;如果轮廓系数sil 接近-1,则说明样本i更应该分类到另外的簇;如果轮廓系数sil 近似为0,则说明样本i在两个簇的边界上。所有样本的轮廓系数 sil的均值称为聚类结果的轮廓系数,是该聚类是否合理、有效的度量。
1,fpc包
包fpc中实现了计算聚类后的一些评价指标,其中就包括了轮廓系数:avg.silwidth(平均的轮廓宽度)
library(fpc)
result <- kmeans(data,k)
stats <- cluster.stats(dist(data)^2, result$cluster)
sli <- stats$avg.silwidth
2,silhouette()函数
包cluster中计算轮廓系数的函数silhouette(),返回聚类的平均轮廓宽度:
silhouette(x, dist, dmatrix, ...)
参数注释:
- x:整数向量,是聚类算法的结果
- dist:相异性矩阵(是dist()函数计算的结果),如果dist参数不指定,那么dmatrix参数必须指定;
- dmatrix:对称性的相异性矩阵,用于代替dist参数,比dist参数更有效率
使用silhouette()计算轮廓系数:
library (cluster)
library (vegan) #pam
dis <- vegdist(data)
res <- pam(dis,)
sil <- silhouette (res$clustering,dis) #kmeans
dis <- dist(data)^
res <- kmeans(data,)
sil <- silhouette (res$cluster, dis)
四,聚类的可视化
聚类的结果,可以试用ggplot2来可视化,还可以使用的一些聚类包中特有的函数来实现:factoextra包,sjPlot包和cluster包
1,cluster包
clusplot()函数
2,sjPlot包
sjc.qclus()函数
3,factoextra包
该包中的两个函数十分有用,一个用于确定最佳的簇数,一个用于可视化聚类的结果。
(1),确定最佳的簇数fviz_nbclust()
函数fviz_nbclust(),用于划分聚类分析中,使用轮廓系数,WSS(簇内平方误差和)确定和可视化最佳的簇数
fviz_nbclust(x, FUNcluster = NULL, method = c("silhouette", "wss",), diss = NULL, k.max = , ...)
参数注释:
- FUNcluster:用于聚类的函数,可用的值是: kmeans, cluster::pam, cluster::clara, cluster::fanny, hcut等
- method:用于评估最佳簇数的指标
- diss:相异性矩阵,由dist()函数产生的对象,如果设置为NULL,那么表示使用 dist(data, method="euclidean") 计算data参数,得到相异性矩阵;
- k.max:最大的簇数量,至少是2
例如,使用kmenas进行聚类分析,使用平均轮廓宽度来评估聚类的簇数:
library(factoextra)
fviz_nbclust(dataset, kmeans, method = "silhouette")
(2),可视化聚类的结果
fviz_cluster()函数用于可是化聚类的结果:
fviz_cluster(object, data = NULL, choose.vars = NULL, stand = TRUE,
axes = c(, ), geom = c("point", "text"), repel = FALSE,
show.clust.cent = TRUE, ellipse = TRUE, ellipse.type = "convex",
ellipse.level = 0.95, ellipse.alpha = 0.2, shape = NULL,
pointsize = 1.5, labelsize = , main = "Cluster plot", xlab = NULL,
ylab = NULL, outlier.color = "black", outlier.shape = ,
ggtheme = theme_grey(), ...)
参数注释:
- object:是聚类函数计算的结果
- data:原始对象数据集
使用fviz_cluster()把聚类的结果显示出来:
km.res <- kmeans(dataset,)
fviz_cluster(km.res, data = dataset)
参考文档:
R数据挖掘 第三篇:聚类的评估(簇数确定和轮廓系数)和可视化的更多相关文章
- python数据挖掘第三篇-垃圾短信文本分类
数据挖掘第三篇-文本分类 文本分类总体上包括8个步骤.数据探索分析->数据抽取->文本预处理->分词->去除停用词->文本向量化表示->分类器->模型评估.重 ...
- R中K-Means、Clara、C-Means三种聚类的评估
R中cluster中包含多种聚类算法,下面通过某个数据集,进行三种聚类算法的评估 # ============================ # 评估聚类 # # ================= ...
- R实战 第三篇:数据处理(基础)
数据结构用于存储数据,不同的数据结构对应不同的操作方法,对应不同的分析目的,应选择合适的数据结构.在处理数据时,为了便于检查数据对象,可以通过函数attributes(x)来查看数据对象的属性,str ...
- R实战 第三篇:数据处理
在实际分析数据之前,必须对数据进行清理和转化,使数据符合相应的格式,提高数据的质量.数据处理通常包括增加新的变量.处理缺失值.类型转换.数据排序.数据集的合并和获取子集等. 一,增加新的变量 通常需要 ...
- 聚类时的轮廓系数评价和inertia_
在进行聚类分析时,机器学习库中提供了kmeans++算法帮助训练,然而,根据不同的问题,需要寻找不同的超参数,即寻找最佳的K值 最近使用机器学习包里两个内部评价聚类效果的方法:clf=KMeans(n ...
- 数学建模及机器学习算法(一):聚类-kmeans(Python及MATLAB实现,包括k值选取与聚类效果评估)
一.聚类的概念 聚类分析是在数据中发现数据对象之间的关系,将数据进行分组,组内的相似性越大,组间的差别越大,则聚类效果越好.我们事先并不知道数据的正确结果(类标),通过聚类算法来发现和挖掘数据本身的结 ...
- R数据挖掘 第一篇:聚类分析(划分)
聚类是把一个数据集划分成多个子集的过程,每一个子集称作一个簇(Cluster),聚类使得簇内的对象具有很高的相似性,但与其他簇中的对象很不相似,由聚类分析产生的簇的集合称作一个聚类.在相同的数据集上, ...
- itemKNN发展史----推荐系统的三篇重要的论文解读
itemKNN发展史----推荐系统的三篇重要的论文解读 本文用到的符号标识 1.Item-based CF 基本过程: 计算相似度矩阵 Cosine相似度 皮尔逊相似系数 参数聚合进行推荐 根据用户 ...
- [置顶] android利用jni调用第三方库——第三篇——编写库android程序整合第三方库libhello.so到自己的库libhelloword.so
0:前言: 在第二篇中,我们主要介绍了丙方android公司利用乙方C++公司给的动态库,直接调用库中的方法,但是这样方式受限于: 乙方C++公司开发的动态库是否符合jni的规范,如果不规范,则不能直 ...
随机推荐
- 怎么把使用vuepress搭建的博客部署到Github Pages
推荐在这里阅读效果更佳 背景 网上搜了很多教程,包括官网的教程,但是还是费了一番功夫, 如果你使用自动化部署脚本部署不成功的话,可以参考我的这个笨方法 这是部署后的效果 前提 我假设你本地运行OK, ...
- windows zlib库编译步骤
下载地址 http://www.zlib.net/ 动态库下载地址 如果自己实在不想编译的,可以直接下载 https://download.csdn.net/download/zhangxuechao ...
- BBR加速 Centos
BBR是什么 BBR 是 Google 提出的一种新型拥塞控制算法,可以使 Linux 服务器显著地提高吞吐量和减少 TCP 连接的延迟. BBR项目地址 https://github.com/goo ...
- spring boot的异常处理
原文:https://blog.csdn.net/tianyaleixiaowu/article/details/70145251 全局异常处理是个比较重要的功能,一般在项目里都会用到. 我大概把一次 ...
- Centos7 安装 zabbix 4.0
参考文档: https://www.zabbix.com/download?zabbix=4.0&os_distribution=centos&os_version=7&db= ...
- Win10更新后wireshark无法获取网络接口
一不小心win10自动更新了,打开wireshark发现它无法发现本地的网络接口. 其实解决的办法很简单,就是卸载npcap,安装Win10Pcap即可解决.
- 1.python进行if条件相等时候的条件
在我们进行 if == 判断的时候!其中判断的条件: 1:其值是不是一样 3:其类型是否是一样 ###二者少了任何一个都不可以 >>> pwd = 23>>> cc ...
- 【软件工程1916|W(福州大学)_助教博客】2019年上学期助教个人总结
本学期概况 本学期负责福州大学汪老师助教工作,机缘巧合下半路接上的.说起来和福州大学也很有缘,第一次做助教就是给福州大学的张老师打下手[福州大学助教链接].第一次是和我室友共同组合.本学期有幸和其他两 ...
- shell 之while两种写法
1.while[] #!/bin/dash min= max= while [ $min -le $max ] do echo $min min=`` done 2. while(()) #!/bin ...
- leetcode203. 移除链表元素
方法一(删除头结点时另做考虑) class Solution { public: ListNode* removeElements(ListNode* head, int val) { if(head ...