python解析本地HTML文件
Python使用爬虫技术时,每运行一次,本地都会访问一次主机。为避免完成程序前调试时多次访问主机增加主机负荷,我们可以在编写程序前将网页源代码存在本地,调试时访问本地文件即可。现在我来分享一下爬取资料的调试过程。
一、将网页源代码存在本地
1、打开需要爬取的网页,鼠标右键查看源代码
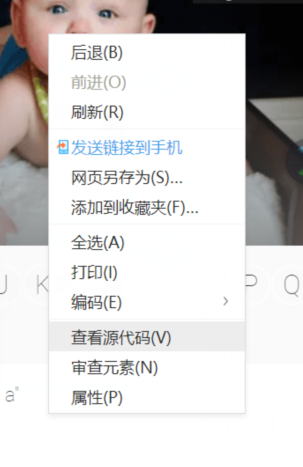
2、复制源代码,将代码保存至本地项目文件目录下,文件后缀改为.html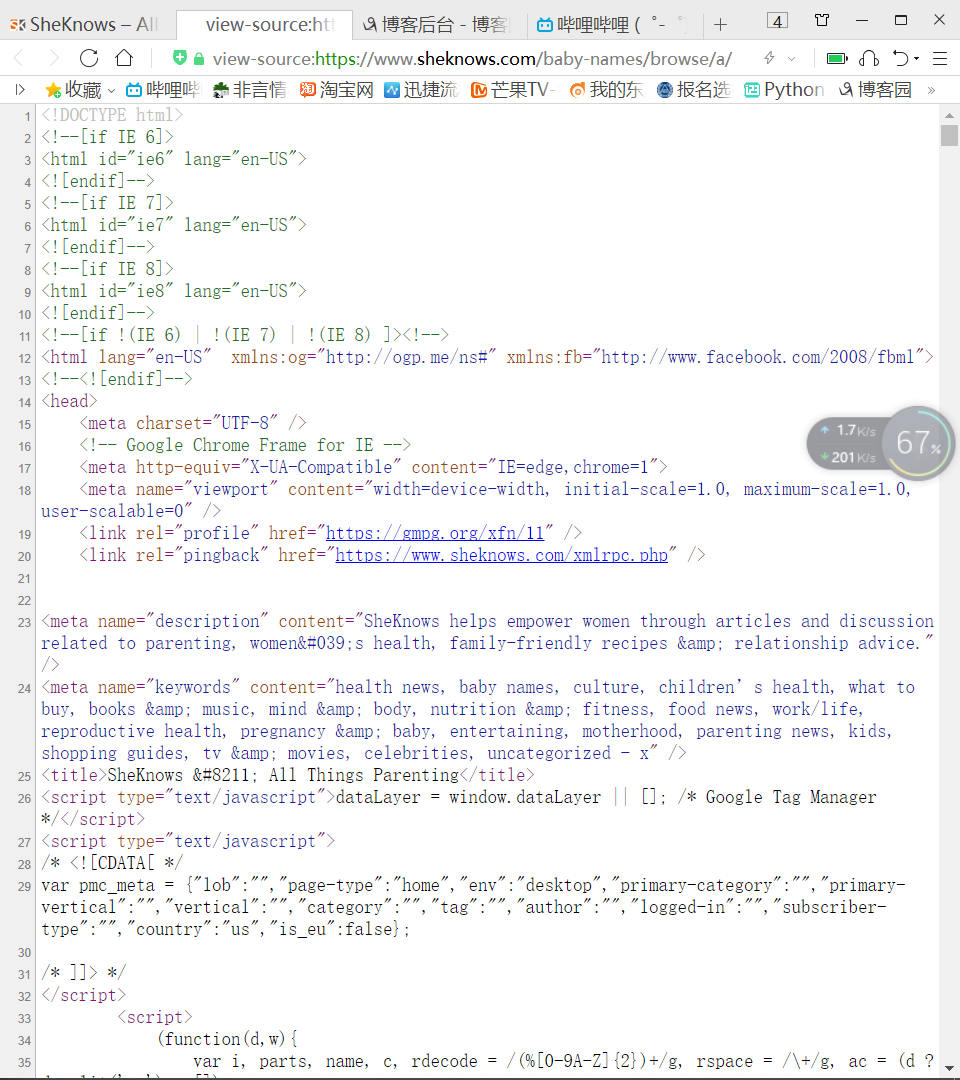

二、在Python中打开本地html文件
打开并读取本地文件可使用BeautifulSoup方法直接打开
soup=BeautifulSoup(open('ss.html',encoding='utf-8'),features='html.parser') #features值可为lxml
解析后可以直接使用soup,与请求网页解析后的使用方法一致
三、使用本地文件爬取资料
1、先爬取主页的列表资料,其中同义内容使用“@”符号连接
def draw_base_list(doc):
lilist=soup.find('div',{'class':'babynames-term-articles'}).findAll('article');
#爬取一级参数
for x in lilist:
str1=''
count=0
a='@'
EnName=x.find('a').text;
Mean=x.find('div',{'class':'meaning'}).text;
Sou=x.find('div',{'class','related'}).findAll('a')
Link=x.find('a').get('href');
for x in Sou:
if count!=0:#添加计数器判断是否为第一个,不是则添加@
str1=str1+a
s=str(x) #将x转换为str类型来添加内容
str1=str1+s
count+=1
Source=str1
print(Source);
print(Meaning);
运行后发现Source和Meaning中包含了标签中的内容,我们使用正则表达式re.sub()方法删除str中指定内容。查看源代码可以发现标签内容只有一个链接,可以获取标签内的链接后再指定删除。
首先在for循环内给定一个值获取标签内的链接link=x.get('href'),接着使用sub方法指定删除link。代码如下:
link=x.get('href')
change2=re.sub(link,'',s)
运行后我们发现str中还存在标签名,在for循环中指定多余内容删除:
link=x.get('href')
s=str(x)
change1=re.sub('<a href="','',s)
change2=re.sub(link,'',change1)
change3=re.sub('">','',change2)
change4=re.sub(' Baby Names','',change3)
change5=re.sub('</a>','',change4)
change=re.sub(' ','',change5)
最后就能得到想要的信息。
2、再爬取详细信息
通过def draw_base_list(doc)函数向二级详情函数传递Link参数爬取详细信息,为避免频繁访问主机,我们同样将详情页的源代码保存至本地并解析。
def draw_detail_list():
str1=‘’
meta="boy"
doc=BeautifulSoup(open('nn.html',encoding='utf-8'),features='html.parser')
Des=doc.find('div',{'class':'single-babyname-wrapper'}).findAll('p')
Gen=doc.find('div',{'class':'entry-meta'}).find('a')
#print(Gen)
g=str(Gen)
for i in Gen:
if meta in g:
Gender="boy"
else:
Gender="girl"
#print(Gender)
for x in Des:
#print(x)
if x.find('a')==None: #该标签下有我们不需要的信息,查看源代码找到信息之间的联系,发现不需要的信息中都有链接
c=str(x)
change1=re.sub('<p>','',c) #与一级信息函数一样删除指定内容
change2=re.sub('</p>','',change1)
change3=re.sub('\t','',change2)
change=re.sub('\n','@',change3)
str1=str1+change
#Description=x.text
#print(Description)
Description=str1
#print(Description)
data={ #将数据存进字典中方便将数据保存至csv文件或数据库中
'EnName':EnName,
'CnName':'',
'Gender':Gender,
'Meaning':Meaning,
'Description':Description,
'Source':Source,
'Character':'', #网页中没有的信息数据列为空
'Celebrity':'',
'WishTag':''
}
#print(data)
3、将爬取下来的数据存入csv文件中
def draw_base_list(doc):
......
#爬取一级参数
for x in lilist:
......
for x in Sou:
......
......
draw_detail_list(Link,EnName,Meaning,Source) #将数据传给二级信息函数 def draw_detail_list(url,EnName,Meaning,Source):
......
for i in Gen:
...... for x in Des:
...... data={
......
}
write_dictionary_to_csv(data,'Names') #将字典传给存放数据函数,并给定csv文件名 def write_dictionary_to_csv(dict,filename):
file_name='{}.csv'.format(filename)
with open(file_name, 'a',encoding='utf-8') as f:
file_exists = os.path.isfile(filename)
w =csv.DictWriter(f, dict.keys(),delimiter=',', quotechar='"', lineterminator='\n',quoting=csv.QUOTE_ALL, skipinitialspace=True)
w.writerow(dict)
打开文件后发现没有文件头,为避免重复写入文件头,判断文件是否为空,若为空则写入文件头:
#防止每次循环重复写入列头
if os.path.getsize(file_name)==0 : #通过文件大小判断文件是否为空,为0说明是空文件
w.writeheader()
再次运行后文件头正常写入文件中。
4、访问主机,完成信息爬取
确定代码正确没有错误后就可以将打开本地文件的代码改成访问网页,最后完成数据的爬取。
python解析本地HTML文件的更多相关文章
- Python3+Requests-HTML+Requests-File解析本地html文件
一.说明 解析html文件我喜欢用xpath不喜欢用BeautifulSoup,Requests的作者出了Requests-HTML后一般都用Requests-HTML. 但是Requests-HTM ...
- 开发一个简单的chrome插件-解析本地markdown文件
准备软件环境 1. 软件环境 首先,需要使用到的软件和工具环境如下: 一个最新的chrome浏览器 编辑器vscode 2. 使用的js库 代码高亮库:prismjs https://prismjs. ...
- python基础——python解析yaml类型文件
一.yaml介绍 yaml全称Yet Another Markup Language(另一种标记语言).采用yaml作为配置文件,文件看起来直观.简洁.方便理解.yaml文件可以解析字典.列表和一些基 ...
- Python 读取本地*.txt文件 替换 内容 并保存
# r 以只读的方式打开文件,文件的描述符放在文件的开头# w 打开一个文件只用于写入,如果该文件已经存在会覆盖,如果不存在则创建新文件 #路径path = r"D:\pytho ...
- js 解析本地Excel文件!
通常,一般读取Excel都是由后台来处理,不过如果需求要前台来处理,也是可以的.. 1.需要用到js-xlsx,下载地址:js-xlsx 2.demo: <!DOCTYPE html>&l ...
- 如何解析本地和线上XML文件获取相应的内容
一.使用Dom解析本地XML 1.本地XML文件为:test.xml <?xml version="1.0" encoding="UTF-8"?> ...
- 用Python删除本地目录下某一时间点之前创建的所有文件
因为工作原因,需要定期清理某个文件夹下面创建时间超过1年的所有文件,所以今天集中学习了一下Python对于本地文件及文件夹的操作.网上 这篇文章 简明扼要地整理出最常见的os方法,抄袭如下: os.l ...
- python打开一个本地目录文件路径
os.path.abspath()os 模块为 python 语言标准库中的 os 模块包含普遍的操作系统功能.主要用于操作本地目录文件.path.abspath()方法用于获取当前路径下的文件. 比 ...
- Python解析HDF文件 分类: Python 2015-06-25 00:16 743人阅读 评论(0) 收藏
前段时间因为一个业务的需求需要解析一个HDF格式的文件.在这之前也不知道到底什么是HDF文件.百度百科的解释如下: HDF是用于存储和分发科学数据的一种自我描述.多对象文件格式.HDF是由美国国家超级 ...
随机推荐
- asp.net实现大文件上传分片上传断点续传
HTML部分 <%@ Page Language="C#" AutoEventWireup="true" CodeBehind="index.a ...
- C# 中文序列按笔画排序
问题:给定一串含中文的序列,按首字符的笔画数排序 因为默认是按拼音来排序的, 借助Globalization命名空间,包含定义区域性相关信息的类,这些信息包括语言,国家/地区,正在使用的日历,日期.货 ...
- 代码格式化工具---indent工具
indent工具,可以把代码格式化成某种风格. 通过命令:rpm -qa | grep indent 查看是否安装了indent工具. 若没有,可使用命令sudo apt-get install ...
- Kafka 幂等生产者和事务生产者特性(讨论基于 kafka-python | confluent-kafka 客户端)
Kafka 提供了一个消息交付可靠性保障以及精确处理一次语义的实现.通常来说消息队列都提供多种消息语义保证 最多一次 (at most once): 消息可能会丢失,但绝不会被重复发送. 至少一次 ( ...
- linux protobuf 测试官方例子遇到报错及解决办法。
测试例子时出现报错如下,在最下面会写出安装流程. -------------------------------------报错----1------------------------------- ...
- 微信小程序 图片设置为圆形
要图片圆形显示,需要设置border-radius:50%,还要设置overflow:hidden,具体如下: Tip:user-avatar是图片控件的class .user-avatar { wi ...
- Chrome远程调试之WebSocket
var ws = new WebSocket('ws://localhost:9222/devtools/page/3c5c05fa-80b7-4cfe-8d1d-ebe79a7a5730');ws. ...
- arts打卡13周
算法: 报数序列是一个整数序列,按照其中的整数的顺序进行报数,得到下一个数.其前五项如下: 1. 12. 113. 214. 12115. 1112211 被读作 "one 1" ...
- 2019软工实践_Alpha(1/6)
队名:955 组长博客:https://www.cnblogs.com/cclong/p/11841141.html 作业博客:https://edu.cnblogs.com/campus/fzu/S ...
- Linux crontab 定时任务使用
1.介绍 crond是linux下用来周期性的执行某种任务或等待处理某些事件的一个守护进程: 与windows下的计划任务类似,当安装完成操作系统后,默认会安装此服务工具,并且会自动启动crond进程 ...