python解析本地HTML文件
Python使用爬虫技术时,每运行一次,本地都会访问一次主机。为避免完成程序前调试时多次访问主机增加主机负荷,我们可以在编写程序前将网页源代码存在本地,调试时访问本地文件即可。现在我来分享一下爬取资料的调试过程。
一、将网页源代码存在本地
1、打开需要爬取的网页,鼠标右键查看源代码
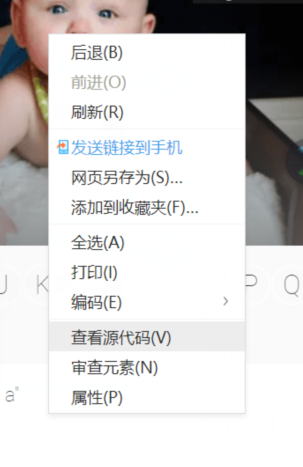
2、复制源代码,将代码保存至本地项目文件目录下,文件后缀改为.html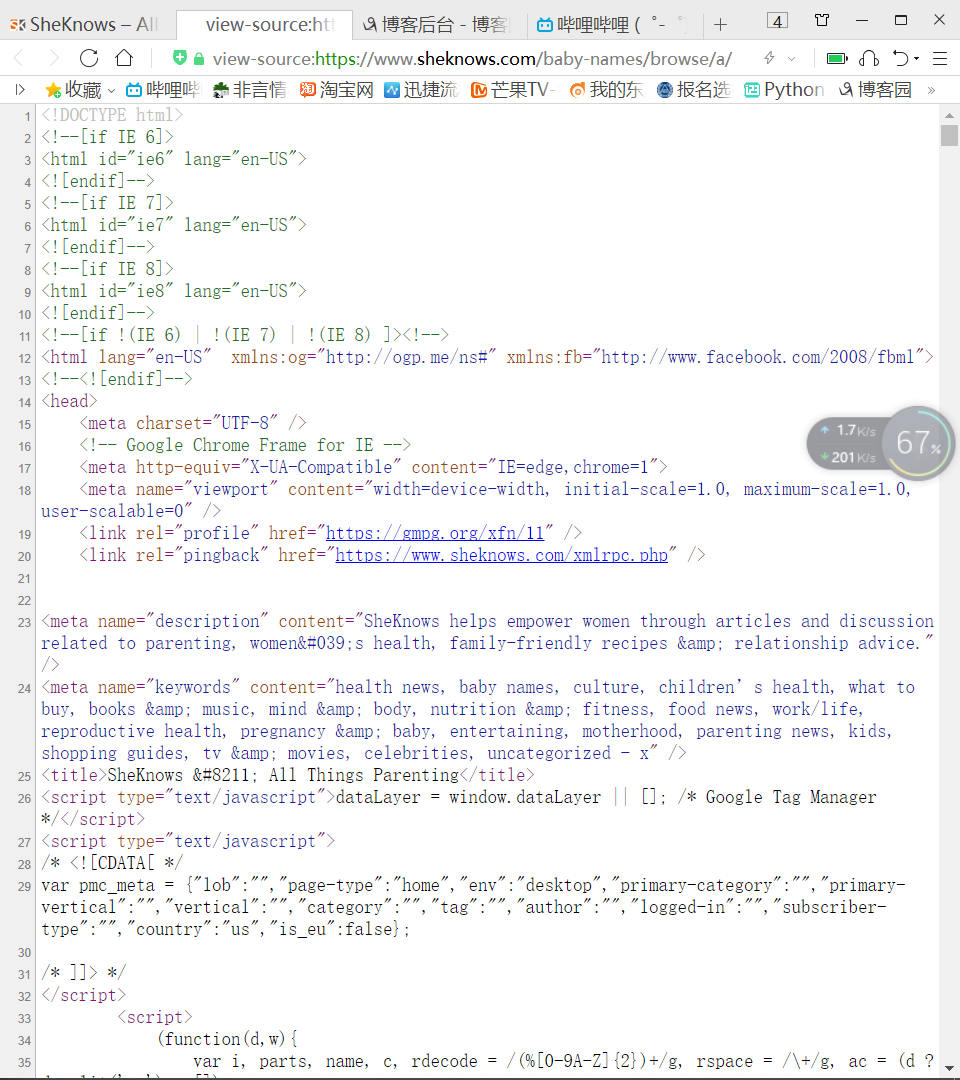

二、在Python中打开本地html文件
打开并读取本地文件可使用BeautifulSoup方法直接打开
soup=BeautifulSoup(open('ss.html',encoding='utf-8'),features='html.parser') #features值可为lxml
解析后可以直接使用soup,与请求网页解析后的使用方法一致
三、使用本地文件爬取资料
1、先爬取主页的列表资料,其中同义内容使用“@”符号连接
def draw_base_list(doc):
lilist=soup.find('div',{'class':'babynames-term-articles'}).findAll('article');
#爬取一级参数
for x in lilist:
str1=''
count=0
a='@'
EnName=x.find('a').text;
Mean=x.find('div',{'class':'meaning'}).text;
Sou=x.find('div',{'class','related'}).findAll('a')
Link=x.find('a').get('href');
for x in Sou:
if count!=0:#添加计数器判断是否为第一个,不是则添加@
str1=str1+a
s=str(x) #将x转换为str类型来添加内容
str1=str1+s
count+=1
Source=str1
print(Source);
print(Meaning);
运行后发现Source和Meaning中包含了标签中的内容,我们使用正则表达式re.sub()方法删除str中指定内容。查看源代码可以发现标签内容只有一个链接,可以获取标签内的链接后再指定删除。
首先在for循环内给定一个值获取标签内的链接link=x.get('href'),接着使用sub方法指定删除link。代码如下:
link=x.get('href')
change2=re.sub(link,'',s)
运行后我们发现str中还存在标签名,在for循环中指定多余内容删除:
link=x.get('href')
s=str(x)
change1=re.sub('<a href="','',s)
change2=re.sub(link,'',change1)
change3=re.sub('">','',change2)
change4=re.sub(' Baby Names','',change3)
change5=re.sub('</a>','',change4)
change=re.sub(' ','',change5)
最后就能得到想要的信息。
2、再爬取详细信息
通过def draw_base_list(doc)函数向二级详情函数传递Link参数爬取详细信息,为避免频繁访问主机,我们同样将详情页的源代码保存至本地并解析。
def draw_detail_list():
str1=‘’
meta="boy"
doc=BeautifulSoup(open('nn.html',encoding='utf-8'),features='html.parser')
Des=doc.find('div',{'class':'single-babyname-wrapper'}).findAll('p')
Gen=doc.find('div',{'class':'entry-meta'}).find('a')
#print(Gen)
g=str(Gen)
for i in Gen:
if meta in g:
Gender="boy"
else:
Gender="girl"
#print(Gender)
for x in Des:
#print(x)
if x.find('a')==None: #该标签下有我们不需要的信息,查看源代码找到信息之间的联系,发现不需要的信息中都有链接
c=str(x)
change1=re.sub('<p>','',c) #与一级信息函数一样删除指定内容
change2=re.sub('</p>','',change1)
change3=re.sub('\t','',change2)
change=re.sub('\n','@',change3)
str1=str1+change
#Description=x.text
#print(Description)
Description=str1
#print(Description)
data={ #将数据存进字典中方便将数据保存至csv文件或数据库中
'EnName':EnName,
'CnName':'',
'Gender':Gender,
'Meaning':Meaning,
'Description':Description,
'Source':Source,
'Character':'', #网页中没有的信息数据列为空
'Celebrity':'',
'WishTag':''
}
#print(data)
3、将爬取下来的数据存入csv文件中
def draw_base_list(doc):
......
#爬取一级参数
for x in lilist:
......
for x in Sou:
......
......
draw_detail_list(Link,EnName,Meaning,Source) #将数据传给二级信息函数 def draw_detail_list(url,EnName,Meaning,Source):
......
for i in Gen:
...... for x in Des:
...... data={
......
}
write_dictionary_to_csv(data,'Names') #将字典传给存放数据函数,并给定csv文件名 def write_dictionary_to_csv(dict,filename):
file_name='{}.csv'.format(filename)
with open(file_name, 'a',encoding='utf-8') as f:
file_exists = os.path.isfile(filename)
w =csv.DictWriter(f, dict.keys(),delimiter=',', quotechar='"', lineterminator='\n',quoting=csv.QUOTE_ALL, skipinitialspace=True)
w.writerow(dict)
打开文件后发现没有文件头,为避免重复写入文件头,判断文件是否为空,若为空则写入文件头:
#防止每次循环重复写入列头
if os.path.getsize(file_name)==0 : #通过文件大小判断文件是否为空,为0说明是空文件
w.writeheader()
再次运行后文件头正常写入文件中。
4、访问主机,完成信息爬取
确定代码正确没有错误后就可以将打开本地文件的代码改成访问网页,最后完成数据的爬取。
python解析本地HTML文件的更多相关文章
- Python3+Requests-HTML+Requests-File解析本地html文件
一.说明 解析html文件我喜欢用xpath不喜欢用BeautifulSoup,Requests的作者出了Requests-HTML后一般都用Requests-HTML. 但是Requests-HTM ...
- 开发一个简单的chrome插件-解析本地markdown文件
准备软件环境 1. 软件环境 首先,需要使用到的软件和工具环境如下: 一个最新的chrome浏览器 编辑器vscode 2. 使用的js库 代码高亮库:prismjs https://prismjs. ...
- python基础——python解析yaml类型文件
一.yaml介绍 yaml全称Yet Another Markup Language(另一种标记语言).采用yaml作为配置文件,文件看起来直观.简洁.方便理解.yaml文件可以解析字典.列表和一些基 ...
- Python 读取本地*.txt文件 替换 内容 并保存
# r 以只读的方式打开文件,文件的描述符放在文件的开头# w 打开一个文件只用于写入,如果该文件已经存在会覆盖,如果不存在则创建新文件 #路径path = r"D:\pytho ...
- js 解析本地Excel文件!
通常,一般读取Excel都是由后台来处理,不过如果需求要前台来处理,也是可以的.. 1.需要用到js-xlsx,下载地址:js-xlsx 2.demo: <!DOCTYPE html>&l ...
- 如何解析本地和线上XML文件获取相应的内容
一.使用Dom解析本地XML 1.本地XML文件为:test.xml <?xml version="1.0" encoding="UTF-8"?> ...
- 用Python删除本地目录下某一时间点之前创建的所有文件
因为工作原因,需要定期清理某个文件夹下面创建时间超过1年的所有文件,所以今天集中学习了一下Python对于本地文件及文件夹的操作.网上 这篇文章 简明扼要地整理出最常见的os方法,抄袭如下: os.l ...
- python打开一个本地目录文件路径
os.path.abspath()os 模块为 python 语言标准库中的 os 模块包含普遍的操作系统功能.主要用于操作本地目录文件.path.abspath()方法用于获取当前路径下的文件. 比 ...
- Python解析HDF文件 分类: Python 2015-06-25 00:16 743人阅读 评论(0) 收藏
前段时间因为一个业务的需求需要解析一个HDF格式的文件.在这之前也不知道到底什么是HDF文件.百度百科的解释如下: HDF是用于存储和分发科学数据的一种自我描述.多对象文件格式.HDF是由美国国家超级 ...
随机推荐
- Openwrt路由器上安装python
在路由器安装python之前,还是经过了一番折腾的.淘宝上买了个已经刷好系统的小米迷你路由器,但里面安装的不是预期的Pandorbox,而是LEDE. 这个固件已经带了大量自带的软件,128的内存实在 ...
- 案例:3D切割轮播图
一.3d转换 3D旋转套路:顺着轴的正方向看,顺时针旋转是负角度,逆时针旋转是正角度 二.代码 <!DOCTYPE html> <html lang="en"&g ...
- codevs:1313 质因数分解:已知正整数 n是两个不同的质数的乘积,试求出较大的那个质数 。
#include<iostream>#include<cstdio>#include<cmath>using namespace std;int a[2];int ...
- P4555 【[国家集训队]最长双回文串】
不知道有没有人跟我一样数据结构学傻了 首先这道题是要求回文串,那么我们可以想到manacher算法 但由于\(manacher\)不能求出双回文子串,我们要考虑一些性质 首先对于一个回文串,删掉两边的 ...
- 最长公共子序列 DP
class Solution: def LCS(self,A,B): if not A or not B: #边界处理 return 0 dp = [[0 for _ in range(len(B)+ ...
- node.js Error: connect EMFILE 或者 getaddrinfo ENOTFOUND
Error: getaddrinfo ENOTFOUND] code: 'ENOTFOUND', errno: 'ENOTFOUND', syscall: 'getaddrinfo' Error: c ...
- mapper.xml等资源导入的问题
在pom.xml中的下导入如下字段 <resources> <resource> <directory>src/main/java</directory> ...
- 在Mac如何启动MySQL
安装好MySQL服务后(安装步骤可以参考系列经验1).打开“系统偏好设置”,单击下端的“MySQL”图标. 2 在“MySQL”对话框中,单击“启动MySQL服务”按钮. 3 在弹出的窗口中,输入管理 ...
- docker理论 Cgroup namespace 各种隔离
耦合 是指两个或两个以上的体系或者两种运动形式间通过相互作用而批次影响以至联合起来的现象. Nginx与apache 在同一台服务器运行都占用80端口,起冲突这是我们修改其中一个端口为8080 半解耦 ...
- 批量转换word为pdf
自己写的一个小工具,用于批量转换word为pdf,使用方式: 将完整代码拷贝到文档中,并修改名称为words2pdfs.py将该文件拷贝到需要转换的文档目录下在终端中输入python words2pd ...