基于栈的指令集与基于寄存器的指令集的区别,JVM指令集实例
现代JVM在执行Java代码的时候,通常都会将解释执行与编译执行两者结合起来
所谓解释执行,就是通过解释器来读取字节码,遇到相应的指令就去执行该指令。
所谓编译执行,就是通过即时编译器(Just In Time,JIT) 将字节码转为本地机器码来执行;现代JVM会根据代码热点来生成相应的本地机器码。
基于栈的指令集与基于寄存器的指令集直接的关系:
1、JVM执行指令时所采取的方式是基于栈的指令集
2、基于栈的指令集主要的操作有入栈与出栈两种。
3、基于栈的指令集的优势在于它可以在不同平台之间进行移植,而基于寄存器的指令集是与硬件架构紧密关联的,无法做到可移植。
4、基于栈的指令集的缺点在于完成相同的操作,指令数量通常要比基于寄存器的指令集数量要多;基于栈的指令集是在内存中完成操作的,
而基于寄存器的指令集是直接由CPU来执行的,它是在高速缓冲区进行执行的,速度要快很多。虽然虚拟机可以采用一些优化手段,
但总体来说,基于栈的指令集的执行速度要慢一些。
如对数字2-1的操作,基于栈和基于寄存器的区别
基于栈的指令
1.iconst_1 //将减数1压入栈顶
2.iconst_2 //将被减数2压入栈顶
3.isub //将栈中最上面的两个元素(2和1)弹出来,执行2-1的操作,将2-1的结果1压入栈顶
4.istore_0 //将1放入局部变量表的第0个位置上。
基于寄存器
mov 将2放入寄存器,
sub 后面跟一个参数1,在现有的寄存器上减去1,在把结果放回寄存器。
JVM指令集实例
创建MyTest8.java类
public class MyTest8 {
public int myCalculate(){
int a = 1;
int b = 2;
int c = 3;
int d = 4;
int result = (a + b - c) * d;
return result;
}
}
使用jclasslib查看myCalculate方法
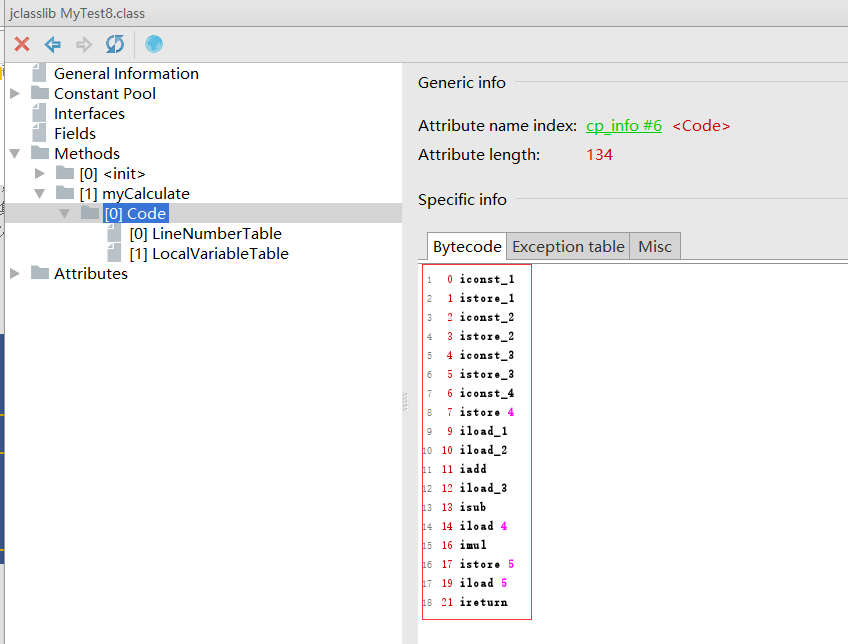
这21条指令就是myCalculat方法的操作步骤
0 iconst_1 //将1放入操作数栈顶
1 istore_1 //弹出操作数栈顶元素,并把元素的值复制到本地变量表索引为1的位置。
2 iconst_2 //将2放入操作数栈顶
3 istore_2 //弹出操作数栈顶元素,并把元素的值复制到本地变量表索引为2的位置。
4 iconst_3 //将3放入操作数栈顶
5 istore_3 //弹出操作数栈顶元素,并把元素的值复制到本地变量表索引为3的位置。
6 iconst_4 //将4放入操作数栈顶
7 istore 4 //弹出操作数栈顶元素,并把元素的值复制到本地变量表索引为4的位置。
9 iload_1 //从本地变量表中索引为1的值压入操作数栈
10 iload_2 //从本地变量表中索引为2的值压入操作数栈
11 iadd //弹出操作数栈最上层的两个元素,进行加操作(1+2),将结果3压入操作数栈
12 iload_3 //从本地变量表中索引为3的值压入操作数栈
13 isub //弹出操作数栈最上层的两个元素,进行减操作(3-3),将结果0压入操作数栈
14 iload 4 //从本地变量表中索引为4的值压入操作数栈
16 imul //弹出操作数栈最上层的两个元素,进行乘法操作(0 * 4),将结果0压入操作数栈
17 istore 5 //弹出操作数栈顶元素,并把元素的值复制到本地变量表索引为5的位置。
19 iload 5 //从本地变量表中索引为5的值压入操作数栈
21 ireturn //弹出当前操作数栈顶元素,将值压到调用者的操作数栈中。当前操作数栈的所有元素都将被丢弃。
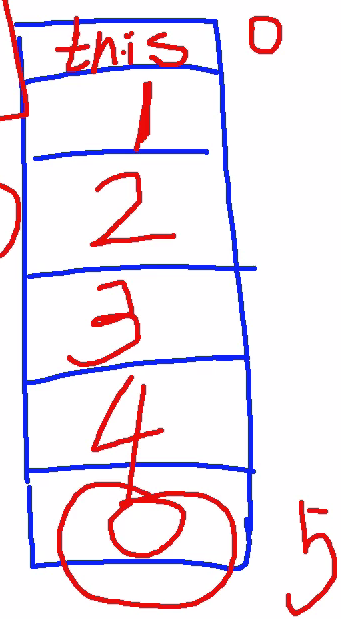
本地变量表如下图
基于栈的指令集与基于寄存器的指令集的区别,JVM指令集实例的更多相关文章
- 基于栈的指令集与基于寄存器的指令集详细比对及JVM执行栈指令集实例剖析
基于栈的指令集与基于寄存器的指令集详细比对: 这次来学习一些新的概念:关于Java字节码的解释执行的一种方式,当然啦是一些纯理论的东东,但很重要,在之后会有详细的实验来对理论进行巩固滴,下面来了解一下 ...
- JVM笔记 -- JVM的发展以及基于栈的指令集架构
2011年,JDK7发布,1.7u4中,开始启用新的垃圾回收器G1(但是不是默认). 2017年,发布JDK9,G1成为默认GC,代替CMS.(一般公司使用jdk8的时候,会通过参数,指定GC为G1) ...
- jvm 字节码执行 (二)动态类型支持与基于栈的字节码解释执行
动态类型语言 动态类型语言的关键特征是它的类型检查的主体过程是在运行期而不是编译期. 举例子解释“类型检查”,例如代码: obj.println("hello world"); 假 ...
- Nagios Core/Icinga 基于栈的缓冲区溢出漏洞
漏洞名称: Nagios Core/Icinga 基于栈的缓冲区溢出漏洞 CNNVD编号: CNNVD-201402-484 发布时间: 2014-03-03 更新时间: 2014-03-03 危害等 ...
- [原创]基于Zynq PS与PL之间寄存器映射 Standalone & Linux 例程
基于Zynq PS与PL之间寄存器映射 Standalone & Linux 例程 待添加完善中
- C#编程(七十六)----------使用指针实现基于栈的高性能数组
使用指针实现基于栈的高性能数组 以一个案例为主来分析实现方法: using System; using System.Collections.Generic; using System.Linq; u ...
- 基于NodeJS的全栈式开发(基于NodeJS的前后端分离)
也谈基于NodeJS的全栈式开发(基于NodeJS的前后端分离) 前言 为了解决传统Web开发模式带来的各种问题,我们进行了许多尝试,但由于前/后端的物理鸿沟,尝试的方案都大同小异.痛定思痛,今天我们 ...
- Linux Exploit系列之三 Off-By-One 漏洞 (基于栈)
Off-By-One 漏洞 (基于栈) 原文地址:https://bbs.pediy.com/thread-216954.htm 什么是off by one? 将源字符串复制到目标缓冲区可能会导致of ...
- JVM--a == (a = b)基于栈的解释器执行过程
前言 在翻阅ConcurrentLinkedQueue的代码的时候,发现这样一段代码在JDK源码中总是出现. t != (t = tail) 原先总是以为这不就是 t != t ?很是纳闷,遂Demo ...
随机推荐
- 将集群WEB节点静态数据迁移到共享存储器(LNMP环境)
系统版本:Centos 6.5 机器及IP规划如下: 192.168.0.117 MySQL 192.168.0.118 nginx+php 192.168.0.123 nfs ①在NFS机器上 ...
- 一些 SQLite技巧
SQLite自增ID自段 使用方法为 INTEGER PRIMARY KEY AUTOINCREMENT 如: CREATE TABLE 21andy ( id INTEGER PRIMA ...
- Kubernetes- Dashboard 部署
获取dashboard 的yaml文件 wget wget https://raw.githubusercontent.com/kubernetes/dashboard/v1.10.1/src/dep ...
- Redis持久化从rdb切换到aof
要求:不重启redis的情况下,将RDB数据切换到AOF数据中 准备,配置文件已支持RDB持久化 port 6379 daemonize yes pidfile /data/6379/redis.pi ...
- pom中添加插件打包上传源码
<build> <plugins> <plugin> <groupId>org.apache.maven.plugins</groupId> ...
- .net core自定义读取配置文件
新建完成后项目目录下有个 appsettings.json { "Logging": { "LogLevel": { "Default": ...
- HL7入门书
由我翻译HL7书,写给大忙人的HL7 链接:https://pan.baidu.com/s/16MkTj3EIDfFpqRCAIbiC2w 提取码:ndfw
- JVM那些事儿之内存区域
相信绝大多数java开发者或多或少的都应该知道jvm,但是有多少人又深入去了解过,笔者深感自身能力的不足,去看了些资料,觉得还是有必要整理下自己的学习记录,时常回头看看,多看多实践提升自己的能力,故开 ...
- 《你说对就队》第八次团队作业:Alpha冲刺 第二天
<你说对就队>第八次团队作业:Alpha冲刺 项目 内容 这个作业属于哪个课程 [教师博客主页链接] 这个作业的要求在哪里 [作业链接地址] 团队名称 <你说对就队> 作业学习 ...
- Python 冒泡排序只适用位数相同,位数不同用a.sort()方法
数组内容双位数排序: #coding:utf-8 print u"中文" a = ['] b = 0 c = 0 print a i =0 for j in range (len( ...