Learning to rank基本算法
搜索排序相关的方法,包括
- Learning to rank 基本方法
- Learning to rank 指标介绍
- LambdaMART 模型原理
- FTRL 模型原理
Learning to rank
排序学习是推荐、搜索、广告的核心方法。排序结果的好坏很大程度影响用户体验、广告收入等。
排序学习可以理解为机器学习中用户排序的方法,这里首先推荐一本微软亚洲研究院刘铁岩老师关于LTR的著作,Learning to Rank for Information Retrieval,书中对排序学习的各种方法做了很好的阐述和总结。我这里是一个超级精简版。
排序学习是一个有监督的机器学习过程,对每一个给定的查询-文档对,抽取特征,通过日志挖掘或者人工标注的方法获得真实数据标注。然后通过排序模型,使得输入能够和实际的数据相似。
常用的排序学习分为三种类型:PointWise,PairWise和ListWise。
PointWise
单文档方法的处理对象是单独的一篇文档,将文档转换为特征向量后,机器学习系统根据从训练数据中学习到的分类或者回归函数对文档打分,打分结果即是搜索结果
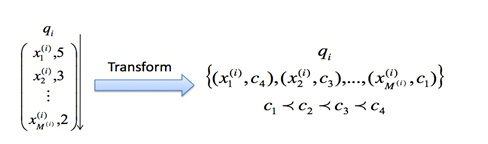
PointWise方法很好理解,即使用传统的机器学习方法对给定查询下的文档的相关度进行学习,比如CTR就可以采用PointWise的方法学习,但是有时候排序的先后顺序是很重要的,而PointWise方法学习到全局的相关性,并不对先后顺序的优劣做惩罚。
PairWise
对于搜索系统来说,系统接收到用户査询后,返回相关文档列表,所以问题的关键是确定文档之间的先后顺序关系。单文档方法完全从单个文档的分类得分角度计算,没有考虑文档之间的顺序关系。文档对方法将排序问题转化为多个pair的排序问题,比较不同文章的先后顺序。

但是文档对方法也存在如下问题:
文档对方法考虑了两个文档对的相对先后顺序,却没有考虑文档出现在搜索列表中的位置,排在搜索结果前面的文档更为重要,如果靠前的文档出现判断错误,代价明显高于排在后面的文档。
同时不同的査询,其相关文档数量差异很大,所以转换为文档对之后, 有的查询对能有几百个对应的文档对,而有的查询只有十几个对应的文档对,这对机器学习系统的效果评价造成困难
常用PairWise实现:
- SVM Rank
- RankNet(2007)
- RankBoost(2003)
ListWise:
单文档方法将训练集里每一个文档当做一个训练实例,文档对方法将同一个査询的搜索结果里任意两个文档对作为一个训练实例,文档列表方法与上述两种方法都不同,ListWise方法直接考虑整体序列,针对Ranking评价指标进行优化。比如常用的MAP, NDCG。常用的ListWise方法有:
- LambdaRank
- AdaRank
- SoftRank
- LambdaMART
Learning to rank指标介绍
MAP(Mean Average Precision):
假设有两个主题,主题1有4个相关网页,主题2有5个相关网页。某系统对于主题1检索出4个相关网页,其rank分别为1, 2, 4, 7;对于主题2检索出3个相关网页,其rank分别为1,3,5。对于主题1,平均准确率为(1/1+2/2+3/4+4/7)/4=0.83。对于主题2,平均准确率为(1/1+2/3+3/5+0+0)/5=0.45。则MAP= (0.83+0.45)/2=0.64。NDCG(Normalized Discounted Cumulative Gain):
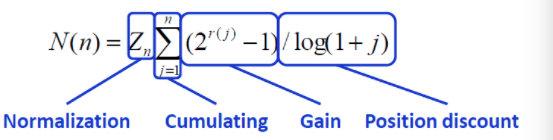 NDCG把相关度分为r个等级,如果r=5,等级设定分别文2^5-1,2^4-1等等
NDCG把相关度分为r个等级,如果r=5,等级设定分别文2^5-1,2^4-1等等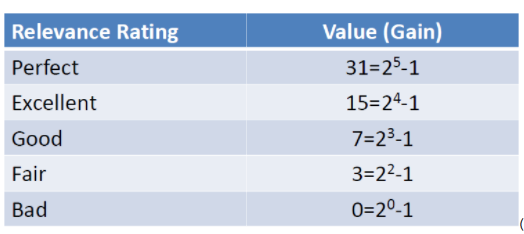
那么加入现在有一个query为abc, 返回如下图所示的列表,假设用户选择和排序结果无关,则累积增益值如右列所示:
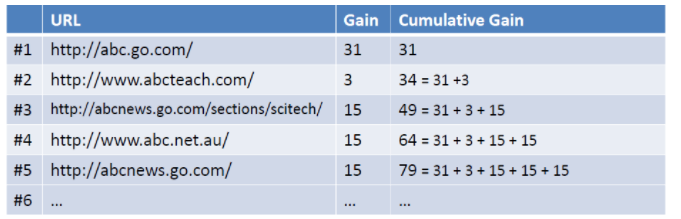
考虑到靠前的位置点击概率越大,那么靠下的位置需要加上衰减因子
log2/log(1+j),求和就可以得到DCG的值,最后为了使得不同不搜索结果可以比较,用DCG/MaxDCG就可以得到NDCG的值了。
MaxDCG就是当前情况下最佳排序的DCG值。如图所示MaxDCG就是1、3、4、5、2的排序情况下的DCG的值(rank 2的gain较低,应该排到后面)
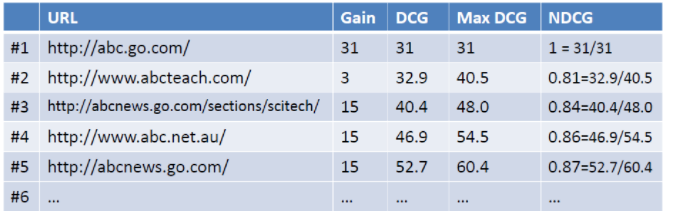
NDCG值
- MRR(Mean Reciprocal Rank)
给定查询q,q在相关文档的位置是r,那么MRR(q)就是1/R
LambdaMART算法:
LambdaMART是Learning to rank其中的一个算法,在Yahoo! Learning to Rank Challenge比赛中夺冠队伍用的就是这个模型。
LambdaMART模型从名字上可以拆分成Lambda和MART两部分,训练模型采用的是MART也就是GBDT,lambda是MART求解使用的梯度,其物理含义是一个待排序文档下一次迭代应该排序的方向。
但Lambda最初并不是诞生于LambdaMART,而是在LambdaRank模型中被提出,而LambdaRank模型又是在RankNet模型的基础上改进而来。所以了解LambdaRank需要从RankNet开始说起。
论文:
From RankNet to LambdaRank to LambdaMART: AnOverview
RankNet
RankNet是一个pairwise模型,上文介绍在pairwise模型中,将排序问题转化为多个pair的排序问题,比较文档di排在文档dj之前的概率。如下图所示
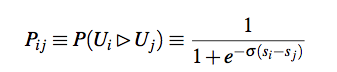
最终的输出的sigmoid函数,RankNet采用神经网络模型优化损失函数,故称为RankNet。
可是这样有什么问题呢?排序指标如NDCG、MAP和MRR都不是平滑的函数,RankNet的方法采用优化损失函数来间接优化排序指标。
LambdaRank
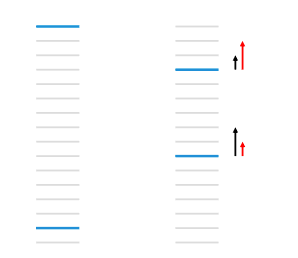
如图所示,蓝色表示相关的文档,灰色表示不相关的文档。RankNet以pairwise计算cost左边为13,右图将第一个文档下调3个位置,将第二个文档下调5个位置,cost就降为11。如此以来,虽然RankNet的损失函数得到优化,但是NDCG和ERR等指标却下降了。
RankNet优化的方向是黑色箭头,而我们想要的其实是红色的箭头。LambdaRank就是基于这个,其中lambda表示红色箭头。
LambdaRank不是通过显示定义损失函数再求梯度的方式对排序问题进行求解,而是分析排序问题需要的梯度的物理意义,直接定义梯度,Lambda梯度由两部分相乘得到:(1)RankNet中交叉熵概率损失函数的梯度;(2)交换Ui,Uj位置后IR评价指标Z的差值。具体如下:
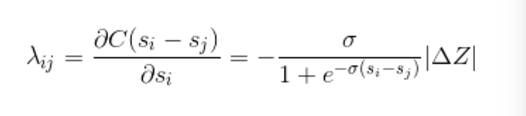
lambdaMART
我们知道GBDT算法每一次迭代中, 需要学习上一次结果和真实结果的残差。在lambdaMART中,每次迭代用的并不是残差,lambda在这里充当替代残差的计算方法。
- LambdaMART算法流程

- GBDT算法流程

对比lambdaMART和GBDT算法流程,主要框架是相同的,只不过LambdaMART模型用lambda梯度代替了GBDT的残差。
FTRL算法(Follow the regularized Leader Proximal)
论文: Ad click prediction: a view from the trenches
点击率预估问题(CTR)是搜索、广告和推荐中一个非常重要的模块。在CTR计算的过程中,常常采用LR模型。
FTRL属于在线算法,和SGD等常用的在线优化方法对比,可以产生较好的稀疏性,非常适合ID特征较多,维度较高的特征。
google的论文中已经给出了很详细的工程化实现的说明,该方法也已经广泛的应用。
- 参数优化

第一项:保证参数不偏移历史参数
第二项:保证w不会变化太大
第三项:代表L1正则,获得稀疏解
- 算法流程:

感谢答主整理:https://zhuanlan.zhihu.com/p/26539920
xgboost L2R:https://blog.csdn.net/seasongirl/article/details/100178083
很全面的LTR介绍: https://blog.csdn.net/anshuai_aw1/article/details/86018105
RankNet、LambdaRank和LambdaMART 算法细节讲解:https://www.cnblogs.com/genyuan/p/9788294.html
机器学习算法中 GBDT 和 XGBOOST 的区别有哪些?
https://www.zhihu.com/question/41354392?sort=created
Learning to rank基本算法的更多相关文章
- 芝麻HTTP: Learning to Rank概述
Learning to Rank,即排序学习,简称为 L2R,它是构建排序模型的机器学习方法,在信息检索.自然语言处理.数据挖掘等场景中具有重要的作用.其达到的效果是:给定一组文档,对任意查询请求给出 ...
- [Machine Learning] Learning to rank算法简介
声明:以下内容根据潘的博客和crackcell's dustbin进行整理,尊重原著,向两位作者致谢! 1 现有的排序模型 排序(Ranking)一直是信息检索的核心研究问题,有大量的成熟的方法,主要 ...
- [笔记]Learning to Rank算法介绍:RankNet,LambdaRank,LambdaMart
之前的博客:http://www.cnblogs.com/bentuwuying/p/6681943.html中简单介绍了Learning to Rank的基本原理,也讲到了Learning to R ...
- Learning to Rank算法介绍:RankNet,LambdaRank,LambdaMart
之前的博客:http://www.cnblogs.com/bentuwuying/p/6681943.html中简单介绍了Learning to Rank的基本原理,也讲到了Learning to R ...
- Learning to Rank之RankNet算法简介
排序一直是信息检索的核心问题之一, Learning to Rank(简称LTR)用机器学习的思想来解决排序问题(关于Learning to Rank的简介请见我的博文Learning to Rank ...
- Learning to Rank算法介绍:GBRank
之前的博客:http://www.cnblogs.com/bentuwuying/p/6681943.html中简单介绍了Learning to Rank的基本原理,也讲到了Learning to R ...
- Learning to Rank算法介绍:RankSVM 和 IR SVM
之前的博客:http://www.cnblogs.com/bentuwuying/p/6681943.html中简单介绍了Learning to Rank的基本原理,也讲到了Learning to R ...
- Learning to rank 介绍
PS:文章主要转载自CSDN大神hguisu的文章"机器学习排序": http://blog.csdn.net/hguisu/article/details/79 ...
- learning to rank
Learning to Rank入门小结 + 漫谈 Learning to Rank入门小结 Table of Contents 1 前言 2 LTR流程 3 训练数据的获取4 特征抽取 3.1 人工 ...
随机推荐
- Vue.js源码中大量采用的ES6新特性介绍:模块、let、const
1 关于ES6 ECMAScript6(以下简称ES6)是JavaScript语言的最新一代标准,发布于2015年6月,因为ECMA委员会决定从ES6起每年更新一次标准,因此ES6被改名为E ...
- Java List<String> list=new ArrayList<String>();为什么要声明为List,而不是ArrayList<String>
例如:代码List list = new ArrayList(); 下面通过list来操作集合.假如代码编写后却发现集合使用的不准确,应该使用LinkedList,那么只要修改一行代码List lis ...
- [IC]浅谈嵌入式MCU软件开发之中断优先级与中断嵌套
转自:https://mp.weixin.qq.com/s?__biz=MzI0MDk0ODcxMw==&mid=2247483680&idx=1&sn=c5fd069ab3f ...
- ServicePointManager 类
地址:https://docs.microsoft.com/zh-cn/dotnet/api/system.net.servicepointmanager?redirectedfrom=MSDN&am ...
- 基于Java+Selenium的WebUI自动化测试框架(十四)-----使用TestNG的Sample
到目前为止,我们所写的东西,都是集中在如何使用Selenium和Java来定位和读取元素.那么,到底如何具体开展测试,如何实现参数化,如何实现判定呢?下面,我们来看看Java应用程序的测试框架吧. 当 ...
- 让Jupyter Notebook个性化
Win下更改jupyter主题 Themes地址 本人环境 Win+Conda 开始使用pip 安装,发现无法使用pip,修改环境变量,将D:\Program Files\Conda\Scripts ...
- 思想家:潘石屹学python
1.python在一些算法,图像处理,机器视觉方面越来越重要 2.计算机语言像英语一样,渐渐成为一种非专业技术,不能成为专业,而只能成为一种工具 3.想发挥工具价值,需要与别的专业结合,例如潘总的房地 ...
- 零基础Python教程-函数及模块的使用
函数 在学习本节内容之前,我们先来一起做道数学题. 已知:半径分别为0.1.0.2.0.3的三个圆,分别求这三个圆的面积. 很多读者可能要笑一下,这不是小学的数学问题吗? S = π * r * r ...
- rocketmq那些事儿之集群环境搭建
上一篇入门基础部分对rocketmq进行了一个基础知识的讲解说明,在正式使用前我们需要进行环境的搭建,今天就来说一说rockeketmq分布式集群环境的搭建 前言 之前已经介绍了rocketmq的入门 ...
- 《奋斗吧!菜鸟》第九次团队作业:Beta冲刺
项目 内容 这个作业属于哪个课程 任课教师链接 作业要求 https://www.cnblogs.com/nwnu-daizh/p/11056511.html 团队名称 奋斗吧!菜鸟 作业学习目标 B ...