day5-WordCount
1. wordcount示例开发
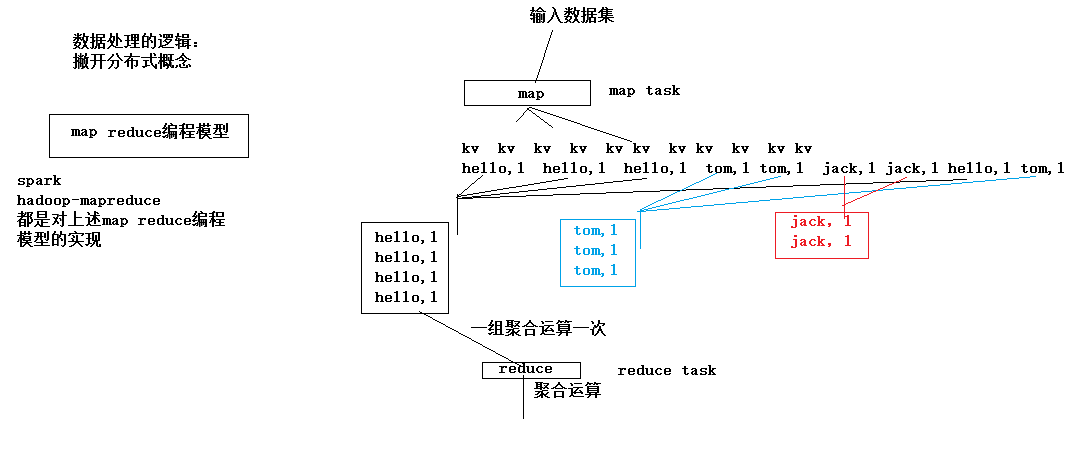
1.1. wordcount程序整体运行流程示意图
map阶段: 将每一行文本数据变成<单词,1>这样的kv数据
reduce阶段:将相同单词的一组kv数据进行聚合:累加所有的v
注意点:mapreduce程序中,
map阶段的进、出数据,
reduce阶段的进、出数据,
类型都应该是实现了HADOOP序列化框架的类型,如:
String对应Text
Integer对应IntWritable
Long对应LongWritable
1.2. 编码实现
WordcountMapper类开发
WordcountReducer类开发
JobSubmitter客户端类开发
《详见代码》
1.3. 运行mr程序
1) 将工程整体打成一个jar包并上传到linux机器上,
2) 准备好要处理的数据文件放到hdfs的指定目录中
3) 用命令启动jar包中的Jobsubmitter,让它去提交jar包给yarn来运行其中的mapreduce程序 : hadoop jar wc.jar cn.edu360.mr.wordcount.JobSubmitter .....
4) 去hdfs的输出目录中查看结果
1.4. mr程序运行模式
mr程序的运行方式:
1、yarn
2、本地(windows linux)
决定以哪种模式运行的
package mr.flow; import java.io.DataInput; import java.io.DataOutput;
import java.io.IOException; import org.apache.hadoop.io.Writable; public class FlowBean implements Writable,Comparable<FlowBean> { private int upFlow;
private int dFlow;
private String phone;
private int amountFlow; public FlowBean(){} public FlowBean(String phone, int upFlow, int dFlow) {
this.phone = phone;
this.upFlow = upFlow;
this.dFlow = dFlow;
this.amountFlow = upFlow + dFlow;
} public String getPhone() {
return phone;
} public void setPhone(String phone) {
this.phone = phone;
} public int getUpFlow() {
return upFlow;
} public void setUpFlow(int upFlow) {
this.upFlow = upFlow;
} public int getdFlow() {
return dFlow;
} public void setdFlow(int dFlow) {
this.dFlow = dFlow;
} public int getAmountFlow() {
return amountFlow;
} public void setAmountFlow(int amountFlow) {
this.amountFlow = amountFlow;
} /**
* hadoop系统在序列化该类的对象时要调用的方法
*/
@Override
public void write(DataOutput out) throws IOException { out.writeInt(upFlow);
out.writeUTF(phone);
out.writeInt(dFlow);
out.writeInt(amountFlow); } /**
* hadoop系统在反序列化该类的对象时要调用的方法
*/
@Override
public void readFields(DataInput in) throws IOException {
this.upFlow = in.readInt();
this.phone = in.readUTF();
this.dFlow = in.readInt();
this.amountFlow = in.readInt();
} @Override
public String toString() { return this.phone + ","+this.upFlow +","+ this.dFlow +"," + this.amountFlow;
} @Override
public int compareTo(FlowBean o) { return o.amountFlow;
} } //
//public class FlowBean implements Writable {
//
// String phoneNum;
//
// public String getPhoneNum() {
// return phoneNum;
// }
//
// public void setPhoneNum(String phoneNum) {
// this.phoneNum = phoneNum;
// }
//
// int upFlow;
// int downFlow;
// int sunFlow;
//
// public FlowBean() {
// }
//
// public FlowBean(int up, int down , String num) {
// this.upFlow = up;
// this.downFlow = down;
// this.sunFlow = up+down;
// this.phoneNum = num;
// }
//
// public int getUpFlow() {
// return upFlow;
// }
//
// public void setUpFlow(int upFlow) {
// this.upFlow = upFlow;
// }
//
// public int getDownFlow() {
// return downFlow;
// }
//
// public void setDownFlow(int downFlow) {
// this.downFlow = downFlow;
// }
//
// public int getSunFlow() {
// return sunFlow;
// }
//
// public void setSunFlow(int sunFlow) {
// this.sunFlow = sunFlow;
// }
//
// /**
// * hadoop系统在序列化该类的对象时要调用的方法
// */
// @Override
// public void readFields(DataInput input) throws IOException {
// this.upFlow = input.readInt();
// this.downFlow = input.readInt();
// this.sunFlow = input.readInt();
// this.phoneNum = input.readUTF();
// }
//
// /**
// * hadoop系统在反序列化该类的对象时要调用的方法
// */
// @Override
// public void write(DataOutput out) throws IOException {
// // TODO Auto-generated method stub
// out.writeInt(upFlow);
// out.writeInt(downFlow);
// out.writeInt(sunFlow);
// out.writeUTF(phoneNum);
// }
//
// @Override
// public String toString() {
// // TODO Auto-generated method stub
// return this.upFlow + "," + this.downFlow + "," + this.sunFlow;
// }
//
//}
package mr.flow;
import java.io.IOException; import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper; public class FlowCountMapper extends Mapper<LongWritable, Text, Text, FlowBean>{ @Override
protected void map(LongWritable key, Text value, Context context)
throws IOException, InterruptedException { String line = value.toString();
String[] fields = line.split("\t"); String phone = fields[1]; int upFlow = Integer.parseInt(fields[fields.length-3]);
int dFlow = Integer.parseInt(fields[fields.length-2]); context.write(new Text(phone), new FlowBean(phone, upFlow, dFlow));
} } //
//import java.io.IOException;
//
//import org.apache.hadoop.io.LongWritable;
//import org.apache.hadoop.io.Text;
//import org.apache.hadoop.mapreduce.Mapper;
//
//public class FlowCountMapper extends Mapper<LongWritable, Text, Text, FlowBean> {
//
// @Override
// protected void map(LongWritable key, Text value,
// Mapper<LongWritable, Text, Text, FlowBean>.Context context)
// throws IOException, InterruptedException {
// String[] values=value.toString().split("/t");
// context.write(new Text(values[1]), new FlowBean(values[1],Integer.parseInt(values[values.length-3]), Integer.parseInt(values[values.length-2])));
//
// }
//
//}
package mr.flow; import java.io.IOException; import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer; public class FlowCountReducer extends Reducer<Text, FlowBean, Text, FlowBean>{ /**
* key:是某个手机号
* values:是这个手机号所产生的所有访问记录中的流量数据
*
* <135,flowBean1><135,flowBean2><135,flowBean3><135,flowBean4>
*/
@Override
protected void reduce(Text key, Iterable<FlowBean> values, Reducer<Text, FlowBean, Text, FlowBean>.Context context)
throws IOException, InterruptedException { int upSum = 0;
int dSum = 0; for(FlowBean value:values){
upSum += value.getUpFlow();
dSum += value.getdFlow();
} context.write(key, new FlowBean(key.toString(), upSum, dSum)); } } //
//import java.io.IOException;
//
//import org.apache.hadoop.io.Text;
//import org.apache.hadoop.mapreduce.Reducer;
//
//public class FlowCountReduce extends Reducer<Text, FlowBean, Text, FlowBean> {
//
// @Override
// protected void reduce(Text key, Iterable<FlowBean> value,
// Reducer<Text, FlowBean, Text, FlowBean>.Context context)
// throws IOException, InterruptedException {
// int upSun=0,downSun=0;
//
// for (FlowBean flowBean : value) {
// upSun+=flowBean.getUpFlow();
// downSun+=flowBean.getAmountFlow();
// }
// context.write(key, new FlowBean( key.toString(),upSun,downSun));
// }
//}
package mr.flow; import java.io.IOException;
import java.net.URI;
import java.net.URISyntaxException; import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat; public class JobSubmitMain { public static final String HADOOP_INPUT_PATH = "hdfs://hadoop1:9000/InputFlow";
public static final String HADOOP_OUTPUT_PATH = "hdfs://hadoop1:9000/OutputFlow";
public static final String HADOOP_ROOT_PATH = "hdfs://hadoop1:9000";
public static void main(String[] args) throws IOException,
ClassNotFoundException, InterruptedException, URISyntaxException {
Configuration conf = new Configuration();
// 2、设置job提交到哪去运行
//conf.set("fs.defaultFS", HADOOP_ROOT_PATH);
//conf.set("mapreduce.framework.name", "yarn");
Job job = Job.getInstance();
job.setJarByClass(JobSubmitMain.class);
job.setMapperClass(FlowCountMapper.class);
job.setReducerClass(FlowCountReducer.class);
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(FlowBean.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(FlowBean.class);
Path output = new Path(HADOOP_OUTPUT_PATH);
FileSystem fs = FileSystem.get(new URI(HADOOP_ROOT_PATH), conf);
if (fs.exists(output)) {
fs.delete(output, true);
}
FileInputFormat.setInputPaths(job, new Path(HADOOP_INPUT_PATH));
FileOutputFormat.setOutputPath(job, output);
job.setNumReduceTasks(1);
//job.submit();
job.waitForCompletion(true);
System.out.println("OK");
}
}
JobSubmitMain
WordCount main 类(Windows需要注意)
package WordCount; import java.io.IOException;
import java.net.URI;
import java.net.URISyntaxException; import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat; public class WordCountMain { public static final String HADOOP_ROOT_PATH = "hdfs://hadoop1:9000";
public static final String HADOOP_INPUT_PATH = "hdfs://hadoop1:9000/Input";
public static final String HADOOP_OUTPUT_PATH = "hdfs://hadoop1:9000/Output"; public static void main(String[] args) throws IOException,
URISyntaxException, ClassNotFoundException, InterruptedException { Configuration conf = new Configuration();
// 1、设置job运行时要访问的默认文件系统
//conf.set("fs.defaultFS", HADOOP_ROOT_PATH);
// 2、设置job提交到哪去运行
conf.set("mapreduce.framework.name", "yarn");
//conf.set("yarn.resourcemanager.hostname", "hadoop1");
// 3、如果要从windows系统上运行这个job提交客户端程序,则需要加这个跨平台提交的参数
//conf.set("mapreduce.app-submission.cross-platform", "true"); Job job = Job.getInstance(conf); // 1、封装参数:jar包所在的位置
job.setJar("/home/hadoop/wordcount.jar");
//job.setJarByClass(WordCountMain.class); // 2、封装参数: 本次job所要调用的Mapper实现类、Reducer实现类
job.setMapperClass(WordCountMapper.class);
job.setReducerClass(WordcountReducer.class); // 3、封装参数:本次job的Mapper实现类、Reducer实现类产生的结果数据的key、value类型
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(IntWritable.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class); // 4、封装参数:本次job要处理的输入数据集所在路径、最终结果的输出路径
Path output = new Path(HADOOP_OUTPUT_PATH);
FileSystem fs = FileSystem.get(new URI(HADOOP_ROOT_PATH), conf);
if (fs.exists(output)) {
fs.delete(output, true);
}
FileInputFormat.setInputPaths(job, new Path(HADOOP_INPUT_PATH));
FileOutputFormat.setOutputPath(job, output); // 注意:输出路径必须不存在 // 5、封装参数:想要启动的reduce task的数量
job.setNumReduceTasks(2); // 6、提交job给yarn
boolean res = job.waitForCompletion(true);
System.out.println("OK");
System.exit(res ? 0 : -1); } }
WordCountMain
关键点是:
v 参数 mapreduce.framework.name = yarn | local
同时,如果要运行在yarn上,以下两个参数也需要配置:
参数 yarn.resourcemanager.hostname = ....
参数 fs.defaultFS = ....
day5-WordCount的更多相关文章
- hadoop 2.7.3本地环境运行官方wordcount
hadoop 2.7.3本地环境运行官方wordcount 基本环境: 系统:win7 虚机环境:virtualBox 虚机:centos 7 hadoop版本:2.7.3 本次先以独立模式(本地模式 ...
- Hadoop3 在eclipse中访问hadoop并运行WordCount实例
前言: 毕业两年了,之前的工作一直没有接触过大数据的东西,对hadoop等比较陌生,所以最近开始学习了.对于我这样第一次学的人,过程还是充满了很多疑惑和不解的,不过我采取的策略是还是先让环 ...
- day5
作业 作业需求: 模拟实现一个ATM + 购物商城程序 额度 15000或自定义 实现购物商城,买东西加入 购物车,调用信用卡接口结账 可以提现,手续费5% 每月22号出账单,每月10号为还款日,过期 ...
- Eclipse 执行成功的 Hadoop-1.2.1 WordCount 源码
万事开头难.最近在学习Hadoop,先是搭建各种版本环境,从2.2.0到2.3.0,再到1.2.1,终于都搭起来了,折腾了1周时间,之后开始尝试使用Eclipse编写小demo.仅复制一个现成的Wor ...
- 软件工程:Wordcount程序作业
由于时间的关系,急着交作业,加上这一次也不是那么很认真的去做,草草写了“Wordcount程序”几个功能,即是 .txt文件的读取,能计算出文件内容的单词数,文件内容的字符数,及行数. 这次选用C来做 ...
- Spark源码编译并在YARN上运行WordCount实例
在学习一门新语言时,想必我们都是"Hello World"程序开始,类似地,分布式计算框架的一个典型实例就是WordCount程序,接触过Hadoop的人肯定都知道用MapRedu ...
- MapReduce剖析笔记之一:从WordCount理解MapReduce的几个阶段
WordCount是一个入门的MapReduce程序(从src\examples\org\apache\hadoop\examples粘贴过来的): package org.apache.hadoop ...
- 软件工程-构建之法 WordCount小程序 统计文件中字符串个数,单词个数,词频,行数
一.前言 在之前写过一个词频统计的C语言课设,别人说你一个大三的怎么写C语言课程,我只想说我是先学习VB,VB是我编程语言的开始,然后接触到C语言及C++:再后来我是学习C++,然后反过来学习C语言, ...
- Python学习记录day5
title: Python学习记录day5 tags: python author: Chinge Yang date: 2016-11-26 --- 1.多层装饰器 多层装饰器的原理是,装饰器装饰函 ...
- eclipse连hadoop2.x运行wordcount 转载
转载地址:http://my.oschina.net/cjun/blog/475576 一.新建java工程,并且导入hadoop相关jar包 此处可以直接创建mapreduce项目就可以,不用下面折 ...
随机推荐
- autoHeight # 动态高度添加 用 window.addEventListener('resize', function () {
动态高度添加 用 window.addEventListener('resize', function () { mounted () { this.init() window.addEventLis ...
- upload 上传按钮组件 iview
<!-- * @description 导入Excel * @fileName importExcel.vue * @author 彭成刚 * @date // :: * @version V1 ...
- vs code 插件list
vs code 插件list
- Spring JDBC 例子
http://www.yiibai.com/spring/spring_jdbc_example.html 要了解有关Spring JDBC框架与JdbcTemplate类的概念,让我们写这将实现所有 ...
- 【软件构造】第八章第三节 代码调优的设计模式和I/O
第八章第三节 代码调优的设计模式和I/O 本节学习如何通过对代码的修改,消除性能瓶颈,提高系统性能?——代码调优.面向性 能的设计模式 Outline Java调优 代码调优的概念 单例模式(Sing ...
- Java之字符,字符串替换
/** 4. 字符串的替换操作 1. String replace(char oldChar,char newChar) //将新字符替换旧字符 3. String replaceFirst(Stri ...
- ping ip
def ip_and_time(): """ get ip to ping from ip.txt then return two list , each ip that ...
- 自定义shell脚本
当脚本需要加入固定的内容时就可以直接使用此文件 1.在用户的家目录下创建.vimrc文件(root用户就在root目录下创建,其他用户就在其他用户家目录下创建这个隐藏文件) 2. 将以下代码写入此文件 ...
- MySQL数据类型与操作
内容提要: 建表完整语法规范(create table 表格(字段名1 类型 (宽度) 约束条件)) MySQL数据库数据类型(整型.浮点型.字符类型(char与varchar).日期类型.枚举与集合 ...
- django的基本操作流程
pip install django cd Desktop/课上代码02/ #进入到创建项目的目录 django-admin startproject 项目的名称 #创建项目 __ini ...