H.264学习笔记5——熵编码之CAVLC
H.264中,4x4的像素块经过变换和量化之后,低频信号集中在左上角,大量高频信号集中在右下角。左边的低频信号相对数值较大,而右下角的大量高频信号都被量化成0、1和-1;变换量化后的残差信息有一定的统计特性和规律。
CAVLC(Context-based Adaptive Variable-Length Code):基于上下文的可变长度编码,是H.264中进行4x4像素块进行熵编码的方法,基本(baseline)档次中只能使用CAVLC,只有主要档次和扩展档次才能使用CABAC(见笔记:熵编码之CABAC)。
一、对于经过Zigzag扫描(Z扫描)后的4x4像素残差,编码过程包括:
A、非零系数数目(TotalCoeffs)和拖尾系数数目(TrailingOnes)的编码:
拖尾系数:就是指Z扫描后,末尾高频信号中出现连续1或-1的个数(中间可以隔任意多个0),拖尾系数最多有5个。当连续1或-1的个数超过3个,只有最后3个1或-1是拖尾系数,其他的当作普通的非零系数。
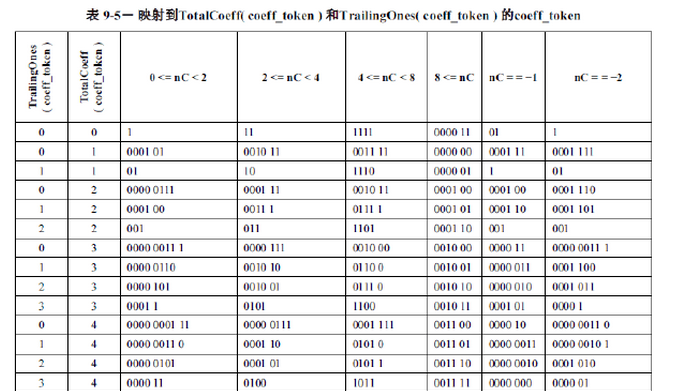
TotalCoeffs和TrailingOnes通过查表方式进行编码,H.264针对TotalCoeffs和TrailingOnes,提供了4张变长表和1张定长表(部分见附表9-5)。编码表的选择是由NC确定的,NC的值是由上下文信息确定的。对于色度直流信号,NC=-1;对于其他的NC,根据当前块左边4x4块和上面4x4块的非零系数的个数A和B决定。如表一:其中X表示该块与当前块属于同一slice且可用。根据NC选择编码表的策略如表二:
| A(左边块) | B(上面块) | NC |
| X | X | (A+B)/2 |
| X | — | A |
| — | X | B |
| — | — | 0 |
| NC | 编码表编号 |
| 0,1 | 变长表1 |
| 2,3 | 变长表2 |
| 4,5,6,7 | 变长表3 |
| >=8 | 定长表 |
| -1 | 变长表4 |
通过NC确定所选择的表之后,将编码的二进制输出。
B、每一个拖尾系数的符号正负性编码(按照Z扫面结果的逆序编码):
按照逆序对每一个拖尾系数的符号进行编码,用0表示1(正)、1表示-1(负),将编码结果输出
C、除拖尾系数外的每一个非零系数幅值(Level,包含正负号信息)编码(按照Z扫描结果的逆序编码):
拖尾系数幅值的编码包括前缀Level_prefix和后缀Level_suffix。另外编码过程中suffixLength基于上下文信息,根据Level_suffix和Level实时更新。具体过程如下:
1、设置初始SuffixLength:
当TotalCoeffs>10且TrailingOnes<=1时,SuffixLength设为1;否则设为0;
2、将有符号的Level转换成无符号的LevelCode:
若Level > 0:LevelCode = (Level << 1)-2;
若Level < 0:LevelCode = -(Level << 1) - 1;
这样解码时,就可以根据LevelCode的奇偶性判断Level的正负性,从在根据LevelCode解码出有符号的Level。
3、计算Level_prefix 和 Level_suffix:
Level_prefix = LevelCode / (1 << SuffixLength);
Level_suffix = LevelCode% (1 << SuffixLength);
4、编码Level_prefix和Level_suffix:
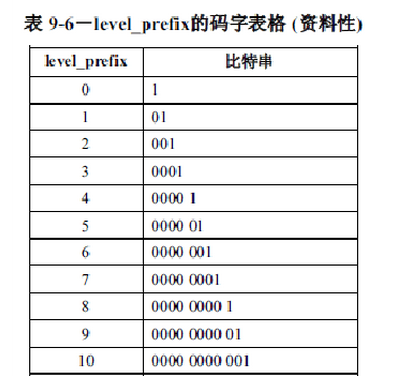
编码Level_prefix是通过查标准表9-6(部分见附表9-6),编码得到的是前缀码,所以解码时可以即使、唯一译码。Level_suffix的编码就是Level_suffix的二进制无符号形式。然后将Level_prefix和Level_suffix的编码结果依次输出,但当SuffixLength=0时,没有Level_suffix,不需要输出。
5、更新SuffixLength的值,回到步骤2继续编码下一个非零系数。更新过程可以用下面代码表示:
if(SuffixLength == )
SuffixLength++;
else if (abs(Level) > ( << (SuffixLength -)) && SuffixLength < )
SuffixLength++;
即:当SuffixLength为0时,SuffixLength加1;当SuffixLength达到6之后不再更新SuffixLength;当SuffixLength在1和6之间,如果当前已编码的非零系数的绝对值(abs(Level))大于给定的阈值S,那么SuffixLength增1,其中阈值S的大小为:S = 3 * 2 ^ (SuffixLength-1) = 3<<(SuffixLength-1)。
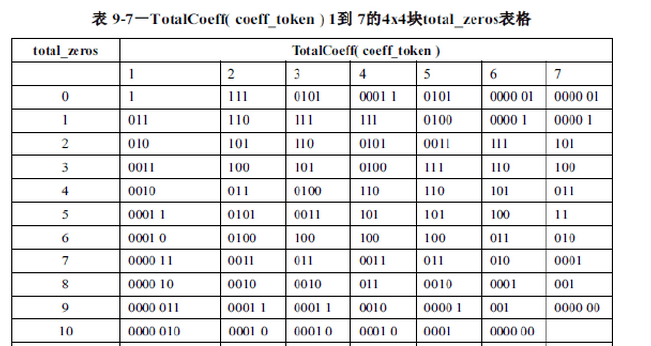
D、最后一个非零系数前0的数目(TotalZeros)编码:查找标准表9-7(部分见附表9-7)~9-9
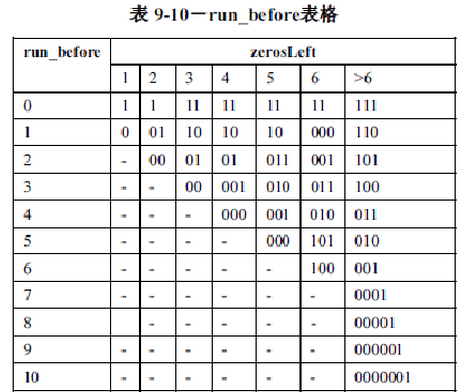
E、每一个非零系数前连续0的数目(RunBefore)编码(按照Z扫面结果的逆序编码):查找标准表9-10(部分见附表9-10)
编码过程中,ZerosLeft表示当前编码非零系数左边所有0的个数,对于最后一个(逆序的最后一个)非零系数前0的个数不需要编码。
二、例如:对于4x4的残差块,如下图:
| 0 | 3 | -1 | 0 |
| 0 | -1 | 1 | 0 |
| 1 | 0 | 0 | 0 |
| 0 | 0 | 0 | 0 |
经过Z扫描得到序列:0,3,0,1,-1,-1,0,1,0,0,0,0,0,0,0,0。
对该序列进行编码如下:
1、初始值设定:
TotalCoeffs = 5;TrailingOnes = 3;TotalZeros = 3;假设 NC = 1;SuffixLength = 0;最终编码输出码流为out。
2、编码TotalCoeffs和TrailingOnes:
查附表9-5得,TotalCoeffs = 5、TrailingOnes = 3和0 <= NC <2时;编码结果为:0000 100。
此时out = 0000 100。
3、编码拖尾系数符号:
拖尾系数为1,-1,-1(扫描逆序),对应的符号编码为0,1,1。所以此时out = 0000 1000 11。
4、编码每个非拖尾非零系数的幅值Level:
需要编码的非零系数有1,3(Z扫描逆序),初始i=2,过程如下:
Level[i--] = 1; 得到LevelCode = 0,Level_prefix = 0,没有Level_suffix(因为SuffixLength=0),查表9-6得编码结果为1。此时out = 0000 1000 111。
然后更新SuffixLength,SuffixLength++得SuffixLength=1;
Level[i--] = 3;得到LevelCode=4,Level_prefix = 2,Level_suffix = 0,查表9-6得Level_prefix编码结果为001,然后Level_suffix的二进制表示为0。
out = 0000 1000 1110 010。此时i=0,此步骤编码结束。
5、编码TotalZeros:查表9-7得编码结果为编码结果为111,此时out = 0000 1000 1110 0101 11。
6、编码每一个非零系数前的连续o的数目:有四个非零系数前连续0的个数要编码,初始i=5。查表9-10的编码过程如下:
ZerosLeft = 3, RunBefore = 1,Level[i--]=1,编码结果为10;
ZerosLeft = 2, RunBefore = 0,Level[i--]=-1,编码结果为1;
ZerosLeft = 2, RunBefore = 0,Level[i--]=-1,编码结果为1;
ZerosLeft = 2, RunBefore = 1,Level[i--]=1,编码结果为01;
ZerosLeft = 1, RunBefore = 1,Level[i--]=3,此时对应第一个非零系数,不需要编码;
最后输出结果为 out = 0000 1000 1110 0101 1110 1101。
相应解码如下:读入out = 0000 1000 1110 0101 1110 1101
1、解码TotalCoeffs和TrailingOnes:
初始NC=1,根据表9-5,可以从0000100中解码得到TotalCoeffs=5;TrailingOnes=3。这里因为表9-5的编码可以及时、唯一译码,所以遇到的第一个合法的01串就是TotalCoeffs和TrailingOnes编码的结果。
2、解码拖尾系数:此时out = 0 1110 0101 1110 1101
由TrailingOnes=3知,有3个拖尾系数,所以对应的正负号编码为011,所以3个拖尾系数是1,-1,-1。所以解码输出 in是 -1,-1,1(因为编码是逆序的)。
3、解码除拖尾系数外的非零系数:此时out = 10 0101 1110 1101
由TotalCoeffs=5;TrailingOnes=3知除拖尾系数外,还有两个非零系数。初始SuffixLength=0,所以根据表9-6(及时、唯一译码)解码如下:
SuffixLength=0 查表得比特串为1,level_prefix=0,LevelCode=0(偶数),Level=1,没有Level_suffix;(消耗码流0)
SuffixLength=1 查表得比特串为001,level_prefix=2,LevelCode=4(偶数),Level=3,Level_suffix=0;(消耗码流0010)
所以输出 in是 3,1,-1,-1,1
4、解码每个非零系数前0的个数:此时out = 1 1110 1101
TotalCoeffs = 5;根据表9-7解码得 TotalZeros=3,对应码流:111。
然后查表9-10,得到每一个非零系数前连续0的个数,过程如下:此时out = 10 1101
TotalZeros=3,根据码流查表得10对应 RunBefore=1,in是 3,1,-1,-1,0,1
TotalZeros=3-1=2,根据码流查表得1对应 RunBefore=0,in是 3,1,-1,-1,0,1
TotalZeros=2-0=2,根据码流查表得1对应 RunBefore=0,in是 3,1,-1,-1,0,1
TotalZeros=2-0=2,根据码流查表得01对应 RunBefore=1,in是 3,0,1,-1,-1,0,1
TotalZeros=2-1=1,out码流解码完,所以TotalZeros=1表示3之前的0数目,in是 0,3,1,-1,-1,0,1
然后在结尾补0组成16个残差系数,得解码结果0,3,1,-1,-1,0,1,0,0,0,0,0,0,0,0,0
三、附表:
H.264学习笔记5——熵编码之CAVLC的更多相关文章
- H.264学习笔记1——相关概念
此处记录学习AVC过程中的一些基本概念,不定时更新. frame:帧,相当于一幅图像,包含一个亮度矩阵和两个色度矩阵. field:场,一帧图像,通过隔行扫描得到奇偶两场,分别称为顶场和底场或奇场和偶 ...
- H.264学习笔记之一(层次结构,NAL,SPS)
一 H.264句法 1.1元素分层结构 H.264编码器输出的Bit流中,每个Bit都隶属于某个句法元素.句法元素被组织成有层次的结构,分别描述各个层次的信息. 图1 H.264分层结构由五层组成,分 ...
- H.264学习笔记
1.帧和场的概念 视频的一场或一帧可用来产生一个编码图像.通常,视频帧可以分成两种类型:连续或隔行视频帧.我们平常看的电视是每秒25帧,即每秒更换25个图像,由于视觉暂留效应,所以人眼不会感到闪烁.每 ...
- 02:H.264学习笔记
H.264组成 1.网络提取层 (Network Abstraction Layer,NAL) 2.视讯编码层 (Video Coding Layer,VCL) a.H.264/AVC影像格式阶层架构 ...
- H.264学习笔记6——指数哥伦布编码
一.哥伦布码 哥伦布码就是将编码对象分能成等间隔的若干区间(Group),每个Group有一个索引值:Group Id. >对于Group Id采用二元码编码: >对于Group内的编码对 ...
- H.264学习笔记4——变换量化
A.变换量化过程总体介绍 经过帧内(16x16和4x4亮度.8x8色度)和帧间(4x4~16x16亮度.4x4~8x8色度)像素块预测之后,得到预测块的残差,为了压缩残差信息的统计冗余,需要对残差数据 ...
- H.264学习笔记3——帧间预测
帧间预测主要包括运动估计(运动搜索方法.运动估计准则.亚像素插值和运动矢量估计)和运动补偿. 对于H.264,是对16x16的亮度块和8x8的色度块进行帧间预测编码. A.树状结构分块 H.264的宏 ...
- H.264学习笔记2——帧内预测
帧内预测:根据经过反量化和反变换(没有进行去块效应)之后的同一条带内的块进行预测. A.4x4亮度块预测: 用到的像素和预测方向如图: a~f是4x4块中要预测的像素值,A~Q是临块中解码后的参考值. ...
- 每天进步一点点------H.264学习 (一)
分三个阶段学习1.第一个阶段: 学习H.264,首先要把最基本最必要的资料拿在手里.这些资料包括:标准文档+测试模型+经典文章,在本FTP中能找到.首先看 <H.264_MPEG-4 Part ...
随机推荐
- oracle 10g 实例用localhost无法访问的处理
我在笔记本上安装了一个Oracle10g,安装好了之后,查看E:\oracle\product\10.2.0\db_1\network\ADMIN\tnsnames.ora文件,发现SID对应的IP地 ...
- JSON: Circular Dependency Errors
If you’re using Object Relational Mapping frameworks like Hibernate, and are using the bi-directiona ...
- USING REFLECTION
In this section, you take a closer look at the System.Type class, which enables you to access inform ...
- Lightoj 1019 - Brush (V)
算出从点1到点n的最短路径. /* *********************************************** Author :guanjun Created Time :2016 ...
- 分拆数&&HDU4651
1,有两种DP,复杂度都是O(N^2),但是浪费的侧重点不同,所以根据侧重点分块DP,复杂度可以降到O(N^1.5). 2,母函数+五边形blabla... 占位. 其实就是母函数拆开后,快速知道哪些 ...
- 【BZOJ 2456】 mode
[题目链接] 点击打开链接 [算法] 此题初看是大水题,只需调用std :: sort即可 但是,n最大500000,显然会超时 而且,内存限制1MB,我们连数组也开不了! 那怎么做呢 ? 我们发现, ...
- Java-Runoob-高级教程-实例-字符串:09. Java 实例 - 字符串小写转大写
ylbtech-Java-Runoob-高级教程-实例-字符串:09. Java 实例 - 字符串小写转大写 1.返回顶部 1. Java 实例 - 字符串小写转大写 Java 实例 以下实例使用了 ...
- Android中string.xml中的的标签xliff:g(转载)
转自:http://blog.csdn.net/xuewater/article/details/25687987 在资源文件中写字符串时,如果这个字符串时动态的,又不确定的值在里面,我们就可以用xl ...
- eclipse集成lombok注解不起作用
安装步骤: 步骤一:lombok的下载地址为:https://projectlombok.org/download,jar包很小.这里也把依赖写出来: <dependency> <g ...
- python 高阶函数三 filter()和sorted()
一.filter()函数 filter()接收一个函数和一个序列.filter()把传入的函数依次作用于每个元素,然后根据返回值是True还是False决定保留还是丢弃该元素. >>> ...