FFTW3学习笔记3:FFTW 和 CUFFT 的使用对比
一、流程
1.使用cufftHandle创建句柄
2.使用cufftPlan1d(),cufftPlan3d(),cufftPlan3d(),cufftPlanMany()对句柄进行配置,主要是配置句柄对应的信号长度,信号类型,在内存中的存储形式等信息。
cufftPlan1d():针对单个 1 维信号
cufftPlan2d():针对单个 2 维信号
cufftPlan3d():针对单个 3 维信号
cufftPlanMany():针对多个信号同时进行 fft
3.使用cufftExec()函数执行 fft
4.使用cufftDestroy()函数释放 GPU 资源
二、单个 1 维信号的 fft
假设要执行 fft 的信号data_dev的长度为N,并且已经传输到 GPU 显存中,data_dev数据的类型为cufftComplex,可以用一下方式产生主机段的data_dev。
cufftComplex *data_Host = (cufftComplex*)malloc(NX*BATCH * sizeof(cufftComplex)); // 主机端数据头指针
// 初始数据
for (int i = ; i < NX; i++)
{
data_Host[i].x = float((rand() * rand()) % NX) / NX;
data_Host[i].y = float((rand() * rand()) % NX) / NX;
}
然后用cudaMemcpy()将主机端的data_host拷贝到设备端的data_dev,即可用下述方法执行 fft :
cufftHandle plan; // 创建cuFFT句柄
cufftPlan1d(&plan, N, CUFFT_C2C, BATCH);
cufftExecC2C(plan, data_dev, data_dev, CUFFT_FORWARD); // 执行 cuFFT,正变换
cufftPlan1d():
- 第一个参数就是要配置的 cuFFT 句柄;
- 第二个参数为要进行 fft 的信号的长度;
- 第三个
CUFFT_C2C为要执行 fft 的信号输入类型及输出类型都为复数;CUFFT_C2R表示输入复数,输出实数;CUFFT_R2C表示输入实数,输出复数;CUFFT_R2R表示输入实数,输出实数; - 第四个参数
BATCH表示要执行 fft 的信号的个数,新版的已经使用cufftPlanMany()来同时完成多个信号的 fft。
cufftExecC2C():
- 第一个参数就是配置好的 cuFFT 句柄;
- 第二个参数为输入信号的首地址;
- 第三个参数为输出信号的首地址;
- 第四个参数
CUFFT_FORWARD表示执行的是 fft 正变换;CUFFT_INVERSE表示执行 fft 逆变换。
需要注意的是,执行完逆 fft 之后,要对信号中的每个值乘以 1/N
三、代码实现
#include <iostream>
#include <time.h>
#include "cuda_runtime.h"
#include "device_launch_parameters.h"
#include <cufft.h> #define NX 3335 // 有效数据个数
#define N 5335 // 补0之后的数据长度
#define BATCH 1
#define BLOCK_SIZE 1024
using std::cout;
using std::endl; /**
* 功能:判断两个 cufftComplex 数组的是否相等
* 输入:idataA 输入数组A的头指针
* 输入:idataB 输出数组B的头指针
* 输入:size 数组的元素个数
* 返回:true | false
*/
bool IsEqual(cufftComplex *idataA, cufftComplex *idataB, const int size)
{
for (int i = ; i < size; i++)
{
if (abs(idataA[i].x - idataB[i].x) > 0.000001 || abs(idataA[i].y - idataB[i].y) > 0.000001)
return false;
} return true;
} /**
* 功能:实现 cufftComplex 数组的尺度缩放,也就是乘以一个数
* 输入:idata 输入数组的头指针
* 输出:odata 输出数组的头指针
* 输入:size 数组的元素个数
* 输入:scale 缩放尺度
*/
static __global__ void cufftComplexScale(cufftComplex *idata, cufftComplex *odata, const int size, float scale)
{
const int threadID = blockIdx.x * blockDim.x + threadIdx.x; if (threadID < size)
{
odata[threadID].x = idata[threadID].x * scale;
odata[threadID].y = idata[threadID].y * scale;
}
} int main()
{
cufftComplex *data_dev; // 设备端数据头指针
cufftComplex *data_Host = (cufftComplex*)malloc(NX*BATCH * sizeof(cufftComplex)); // 主机端数据头指针
cufftComplex *resultFFT = (cufftComplex*)malloc(N*BATCH * sizeof(cufftComplex)); // 正变换的结果
cufftComplex *resultIFFT = (cufftComplex*)malloc(NX*BATCH * sizeof(cufftComplex)); // 先正变换后逆变换的结果 // 初始数据
for (int i = ; i < NX; i++)
{
data_Host[i].x = float((rand() * rand()) % NX) / NX;
data_Host[i].y = float((rand() * rand()) % NX) / NX;
} dim3 dimBlock(BLOCK_SIZE); // 线程块
dim3 dimGrid((NX + BLOCK_SIZE - ) / dimBlock.x); // 线程格 cufftHandle plan; // 创建cuFFT句柄
cufftPlan1d(&plan, N, CUFFT_C2C, BATCH); // 计时
clock_t start, stop;
double duration;
start = clock(); cudaMalloc((void**)&data_dev, sizeof(cufftComplex)*N*BATCH); // 开辟设备内存
cudaMemset(data_dev, , sizeof(cufftComplex)*N*BATCH); // 初始为0
cudaMemcpy(data_dev, data_Host, NX * sizeof(cufftComplex), cudaMemcpyHostToDevice); // 从主机内存拷贝到设备内存 cufftExecC2C(plan, data_dev, data_dev, CUFFT_FORWARD); // 执行 cuFFT,正变换
cudaMemcpy(resultFFT, data_dev, N * sizeof(cufftComplex), cudaMemcpyDeviceToHost); // 从设备内存拷贝到主机内存 cufftExecC2C(plan, data_dev, data_dev, CUFFT_INVERSE); // 执行 cuFFT,逆变换
cufftComplexScale << <dimGrid, dimBlock >> > (data_dev, data_dev, N, 1.0f / N); // 乘以系数
cudaMemcpy(resultIFFT, data_dev, NX * sizeof(cufftComplex), cudaMemcpyDeviceToHost); // 从设备内存拷贝到主机内存 stop = clock();
duration = (double)(stop - start) * / CLOCKS_PER_SEC;
cout << "时间为 " << duration << " ms" << endl; cufftDestroy(plan); // 销毁句柄
cudaFree(data_dev); // 释放空间 cout << IsEqual(data_Host, resultIFFT, NX) << endl; return ;
}
四、用fftw和cufft实现傅里叶变换
1.创建C++的文件命名为fftw.cpp,配置fftw环境(环境配置移步:这里),复制以下代码
#include "stdafx.h"
#include <stdio.h>
#include <stdlib.h>
#include <math.h>
#include "fftw3.h"
#include <windows.h>
#include <Eigen/Dense>
#include <iostream>
#include <opencv2/core/eigen.hpp>
#include <opencv2/opencv.hpp>
#include <iostream> using namespace cv;
using namespace std;
using namespace Eigen; #define COLS 3
#define ROWS 3 #pragma comment(lib, "libfftw3-3.lib") // double版本
//#pragma comment(lib, "libfftw3f-3.lib")// float版本
// #pragma comment(lib, "libfftw3l-3.lib")// long double版本 extern "C" void iteration_mat1(); /**********************************主函数****************************************/
int main()
{ fftw_complex*result_temp_din, *result_temp_out;
fftw_plan p; result_temp_din = (fftw_complex *)fftw_malloc(sizeof(fftw_complex)*COLS*ROWS);
result_temp_out = (fftw_complex *)fftw_malloc(sizeof(fftw_complex)*COLS*ROWS);
cout << "fftw" << endl; for (size_t j = ; j < ROWS; j++)
{
for (size_t i = ; i < COLS; i++)
{ result_temp_din[i + j*COLS][] = (i+)*(j+);
cout << result_temp_din[i + j*COLS][] << " ";
result_temp_din[i + j*COLS][] = ;
}
} //forward fft
p = fftw_plan_dft_2d(ROWS, COLS, result_temp_din, result_temp_out, FFTW_FORWARD, FFTW_ESTIMATE); fftw_execute(p);
cout << endl;
for (size_t j = ; j < ROWS; j++)
{
for (size_t i = ; i < COLS; i++)
{
cout << result_temp_out[i + j*COLS][] << " ";//实部
cout << result_temp_out[i + j*COLS][] << endl;//虚部
}
} cout << "cuda" << endl;
iteration_mat1();
system("pause");
return ;
}
2.创建cuda文件命名为cufft.cu,配置环境(环境配置移步:这里),复制以下代码
注: cufftPlan2d(&p, ROWS, COLS, CUFFT_C2C); 看清楚rows和cols,千万别出错!
#include "cuda_runtime.h"
#include "device_launch_parameters.h"
#include <cufft.h>
#include <stdio.h>
#include <opencv2/opencv.hpp>
#include <iostream> using namespace std;
using namespace cv; #define COLS 3
#define ROWS 3 extern "C" void iteration_mat1()
{
cufftComplex *result_temp_din = (cufftComplex*)malloc(COLS*ROWS * sizeof(cufftComplex));
cufftHandle p;
//输入赋值数据
for (size_t j = ; j < ROWS; j++)
{
for (size_t i = ; i < COLS; i++)
{
result_temp_din[i + j*COLS].x = (i + )*(j + );
cout << result_temp_din[i + j*COLS].x << " ";
result_temp_din[i + j*COLS].y = ;
}
}
cout << endl; size_t pitch; cufftComplex *t_result_temp_din;
cudaMallocPitch((void**)&t_result_temp_din, &pitch, COLS * sizeof(cufftComplex), ROWS); cufftComplex *t_result_temp_out;
cudaMallocPitch((void**)&t_result_temp_out, &pitch, COLS * sizeof(cufftComplex), ROWS); //将值辅到Device
//cudaMemcpy2D(t_result_temp_din, pitch, result_temp_din, COLS * sizeof(cufftComplex), COLS * sizeof(cufftComplex), ROWS, cudaMemcpyHostToDevice);
cudaMemcpy(t_result_temp_din,result_temp_din, ROWS * sizeof(cufftComplex)* COLS, cudaMemcpyHostToDevice); //forward fft 制定变换规则
cufftPlan2d(&p, ROWS, COLS, CUFFT_C2C); //执行变换
cufftExecC2C(p, (cufftComplex*)t_result_temp_din, (cufftComplex*)t_result_temp_out, CUFFT_FORWARD); //将值辅到host
cudaMemcpy(result_temp_din, t_result_temp_out, ROWS * sizeof(cufftComplex)* COLS, cudaMemcpyDeviceToHost);
//cudaMemcpy2D(result_temp_din, pitch, t_result_temp_out, COLS * sizeof(cufftComplex), sizeof(cufftComplex)* ROWS, COLS, cudaMemcpyDeviceToHost); //提取实部和虚部
for (size_t j = ; j < ROWS; j++)
{
for (size_t i = ; i < COLS; i++)
{
cout << result_temp_din[i + j*COLS].x << " ";//实部
cout << result_temp_din[i + j*COLS].y << endl;//虚部
}
} }
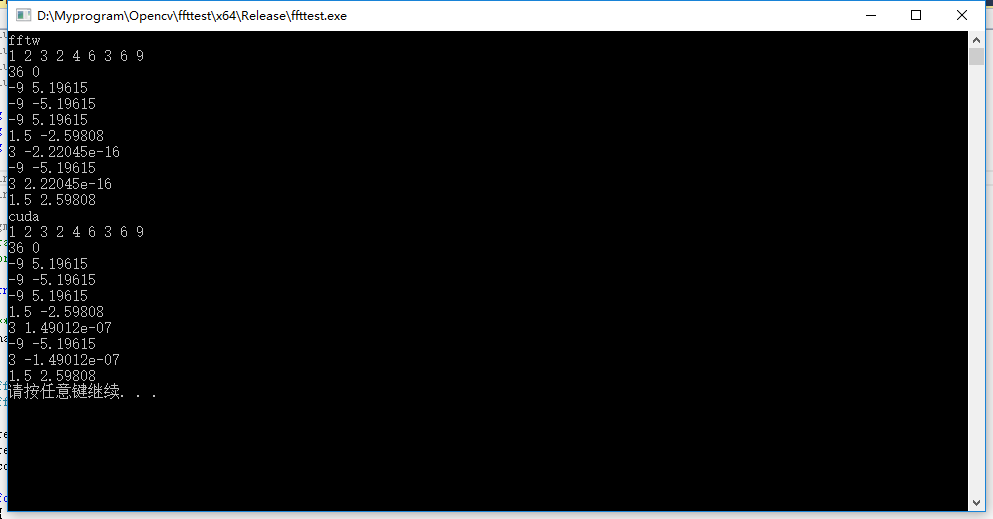
3.执行结果:
FFTW3学习笔记3:FFTW 和 CUFFT 的使用对比的更多相关文章
- Java NIO 学习笔记(七)----NIO/IO 的对比和总结
目录: Java NIO 学习笔记(一)----概述,Channel/Buffer Java NIO 学习笔记(二)----聚集和分散,通道到通道 Java NIO 学习笔记(三)----Select ...
- FFTW3学习笔记2:FFTW(快速傅里叶变换)中文参考
据说FFTW(Fastest Fourier Transform in the West)是世界上最快的FFT.为了详细了解FFTW以及为编程方便,特将用户手册看了一下,并结合手册制作了以下FFTW中 ...
- FFTW3学习笔记1:VS2015下配置FFTW3(快速傅里叶变换)库
一.FFTW简介 FFTW ( the Faster Fourier Transform in the West) 是一个快速计算离散傅里叶变换的标准C语言程序集,其由MIT的M.Frigo 和S. ...
- PHP学习笔记(8)验证码使用session对比
知识点: 1. session获取其他页面的变量: (1)先在画验证码php里开启session_start(),$_SESSION['随便起名']=验证码字符串, (2)再在submit提交到act ...
- Java NIO 学习笔记(六)----异步文件通道 AsynchronousFileChannel
目录: Java NIO 学习笔记(一)----概述,Channel/Buffer Java NIO 学习笔记(二)----聚集和分散,通道到通道 Java NIO 学习笔记(三)----Select ...
- Java NIO 学习笔记(五)----路径、文件和管道 Path/Files/Pipe
目录: Java NIO 学习笔记(一)----概述,Channel/Buffer Java NIO 学习笔记(二)----聚集和分散,通道到通道 Java NIO 学习笔记(三)----Select ...
- Java NIO 学习笔记(四)----文件通道和网络通道
目录: Java NIO 学习笔记(一)----概述,Channel/Buffer Java NIO 学习笔记(二)----聚集和分散,通道到通道 Java NIO 学习笔记(三)----Select ...
- Java NIO 学习笔记(三)----Selector
目录: Java NIO 学习笔记(一)----概述,Channel/Buffer Java NIO 学习笔记(二)----聚集和分散,通道到通道 Java NIO 学习笔记(三)----Select ...
- Java NIO 学习笔记(二)----聚集和分散,通道到通道
目录: Java NIO 学习笔记(一)----概述,Channel/Buffer Java NIO 学习笔记(二)----聚集和分散,通道到通道 Java NIO 学习笔记(三)----Select ...
随机推荐
- 【CodeForces】708 B. Recover the String 数学构造
[题目]B. Recover the String [题意]找到一个串s,满足其中子序列{0,0}{0,1}{1,0}{1,1}的数量分别满足给定的数a1~a4,或判断不存在.数字<=10^9, ...
- 2017ACM暑期多校联合训练 - Team 2 1009 HDU 60563 TrickGCD (容斥公式)
题目链接 Problem Description You are given an array A , and Zhu wants to know there are how many differe ...
- 项目开发 -- ZFS容量分配
存储池 allocated 池中已实际分配的存储空间量.该属性也可通过其简短列名alloc来引用. capacity 已用的池空间百分比.此属性也可通过其简短列名cap来引用. dedupratio ...
- jQuery实现简单前端搜索功能
<!DOCTYPE html> <html lang="en"> <head> <meta charset="UTF-8&quo ...
- MySQL join 用法
select column1, column2 from TABLE1 join TABLE2 on 条件 # select * from table1 join table2; #两个表合成一个se ...
- UNIX环境高级编程学习笔记(十)为何 fork 函数会有两个不同的返回值【转】
转自:http://blog.csdn.net/fool_duck/article/details/46917377 以下是基于 linux 0.11 内核的说明. 在init/main.c第138行 ...
- linux设置时区同步时间
linux设置时区同步时间 一.运行tzselect sudo tzselect 在这里我们选择亚洲 Asia,确认之后选择中国(China),最后选择北京(Beijing) 如图: 二.复制文件 ...
- elk系列2之multiline模块的使用【转】
preface 上回说道了elk的安装以及kibana的简单搜索语法,还有logstash的input,output的语法,但是我们在使用中发现了一个问题,我们知道,elk是每一行为一个事件,像Jav ...
- C#:Excel上传服务器后导入数据库
- [ python ] 变量及基础的数据类型
python2 和 python3 不同的编码方式 python2 默认编码方式是 ascii码 python3 默认编码方式是 utf-8 具体表现为:当 python3 和 python2 在打印 ...