【技术博客】Pytorch代码生成
开发组在开发过程中,都不可避免地遇到了一些困难或问题,但都最终想出办法克服了。我们认为这样的经验是有必要记录下来的,因此就有了【技术博客】。
Pytorch代码生成经验文档
关于模型代码的生成,主要思路为从根节点开始进行广度优先搜索,从而自顶向下依次生成相关层的代码。这里和搜索相关的主要有三个数据结构:
- Q:队列,记录后续继续搜索的节点,即为后续的Node。
- graph:字典,记录整颗搜索树,每个key对应一个Node,Node为自己封装的一个类,里面包含每层的一些信息。记录搜索树的目的是为了后续的正确性验证,如下为Node的定义:
class Node:
def __init__(self, id = None, name = None, in_channels = 1, out_channels = 1, kernel_size = 3,
stride = 1, padding = 0, data = None, activity = None, pool_way = None, cat_dim = None):
self.fa = np.array([], dtype = str)
self.next = np.array([], dtype = str)
self.id = id
self.name = name
self.data = data
self.in_channels = in_channels
self.out_channels = out_channels
self.kernel_size = kernel_size
self.stride = stride
self.padding = padding
self.pool_way = pool_way
self.activity = activity
self.data_shape = np.array([], dtype = int)
self.cat_dim = cat_dim
def add_fa(self, f):
self.fa = np.append(self.fa, f)
def add_next(self, nx):
self.next = np.append(self.next, nx)
- done:字典,记录某节点相关代码是否已经生成,每个key对应一个boolean值。
同时还有以下需要关注的地方:
广度优先搜索。BFS为代码的主要框架。从’start’节点开始搜索,直到遍历结束,做一个线性的扫描。代码框架如下(省略了主要代码):
def make_graph(nets, nets_conn, init_func, forward_func):
#code here Q = queue.Queue()
Q.put(‘start’) #code here while not Q.empty():
cur_id = Q.get()
if GL.done[cur_id]:
continue '''''''''''' Main codes here '''''''''''' GL.done[cur_id] = True return init_func, forward_func
关于全局变量的处理。由于一开始忽略了python变量的特性(不需要声明),所以在一开始第一全局变量的时候是直接定义在文件开头的,但是这样存在的问题是:如果在局部函数中引用全局变量,则此时则是重新定义了一个变量而不是引用,用global关键字代码看上去又很臃肿。所以采取的办法是重新定义了一个GLOB模块,里面存放着需要的所有全局变量。类似于这样:
class GLOB:
def __init__(self):
self.graph = {}
self.done = {}
self.layer_used_time = {'view_layer': 0, 'linear_layer': 0, 'conv1d_layer': 0, 'conv2d_layer': 0, 'element_wise_add_layer':0, 'concatenate_layer':0}
self.nn_linear = 'torch.nn.Linear'
self.nn_conv1d = 'torch.nn.Conv1d'
self.nn_conv2d = 'torch.nn.Conv2d'
self.nn_view = '.view'
self.nn_sequential = 'torch.nn.Sequential'
self.start_layer = ['start']
self.norm_layer = ['conv1d_layer', 'conv2d_layer', 'view_layer', 'linaer_layer']
self.multi_layer = ['element_wise_add_layer', 'concatenate_layer']
self.layers_except_start = self.norm_layer + self.multi_layer这样,只需要在代码里初始化一个GLOB对象GL,这样在任何地方引用全局变量都不会造成困扰。
关于变量名生成。每层的输出数据的名字格式为:层名 + “data_出现的次数”。有一个数据结构”layer_used_time”(字典)专门负责记录每个层出现的次数,同时,会在该层的代码生成结构后更新layer_used_time和done的值。
关于何时初始化和更新graph。在我们的代码中,当从队列中取出一个节点后会执行一个函数:get_next_nodes_and_update_pre_nodes()。该函数的目的是获取和初始化当前节点的儿子节点,记录前端传入该层的其他参数,更新其父子节点,同时返回当前节点的所有祖先节点代码是否已经生成完毕。另外,在该函数内部也会做模型的一部分正确性验证,主要验证搭建的模型里除了拼接层和相加层以外的层是否存在多个父节点或没有节点。该函数实现的功能较多,后期会考虑重构。
关于正确性验证。考虑到用户在搭建模型时不一定能够保证参数的正确,所以我们对参数的合理性是“宽容”的,但是也有硬性的要求,比如只能有一个开始节点,同时除了拼接层和相加层可以有多个父节点以外,其他层有且仅有一个父节点。
关于生成的模型NET中forward函数的返回值。由于搭建的模型允许出现网状结构,所以不能保证模型的出口只有一个,所以现阶段生成的模型会返回所有出度为0的层的输出值,具体顺序参见代码。
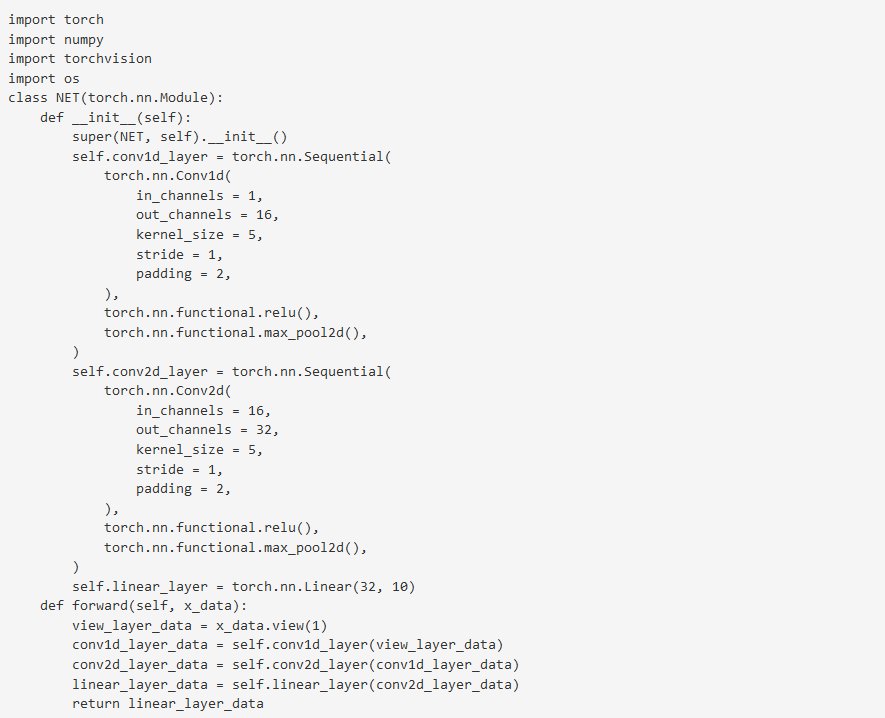
附最终生成的代码效果图(例):
【技术博客】Pytorch代码生成的更多相关文章
- 如何写出高质量的技术博客 这边文章出自http://www.jianshu.com/p/ae9ab21a5730 觉得不错直接拿过来了 好东西要大家分享嘛
如何写出高质量的技术博客?答案是:如果你想,就一定能写出高质量的技术博客.看起来很唯心,但这就是事实.有足够愿力去做一件目标明确,有良好反馈系统的事情往往很简单.就是不停地训练,慢慢地,你自己 ...
- ******IT公司面试题汇总+优秀技术博客汇总
滴滴面试题:滴滴打车数据库如何拆分 前端时间去滴滴面试,有一道题目是这样的,滴滴每天有100万的订单,如果让你去设计数据库,你会怎么去设计? 当时我的想法是根据用户id的最后一位对某个特殊的值取%操作 ...
- 转: BAT等研发团队的技术博客
BAT 技术团队博客 1. 美团技术团队博客: 地址: http://tech.meituan.com/ 2. 腾讯社交用户体验设计(ISUX) 地址:http://isux.tencent.c ...
- 解决Eclipse中文乱码 - 技术博客 - 51CTO技术博客 http://hsj69106.blog.51cto.com/1017401/595598/
解决Eclipse中文乱码 - 技术博客 - 51CTO技术博客 http://hsj69106.blog.51cto.com/1017401/595598/
- 欢迎访问我的最新个人技术博客http://zhangxuefei.top
博客园已停止更新,欢迎访问我的最新个人技术博客http://zhangxuefei.top
- 技术博客(初用markdown)。
技术博客 菜鸟教程在这个网站我学到许多有趣的东西,并且弥补了我之前的一些不足之处. 以下为我学习到的内容 输出不同的三位数 以下为代码和输出结果 *** #include<stdio.h> ...
- 技术博客(初用markdown)
技术博客 菜鸟教程在这个网站我学到许多有趣的东西,并且弥补了我之前的一些不足之处. 以下为我学习到的内容. 1 如果想输出多个多位数的时候,可以尝试用多个if语句.如果需要输出3为数的时候,设置三个变 ...
- 【转】【技术博客】Spark性能优化指南——高级篇
http://mp.weixin.qq.com/s?__biz=MjM5NjQ5MTI5OA==&mid=2651745207&idx=1&sn=3d70d59cede236e ...
- 作业一:创建个人技术博客、自我介绍、简单的C程序
年9月14日中午12点: 一.主要内容 建个人技术博客(博客园 www.cnblogs.com) 本学期将通过写博客的方式提交作业,实际上,最终的目的是希望同学们能通过博客的形式记录我们整个学习过程 ...
随机推荐
- SSM之Mybatis整合及使用
SSM 在ss基础上加进行整合Mybatis(applicationContext.xml中添加配置),并添加分页拦截器(添加mybatis分页拦截器),并用generator动态生成到层. 构建基础 ...
- IntelliJ IDEA重命名变量的问题
当我尝试使用Shift+ F6或简单地使用Refactor => Rename重命名变量时,有时intellij不仅重命名我想要的那个,而且还重命名具有相同名称的所有其他变量(在其他文件中)以及 ...
- vue中自定义指令
//vue中自定义指令 //使用 Vue.directive(id, [definition]) 定义全局的指令 //参数1:指令的名称.注意,在定义的时候,指令的名称前面,不需要加 v-前缀; 但是 ...
- js new Date()不带时分秒时,时间变了 问题解决
//先把电脑系统时间的 时区 调到别的时间一下如 夏威夷 UTC-10:00//在浏览器的Console里运行如下代码,getMonth是从0开始的,所以要+1 var d=new Date(&quo ...
- Spring容器的refresh()介绍
Spring容器的refresh()[创建刷新]; 1.prepareRefresh()刷新前的预处理; 1).initPropertySources()初始化一些属性设置;子类自定义个性化的属性设置 ...
- Flask的上下文管理
flask上下文管理 1.运用的知识点 val = threading.local() def task(arg): #threading.local() val.xxx=123 #内部,获取当前线程 ...
- Mincut 最小割 (BZOJ1797+最小割+tarjan)
题目链接 传送门 思路 根据题目给定的边跑一边最大流,然后再在残留网络上跑\(tarjan\). 对于每一条边有: 如果它是非满边,那么它一定不是最小割集里面的边: 如果\(c[u[i]] \not= ...
- python测试开发django-66.图片403forbidden
前言 用 django 开发 web 页面,在 HTML 页面上添加图片时,发现本地图片可以正常显示,但是添加一个互联网的图片,却不能正常显示. 本地 static 图片 先在本地 static 放一 ...
- Object类.时间日期类.System类.Stringbuilder类.包装类
Object类 java.lang.Object类是java语言中的根类,即所有类的父类.它中描述的所有方法都可以使用.在对象实例化的时候,最终找的父类就是Object. 如果一个类没有特别指定父类, ...
- woocommerce调用产品相册gallery图片如何操作?wordpress技巧
wordpress官网有很多woocommerce模板,但有些客户要求定制模板,这时可能会碰到产品相册图片调用的问题,如果根据自带的Storefront主题来改很麻烦,那我们就自己定义吧!下来就随yt ...