poj 2976 Dropping tests (二分搜索之最大化平均值之01分数规划)
Description
In a certain course, you take n tests. If you get ai out of bi questions correct on test i, your cumulative average is defined to be
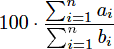
.
.
Given your test scores and a positive integer k, determine how high you can make your cumulative average if you are allowed to drop any k of your test scores. Suppose you take tests with scores of /, /, and /. Without dropping any tests, your cumulative average is . However, if you drop the third test, your cumulative average becomes
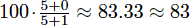
.
Input
The input test file will contain multiple test cases, each containing exactly three lines. The first line contains two integers, ≤ n ≤ and ≤ k < n. The second line contains nintegers indicating ai for all i. The third line contains n positive integers indicating bi for all i. It is guaranteed that ≤ ai ≤ bi ≤ , , , . The end-of-file is marked by a test case with n = k = and should not be processed.
Output
For each test case, write a single line with the highest cumulative average possible after dropping k of the given test scores. The average should be rounded to the nearest integer.
Sample Input
Sample Output
Hint
To avoid ambiguities due to rounding errors, the judge tests have been constructed so that all answers are at least 0.001 away from a decision boundary (i.e., you can assume that the average is never 83.4997).
Source
#include<iostream>
#include<cstdio>
#include<cstring>
#include<algorithm>
#include<math.h>
#include<stdlib.h>
using namespace std;
#define N 1006
int n,k;
double ratio;
struct Node{
double a,b;
bool friend operator <(Node x,Node y){
return x.a-ratio*x.b>y.a-ratio*y.b;
}
}node[N];
bool solve(double mid){
ratio=mid;
sort(node,node+n);
double sum1=;
double sum2=;
for(int i=;i<n-k;i++){
sum1+=node[i].a;
sum2+=node[i].b;
}
return sum1/sum2>=mid;
} int main()
{
while(scanf("%d%d",&n,&k)== && n+k!=){
for(int i=;i<n;i++){
scanf("%lf",&node[i].a);
}
for(int i=;i<n;i++){
scanf("%lf",&node[i].b);
}
double low=;
double high=;
for(int i=;i<;i++){
double mid=(low+high)/;
if(solve(mid)){
low=mid;
}
else{
high=mid;
}
}
printf("%.0lf\n",high*);
}
return ;
}
乍看以为贪心或dp能解决,后来发现贪心策略与当前的总体准确率有关,行不通,于是二分解决。
依然需要确定一个贪心策略,每次贪心地去掉那些对正确率贡献小的考试。如何确定某个考试[a_i, b_i]对总体准确率x的贡献呢?a_i / b_i肯定是不行的,不然例子里的[0,1]会首当其冲被刷掉。在当前准确率为x的情况下,这场考试“额外”对的题目数量是a_i – x * b_i,当然这个值有正有负,恰好可以作为“贡献度”的测量。于是利用这个给考试排个降序,后k个刷掉就行了。
之后就是二分搜索了,从0到1之间搜一遍,我下面的注释应该很详细,不啰嗦了。
#ifndef ONLINE_JUDGE
#pragma warning(disable : 4996)
#endif
#include <iostream>
#include <algorithm>
#include <cmath>
#include <iomanip>
using namespace std; #define MAX_N 1000
int n, k;
double x; // 搜索过程中的正确率
struct Test
{
int a, b;
bool operator < (const Test& other) const
{
return a - x * b > other.a - x * other.b; // 按照对准确率的贡献从大到小排序
}
};
Test test[MAX_N]; // 判断是否能够获得大于mid的准确率
bool C(double mid)
{
x = mid;
sort(test, test + n);
double total_a = , total_b = ;
for (int i = ; i < n - k; ++i) // 去掉后k个数计算准确率
{
total_a += test[i].a;
total_b += test[i].b;
} return total_a / total_b > mid;
} ///////////////////////////SubMain//////////////////////////////////
int main(int argc, char *argv[])
{
#ifndef ONLINE_JUDGE
freopen("in.txt", "r", stdin);
freopen("out.txt", "w", stdout);
#endif
while (cin >> n >> k && (n || k))
{
for (int i = ; i < n; ++i)
{
cin >> test[i].a;
}
for (int i = ; i < n; ++i)
{
cin >> test[i].b;
} double lb = ; double ub = ;
while (abs(ub - lb) > 1e-)
{
double mid = (lb + ub) / ;
if (C(mid))
{
lb = mid; // 行,说明mid太小
}
else
{
ub = mid; // 不行,说明mid太大
}
} cout << fixed << setprecision() << lb * << endl;
}
#ifndef ONLINE_JUDGE
fclose(stdin);
fclose(stdout);
system("out.txt");
#endif
return ;
}
///////////////////////////End Sub//////////////////////////////////
poj 2976 Dropping tests (二分搜索之最大化平均值之01分数规划)的更多相关文章
- poj 3111 K Best (二分搜索之最大化平均值之01分数规划)
Description Demy has n jewels. Each of her jewels has some value vi and weight wi. Since her husband ...
- POJ 2976 Dropping tests【二分 最大化平均值】
题意:定义最大平均分为 (a1+a2+a3+---+an)/(b1+b2+---+bn),求任意去除k场考试的最大平均成绩 和挑战程序设计上面的最大化平均值的例子一样 判断是否存在x满足条件 (a1+ ...
- poj 2976 Dropping tests 二分搜索+精度处理
Dropping tests Time Limit: 1000MS Memory Limit: 65536K Total Submissions: 8349 Accepted: 2919 De ...
- NYOJ 914 Yougth的最大化【二分/最大化平均值模板/01分数规划】
914-Yougth的最大化 内存限制:64MB 时间限制:1000ms 特判: No 通过数:3 提交数:4 难度:4 题目描述: Yougth现在有n个物品的重量和价值分别是Wi和Vi,你能帮他从 ...
- 二分算法的应用——最大化平均值 POJ 2976 Dropping tests
最大化平均值 有n个物品的重量和价值分别wi 和 vi.从中选出 k 个物品使得 单位重量 的价值最大. 限制条件: <= k <= n <= ^ <= w_i <= v ...
- POJ - 2976 Dropping tests && 0/1 分数规划
POJ - 2976 Dropping tests 你有 \(n\) 次考试成绩, 定义考试平均成绩为 \[\frac{\sum_{i = 1}^{n} a_{i}}{\sum_{i = 1}^{n} ...
- POJ - 2976 Dropping tests(01分数规划---二分(最大化平均值))
题意:有n组ai和bi,要求去掉k组,使下式值最大. 分析: 1.此题是典型的01分数规划. 01分数规划:给定两个数组,a[i]表示选取i的可以得到的价值,b[i]表示选取i的代价.x[i]=1代表 ...
- POJ 2976 Dropping tests 【01分数规划+二分】
题目链接:http://poj.org/problem?id=2976 Dropping tests Time Limit: 1000MS Memory Limit: 65536K Total S ...
- POJ 2976 Dropping tests(01分数规划入门)
Dropping tests Time Limit: 1000MS Memory Limit: 65536K Total Submissions: 11367 Accepted: 3962 D ...
随机推荐
- 基于年纪和成本(Age & Cost)的缓存替换(cache replacement)机制
一.客户端的缓存与缓存替换机制 客户端的资源缓存: 在客户端游戏中,通常有大量的资源要处理,这些可能包括贴图.动作.模型.特效等等,这些资源往往存在着磁盘文件->内存(->显存)的数据通路 ...
- 应用按home键无最近应用
在应用的AndroidManifest里面添加加载模式
- sqlserver,执行生成脚本时“引发类型为“System.OutOfMemoryException”的异常”(已解决)
sqlserver,执行生成脚本时“引发类型为“System.OutOfMemoryException”的异常”(已解决) 出现此错误主要是因为.sql的脚本文件过大(一般都超过100M)造成内存无法 ...
- SAN和NAS的区别
SAN : STORAGE AREA NETWORK 存储区域网络 NAS : NETWORK ATTACHED STORAGE 网络附加存储 NAS不一定是盘阵,一台普通的主机就可以做出NAS, ...
- sed删除空行和注释行
最近在看前辈们写的代码,他们把没有用的代码是注释掉而不是删掉.没用的代码和注释很乱,看着心烦,就把注释删掉来解读,顿时爽快多了. 不多说了,直接举例子 比如一个文本文件 data 里的内弄为 cat ...
- saltstack对递归依赖条件(死循环依赖)的处理
本文将对saltstack中状态文件中require条件产生死循环的情形进行简单的测试和分析 测试思路: 写一个包含递归依赖条件的状态文件,进行测试: A依赖于B B依赖于C ...
- Xcode itunes完美打包api方法
转:http://bbs.csdn.net/topics/390948190 Xcode6 itunes完美打包api 方法! 特点轻盈小巧,方便快捷!
- ubuntu 安装RPM软件包
red hat 系统用rpm格式的文件安装软件,ubuntu安装软件是用deb格式的文件安装 在ubuntu上安装rmp文件格式的软件包步骤: 1.安装转换软件 alien(需要联网) apt-get ...
- zookeeper初体验之关于解决quartz重复执行任务的一种思路
前阵子工作中遇到了一个很麻烦的问题.本人所在的项目组做了一个机遇quartz集群的任务系统.通俗点讲就是用quartz框架(quartz是一款能跑定时任务的框架支持复杂的时间表达式)来执行定时任务.但 ...
- C++ list用法
创建一个list实例并赋值: // 创建实例以及赋值 #include <iostream> #include <list> using namespace std; int ...