Es查询工具使用
Kibana按照索引过滤数据
1.创建索引模式
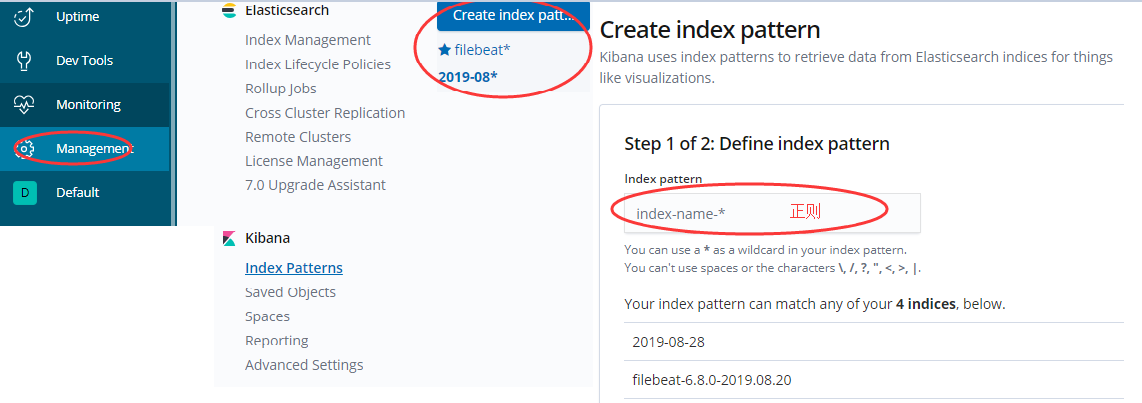
2.查询索引中的数据
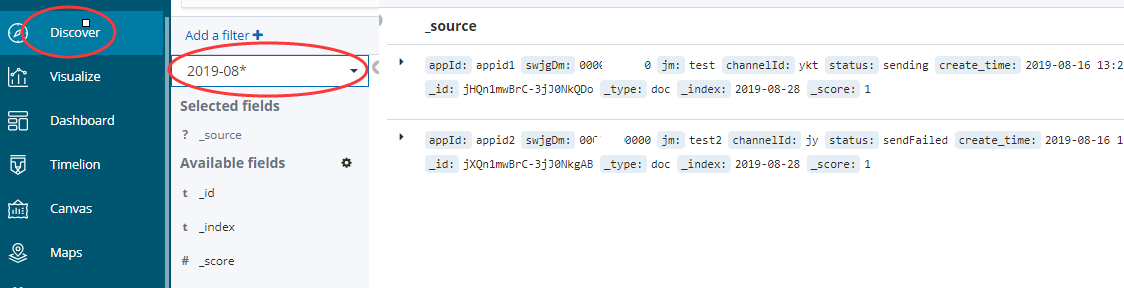
Es查询不返回数据

创建索引的时候指定mapping
mappings={
"mappings": {
"_doc": {
"_source": {
"enabled": True
}
}
}
}
# print("创建新的索引")
es.indices.create(index=indexname,body=mappings)
查询的时候指定返回哪些字段
1.开发工具智能提示查询
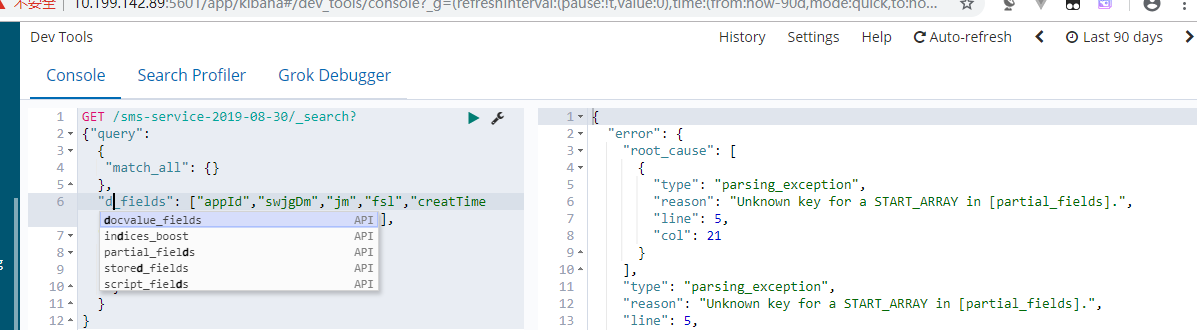

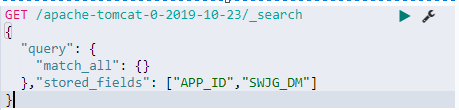
Es处理查询超时问题
class esLogAPI(object):
def __init__(self,url):
self.es = Elasticsearch(url,timeout=50) res = self.es.search(body=body)
手动安装elasticsearch模块
copying elasticsearch6.egg-info/top_level.txt -> build/bdist.linux-x86_64/egg/EGG-INFO
zip_safe flag not set; analyzing archive contents...
creating 'dist/elasticsearch6-6.4.2-py2.7.egg' and adding 'build/bdist.linux-x86_64/egg' to it
removing 'build/bdist.linux-x86_64/egg' (and everything under it)
Processing elasticsearch6-6.4.-py2..egg
Removing /usr/lib/python2./site-packages/elasticsearch6-6.4.-py2..egg
Copying elasticsearch6-6.4.-py2..egg to /usr/lib/python2./site-packages
elasticsearch6 6.4. is already the active version in easy-install.pth Installed /usr/lib/python2./site-packages/elasticsearch6-6.4.-py2..egg
Processing dependencies for elasticsearch6==6.4.
Searching for urllib3==1.24.
Best match: urllib3 1.24.
Adding urllib3 1.24. to easy-install.pth file Using /usr/lib/python2./site-packages
Finished processing dependencies for elasticsearch6==6.4. [root@ elasticsearch6-6.4.]# python
Python 2.7. (default, Jun , ::)
[GCC 4.8. (Red Hat 4.8.-)] on linux2
Type "help", "copyright", "credits" or "license" for more information.
>>> from elasticsearch6 import *
>>> from elasticsearch import *
Traceback (most recent call last):
File "<stdin>", line , in <module>
ImportError: No module named elasticsearch
>>> exit()
Es查询聚合按时间段切分
在聚合得基础上按时间段切分分组可以使用date histogram

body2={"aggs":{"":{"date_histogram":{"field":"mydate","interval":"1d","time_zone":"Asia/Shanghai","min_doc_count":},"aggs":{"":{"cardinality":{"field":"uid"}}}}},"size":,"_source":{"excludes":[]},"stored_fields":["*"],"script_fields":{},"docvalue_fields":[{"field":"@timestamp","format":"date_time"},{"field":"canvas-workpad.@created","format":"date_time"},{"field":"canvas-workpad.@timestamp","format":"date_time"},{"field":"maps-telemetry.timeCaptured","format":"date_time"},{"field":"mydate","format":"date_time"},{"field":"task.runAt","format":"date_time"},{"field":"task.scheduledAt","format":"date_time"},{"field":"updated_at","format":"date_time"},{"field":"url.accessDate","format":"date_time"},{"field":"url.createDate","format":"date_time"}],"query":{"bool":{"must":[{"match_all":{}},{"match_all":{}},{"bool":{"minimum_should_match":,"should":[{"match_phrase":{"czmc":"start:查询明细列表"}}]}},{"range":{"mydate":{"gte":,"lte":,"format":"epoch_millis"}}},{"bool":{"minimum_should_match":,"should":[{"match_phrase":{"czmc":"start:查询明细列表"}}]}}],"filter":[],"should":[],"must_not":[]}},"timeout":"30000ms"}
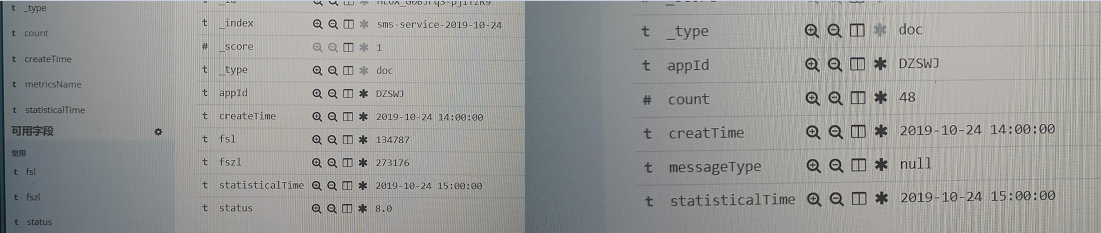
创建自定义索引的时候无法保存自定义列的数据
outlist.append({"channelId":item["key"],"appId":item[""]["buckets"][0]["key"]})
for data in outlist:
res = es.index(index=indexname, doc_type="doc", body=data)
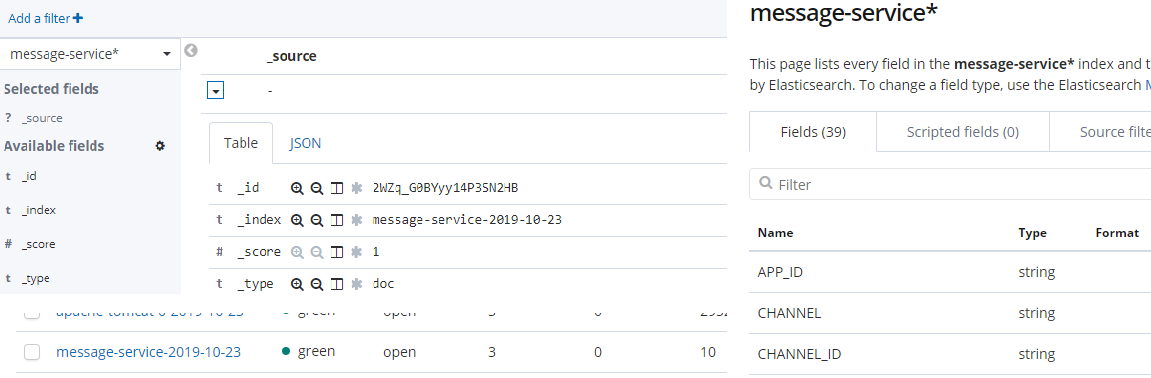
1.修改默认doc类型的mapping,把自定义的列加入到默认mapping配置中
2.把自己的数据存入到在mapping中已经存在的某个字段中
Es查询工具使用的更多相关文章
- Python3实现火车票查询工具
Python 实现火车票查询工具 一. 实验介绍 通过python3实现一个简单的命令行版本的火车票查询工具,用实际中的例子会更感兴趣,不管怎么样,既练习了又可以自己使用. 1. 知识点: Pyth ...
- 域名解析服务查询工具dnstracer
域名解析服务查询工具dnstracer 在访问网站过程中,当用户输入网址后,通常是先解析域名,获取该网站的IP地址.然后,根据IP地址访问对应的网站服务器.所以,域名解析服务器保证域名指向正确的网 ...
- dig 常用的域名查询工具
dig 命令是常用的域名查询工具,可以用来测试域名系统工作是否正常. 语法: dig (选项) (参数) 选项: @<服务器地址>: 指定进行域名解析的域名服务器: -b: 当主机具有多个 ...
- 第三方br查询工具害人不浅
第三方br查询工具害人不浅,查询的时候会大批量调用百度的数据库,为什么说是大批量查询呢? 首先是自己查询,心急的站长恨不得下一次刷新br时数值会有所提高,不是那么急的也会一天查一次或几天一次,记录网站 ...
- 强大的数据库查询工具Database.NET 9.4.5018.42
原文:强大的数据库查询工具Database.NET 9.4.5018.42 强大的数据库查询工具Database.NET 9.4.5018.42 两个工具的下载地址,两个软件都是绿色免安装的,直接双击 ...
- 微信小程序+OLAMI(欧拉蜜)自然语言API接口制作智能查询工具--快递、聊天、日历等
微信小程序最近比较热门,再加上自然语义理解也越来越被人关注,于是我想赶赶潮流,做一个小程序试试.想来想去快递查询应该是一种比较普遍的需求. 如果你也在通过自然语言接口做点什么,希望我的这篇博客能帮到你 ...
- ElasticSearch 学习记录之ES查询添加排序字段和使用missing或existing字段查询
ES添加排序 在默认的情况下,ES 是根据文档的得分score来进行文档额排序的.但是自己可以根据自己的针对一些字段进行排序.就像下面的查询脚本一样.下面的这个查询是根据productid这个值进行排 ...
- Python 实现火车票查询工具
注意:由于 12306 的接口经常变化,课程内容可能很快过期,如果遇到接口问题,需要根据最新的接口对代码进行适当修改才可以完成实验. 一.实验简介 当你想查询一下火车票信息的时候,你还在上 12306 ...
- PHP mysql查询工具
PHP基于PDO的 mysql 查询工具 单页面实现,将页面放在任意目录即可. 访问用户 admin 密码 password 代码很简单,主要为了在没有phpMyAdmin时方便执行SQL. 效果如下 ...
随机推荐
- React的使用小规范----长期更新
用this.state控制组件显示,用this.props控制页面业务数据,用this.other保存其他需要的属性,如计时器setInterval的id
- ElementUI_NodeJS环境搭建
ElementUI简介 我们学习VUE,知道它的核心思想式组件和数据驱动,但是每一个组件都需要自己编写模板,样式,添加事件,数据等是非常麻烦的, 所以饿了吗推出了基于VUE2.0的组件库,它的名称叫做 ...
- OpenStack总体架构概览&OpenStack核心组件介绍
下面个是51CTO上一位朋友发布的O版OpenStack核心组件说明,总结的非常到位,所以我就不再造轮子了.~,~ https://down.51cto.com/data/2448945 私有云 公有 ...
- rsync 使用方法 ssh免密问题 不同端口同步
不同端口同步(前提还是做好免密) 主要通过选项-e "ssh -p 端口"来实现 重命名了秘钥文件 指定-i即可~ 1. 本地目录同步到导地不同端口主机目录 [root@bakse ...
- 推荐IOS Moneky测试工具Fast Monkey
推荐IOS Moneky测试工具Fast Monkey 1 介绍 非插桩 iOS Monkey, 支持控件,每秒4-5 action事件 2 下载 https://github.com/zhangzh ...
- Centos目录及其常用处理命令
1.Centos之常见目录作用介绍[1] 我们先切换到系统根目录 / 看看根目录下有哪些目录 [root@localhost ~]# cd / [root@localhost /]# ls bin ...
- 冰多多团队Gamma阶段项目展示
[冰多多]Gamma项目展示 冰多多项目: 语音coding助手 Gamma阶段目标: 推出一个更加完整的IDE,完善编辑器功能,优化UI 一. 团队成员的简介和个人博客地址 成员 角色 个人博客地址 ...
- AntDesign vue学习笔记(三)嵌套路由使用
本项目目前结构如下 1.Login页面=>MainFrm页面=>MainFrm左部菜单,右边是显示区域可以切换子页面. 2.当点击左部菜单时,右边的子页面随着进行切换. 实现关键代码如下1 ...
- 第三节:EF Core上下文DbContext相关配置和生命周期
一. 配置相关 1. 数据库连接字符串的写法 (1).账号密码:Server=localhost;Database=EFDB01;User ID=sa;Password=123456; (2).win ...
- 「UNR#1」奇怪的线段树
「UNR#1」奇怪的线段树 一道好题,感觉解法非常自然. 首先我们只需要考虑一次染色最下面被包含的那些区间,因为把无解判掉以后只要染了一个节点,它的祖先也一定被染了.然后发现一次染色最下面的那些区间一 ...