深度学习基础系列(三)| sigmoid、tanh和relu激活函数的直观解释
常见的激活函数有sigmoid、tanh和relu三种非线性函数,其数学表达式分别为:
- sigmoid: y = 1/(1 + e-x)
- tanh: y = (ex - e-x)/(ex + e-x)
- relu: y = max(0, x)
其代码实现如下:
import numpy as np
import matplotlib.pyplot as plt def sigmoid(x):
return 1 / (1 + np.exp(-x)) def tanh(x):
return (np.exp(x) - np.exp(-x)) / (np.exp(x) + np.exp(-x)) def relu(x):
return np.maximum(0, x) x = np.arange(-5, 5, 0.1)
p1 = plt.subplot(311)
y = tanh(x)
p1.plot(x, y)
p1.set_title('tanh')
p1.axhline(ls='--', color='r')
p1.axvline(ls='--', color='r') p2 = plt.subplot(312)
y = sigmoid(x)
p2.plot(x, y)
p2.set_title('sigmoid')
p2.axhline(0.5, ls='--', color='r')
p2.axvline(ls='--', color='r') p3 = plt.subplot(313)
y = relu(x)
p3.plot(x, y)
p3.set_title('relu')
p3.axvline(ls='--', color='r') plt.subplots_adjust(hspace=1)
plt.show()
其图形解释如下:
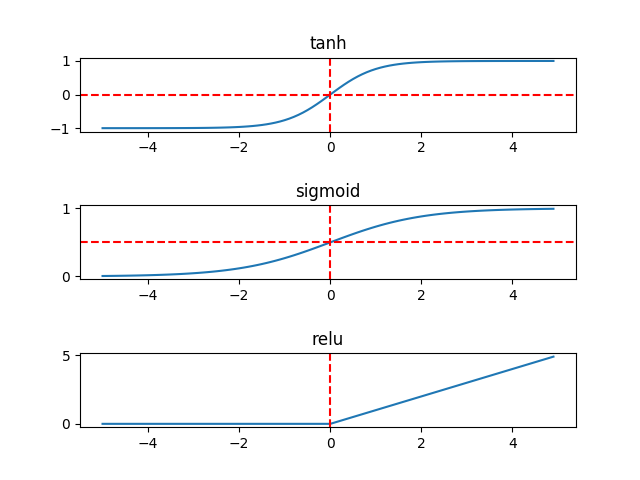
相较而言,在隐藏层,tanh函数要优于sigmoid函数,可以认为是sigmoid的平移版本,优势在于其取值范围介于-1 ~ 1之间,数据的平均值为0,而不像sigmoid为0.5,有类似数据中心化的效果。
但在输出层,sigmoid也许会优于tanh函数,原因在于你希望输出结果的概率落在0 ~ 1 之间,比如二元分类,sigmoid可作为输出层的激活函数。
但实际应用中,特别是深层网络在训练时,tanh和sigmoid会在端值趋于饱和,造成训练速度减慢,故深层网络的激活函数默认大多采用relu函数,浅层网络可以采用sigmoid和tanh函数。
另外有必要了解激活函数的求导公式,在反向传播中才知道是如何进行梯度下降。三个函数的求导结果及推理过程如下:
1. sigmoid求导函数:
其中,sigmoid函数定义为 y = 1/(1 + e-x) = (1 + e-x)-1
与此相关的基础求导公式:(xn)' = n * xn-1 和 (ex)' = ex
应用链式法则,其求导过程为:dy/dx = -1 * (1 + e-x)-2 * e-x * (-1)
= e-x * (1 + e-x)-2
= (1 + e-x - 1) / (1 + e-x)2
= (1 + e-x)-1 - (1 + e-x)-2
= y - y2
= y(1 -y)
2. tanh求导函数:
其中,tanh函数定义为 y = (ex - e-x)/(ex + e-x)
与此相关的基础求导公式:(u/v)' = (u' v - uv') / v2
同样应用链式法则,其求导过程为:dy/dx = ( (ex - e-x)' * (ex + e-x) - (ex - e-x) * (ex + e-x)' ) / (ex + e-x)2
= ( (ex - (-1) * e-x) * (ex + e-x) - (ex - e-x) * (ex + (-1) * e-x) ) / (ex + e-x)2
= ( (ex + e-x)2 - (ex - e-x)2 ) / (ex + e-x)2
= 1 - ( (ex - e-x)/(ex + e-x) )2
= 1 - y2
3. relu求导函数:
其中,relu函数定义为 y = max(0, x)
可以简单推理出 当x <0 时,dy/dx = 0; 当 x >= 0时,dy/dx = 1
深度学习基础系列(三)| sigmoid、tanh和relu激活函数的直观解释的更多相关文章
- 深度学习基础系列(五)| 深入理解交叉熵函数及其在tensorflow和keras中的实现
在统计学中,损失函数是一种衡量损失和错误(这种损失与“错误地”估计有关,如费用或者设备的损失)程度的函数.假设某样本的实际输出为a,而预计的输出为y,则y与a之间存在偏差,深度学习的目的即是通过不断地 ...
- 深度学习基础系列(九)| Dropout VS Batch Normalization? 是时候放弃Dropout了
Dropout是过去几年非常流行的正则化技术,可有效防止过拟合的发生.但从深度学习的发展趋势看,Batch Normalizaton(简称BN)正在逐步取代Dropout技术,特别是在卷积层.本文将首 ...
- 深度学习基础系列(七)| Batch Normalization
Batch Normalization(批量标准化,简称BN)是近些年来深度学习优化中一个重要的手段.BN能带来如下优点: 加速训练过程: 可以使用较大的学习率: 允许在深层网络中使用sigmoid这 ...
- 深度学习基础(三)NIN_Network In Network
该论文提出了一种新颖的深度网络结构,称为"Network In Network"(NIN),以增强模型对感受野内local patches的辨别能力.与传统的CNNs相比,NIN主 ...
- 深度学习基础系列(十一)| Keras中图像增强技术详解
在深度学习中,数据短缺是我们经常面临的一个问题,虽然现在有不少公开数据集,但跟大公司掌握的海量数据集相比,数量上仍然偏少,而某些特定领域的数据采集更是非常困难.根据之前的学习可知,数据量少带来的最直接 ...
- 深度学习基础系列(四)| 理解softmax函数
深度学习最终目的表现为解决分类或回归问题.在现实应用中,输出层我们大多采用softmax或sigmoid函数来输出分类概率值,其中二元分类可以应用sigmoid函数. 而在多元分类的问题中,我们默认采 ...
- 深度学习基础系列(十)| Global Average Pooling是否可以替代全连接层?
Global Average Pooling(简称GAP,全局池化层)技术最早提出是在这篇论文(第3.2节)中,被认为是可以替代全连接层的一种新技术.在keras发布的经典模型中,可以看到不少模型甚至 ...
- 深度学习基础系列(一)| 一文看懂用kersa构建模型的各层含义(掌握输出尺寸和可训练参数数量的计算方法)
我们在学习成熟网络模型时,如VGG.Inception.Resnet等,往往面临的第一个问题便是这些模型的各层参数是如何设置的呢?另外,我们如果要设计自己的网路模型时,又该如何设置各层参数呢?如果模型 ...
- 深度学习基础系列(二)| 常见的Top-1和Top-5有什么区别?
在深度学习过程中,会经常看见各成熟网络模型在ImageNet上的Top-1准确率和Top-5准确率的介绍,如下图所示: 那Top-1 Accuracy和Top-5 Accuracy是指什么呢?区别在哪 ...
随机推荐
- 2017北京国庆刷题Day7 afternoon
期望得分:100+30+100=230 实际得分:60+30+100=190 排序去重 固定右端点,左端点单调不减 考场上用了二分,没去重,60 #include<cstdio> #inc ...
- NOIP模拟赛17
5分.... T1 LOJ 计算几何瞎暴力 维护以下操作: 1.序列末尾加一个数 2.序列全体从小到大排序 3.查询区间和 4.序列全体异或一个数k 序列全体异或一个数,很明显是trie树 那么序列全 ...
- HNOI2004 宠物收养所 (Treap)
1285 宠物收养所 http://codevs.cn/problem/1285/ 时间限制: 1 s 空间限制: 128000 KB 题目描述 Description 最近,阿Q开了一间 ...
- [数据库中间件]将用户添加到DB2组授权
1.将用户oracle添加到db2的用户组中,命令如下: usermod -a -G db2iam #将用户添加到组中并不改变当前所属组 注:以下与主题无关,只是列举一些关于用户的命令 id user ...
- 关于Java泛型深入理解小总结
1.何为泛型 首先泛型的本质便是类型参数化,通俗的说就是用一个变量来表示类型,这个类型可以是String,Integer等等不确定,表明可接受的类型,原理类似如下代码 int pattern; //声 ...
- TED_Topic2:My desperate journey with a human smuggler
My desperate journey with a human smuggler By Barat Ali Batoor When I was a child there was a toy wh ...
- 【acmm】一道简单的数学题
emm卡常 我本来写成了这个样子: #include<bits/stdc++.h> using namespace std; typedef long long LL; ; struct ...
- 【BZOJ】2466: [中山市选2009]树 高斯消元解异或方程组
[题意]给定一棵树的灯,按一次x改变与x距离<=1的点的状态,求全0到全1的最少次数.n<=100. [算法]高斯消元解异或方程组 [题解]设f[i]=0/1表示是否按第i个点的按钮,根据 ...
- 计算1到N中各个数字出现的次数 --数位DP
题意:给定一个数n,问从1到n中,0~9这10个数字分别出现了多少次.比如366这个数,3出现了1次,6出现了2次. 题解:<剑指offer>P174:<编程之美>P132 都 ...
- 大聊PYthon----生成器
再说迭代器与生成器之前,先说一说列表生成式 列表生成式 什么是列表生成式呢? 这个非常简单! 先看看普通青年版的! >>> a [0, 1, 2, 3, 4, 5, 6, 7, 8, ...