大数据-zookeeper集群安装
一、安装前发现的问题:
1、安装前期发现jps权限不够
[root@master1 ~]# jps
-bash: /opt/workspace/jdk1./bin/jps: Permission denied
解决:
这时只需要添加一个权限即可 chmod +x /usr/local/jdk8/bin/jps x是执行权限
2、中文乱码问题
解决:编辑服务器文件
vim etc/locale.conf

3、journalnode启动java权限问题
chmod +x /opt/workspace/jdk1./bin/java
二、安装zookeeper
(1)下载源码并解压
地址http://mirror.bit.edu.cn/apache/zookeeper/
mkdir /opt/workspace/zookeeper
下载稳定版本,解压缩到/opt/workspace/zookeeper目录
[root@master1 ~]# cd /opt/workspace
[root@master1 zookeeper]#tar -zxvf zookeeper-3.4..tar.gz
(2)环境配置
修改文件 /etc/profile
export ZK_HOME=/opt/workspace/zookeeper/zookeeper-3.4.
export PATH=.:${JAVA_HOME}/bin:${SCALA_HOME}/bin:${MAVEN_HOME}/bin:$HADOOP_HOME/sbin:$HADOOP_HOME/bin:${HIVE_HOME}/bin:${SPARK_HOME}/bin:${HBASE_HOME}/bin:$SQOOP_HOME/bin:${ZK_HOME}/bin:$PATH
source /etc/profile
(3)修改配置文件
1.在集群的服务器上都创建这些目录
切换到/opt/workspace/zookeeper/目录,执行以下命令
mkdir zookeeper/data
mkdir zookeeper/datalog
并在/opt/workspace/zookeeper/data目录下创建myid文件
touch myid
将master1、master2、slave1、slave2、slave3的myid文件内容改为1,2,3,4,5
(4)修改zoo.cfg文件
复制zoo_sample.cfg文件并重命名为zoo.cfg,并添加如下配置:
[root@master1 conf]mv zoo_sample.cfg zoo.cnf
dataDir=/opt/workspace/zookeeper/data
dataLogDir=/opt/workspace/zookeeper/datalog server.=master1:: server.=master2::
server.=slave1::
server.=slave2::
server.=slave3::
说明:client port,顾名思义,就是客户端连接zookeeper服务的端口。这是一个TCP port。dataLogDir里是放到的顺序日志(WAL)。而dataDir里放的是内存数据结构的snapshot,便于快速恢复。为了达到性能最大化,一般建议把dataDir和dataLogDir分到不同的磁盘上,这样就可以充分利用磁盘顺序写的特性。dataDir和dataLogDir需要自己创建,目录可以自己制定,对应即可。
1.tickTime:CS通信心跳数
Zookeeper 服务器之间或客户端与服务器之间维持心跳的时间间隔,也就是每个 tickTime 时间就会发送一个心跳。tickTime以毫秒为单位。
tickTime=2000
2.initLimit:LF初始通信时限
集群中的follower服务器(F)与leader服务器(L)之间初始连接时能容忍的最多心跳数(tickTime的数量)。
initLimit=10
3.syncLimit:LF同步通信时限
集群中的follower服务器与leader服务器之间请求和应答之间能容忍的最多心跳数(tickTime的数量)。
syncLimit=5
依旧将zookeeper传输到其他的机器上
(5)启动zookeeper
切换到/opt/workspace/zookeeper/zookeeper-3.4.12/bin目录下,执行
zkServer.sh start
注:成功配置zookeeper之后,需要在每台机器上启动zookeeper
在所有节点启动后,等待一段时间查看即可
[root@master1 bin]# zkServer.sh status
ZooKeeper JMX enabled by default
Using config: /opt/workspace/zookeeper/zookeeper-3.4./bin/../conf/zoo.cfg
Mode: follower
[root@slave3 bin]# zkServer.sh status
ZooKeeper JMX enabled by default
Using config: /opt/workspace/zookeeper/zookeeper-3.4./bin/../conf/zoo.cfg
Mode: leader
问题:
1、zookeeper启动正常,查看状态出现错误

解决方法:
查看zookeeper.out文件
我的在zookeeper/zookeeper-3.4.12/bin/zookeeper.out
关闭防火墙
systemctl stop firewalld.service
等待一会重新启动服务,问题解决,5台机器全部启动

2、DFSZKFailoverController进程启动失败
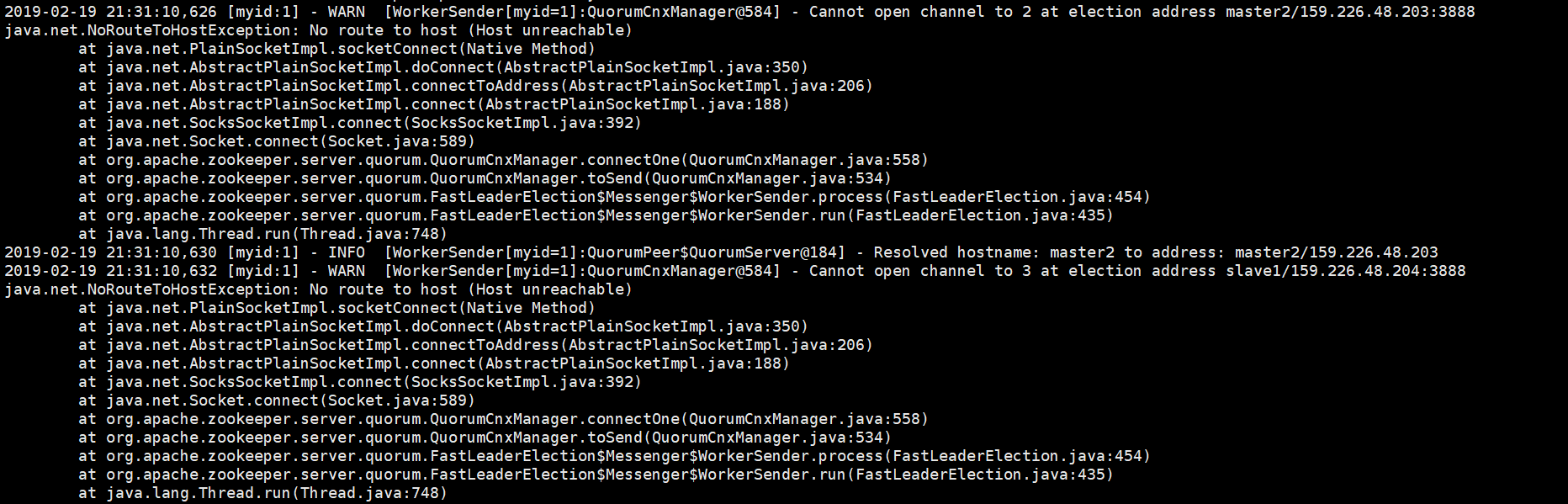
在搭建完成后,启动hadoop服务时,发现两个namenode都处于standby状态,仔细检查发现DFSZKFailoverController进程没有启动
首先去查找log日志
查看master1中的zkfc日志

发现错误

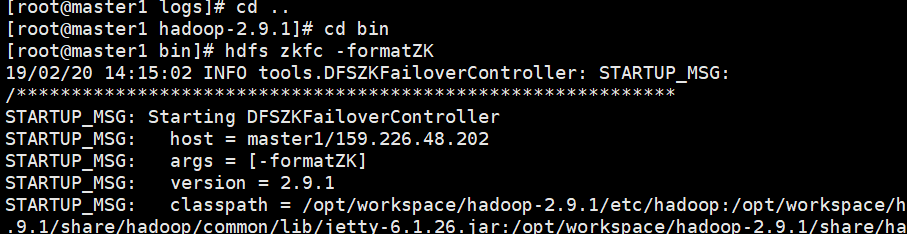
解决:重新在master1和master2上格式化zookeeper
[root@master1 hadoop-2.9.]# cd bin
[root@master1 bin]# hdfs zkfc -formatZK
在master1和master2上重新启动zookeeper
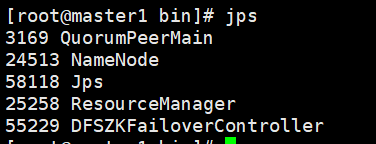
[root@master1 bin]# hadoop-daemon.sh start zkfc
查看启动的进程
[root@master1 bin]# hdfs haadmin -failover nn1 nn2
// :: WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
Failover to NameNode at master2/159.226.48.203: successful
[root@master1 bin]# hdfs haadmin -getServiceState nn1
// :: WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
standby
[root@master1 bin]# hdfs haadmin -getServiceState nn2
// :: WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
active
DFSZKFailoverController进程启动正常
参考:https://blog.csdn.net/sinat_25943197/article/details/81906060
大数据-zookeeper集群安装的更多相关文章
- 大数据Hadoop-Spark集群部署知识总结(一)
大数据Hadoop-Spark集群部署知识总结 一.启动/关闭 hadoop myhadoop.sh start/stop 分步启动: 第一步:在hadoop102主机上 sbin/start-dfs ...
- 原创:centos7.1下 ZooKeeper 集群安装配置+Python实战范例
centos7.1下 ZooKeeper 集群安装配置+Python实战范例 下载:http://apache.fayea.com/zookeeper/zookeeper-3.4.9/zookeepe ...
- 1、zookeeper集群安装
前提准备3台centos7.0虚拟机 c7003:192.168.70.103 c7004:192.168.70.104 c7005:192.168.70.105 并在三台虚拟机上配置hosts为 1 ...
- hbase和ZooKeeper集群安装配置
一:ZooKeeper集群安装配置 1:解压zookeeper-3.3.2.tar.gz并重命名为zookeeper. 2:进入~/zookeeper/conf目录: 拷贝zoo_sample.cfg ...
- Zookeeper集群安装Version3.5.1
Zookeeper集群安装,基于版本3.5.1, 使用zookeeper-3.5.1-alpha.tar.gz安装包. 1.安装规划 zookeeper集群模式,安装到如下三台机器 10.43.159 ...
- [转]大数据hadoop集群硬件选择
问题导读 1.哪些情况会遇到io受限制? 2.哪些情况会遇到cpu受限制? 3.如何选择机器配置类型? 4.为数据节点/任务追踪器提供的推荐哪些规格? 随着Apache Hadoop的起步,云客户 ...
- zookeeper 集群安装与配置
Zookeeper安装和配置 准备工作 安装 JDK,此步略. 下载 zookeeper wget http://archive.apache.org/dist/zookeeper/zookeeper ...
- 大数据 -- Hadoop集群环境搭建
首先我们来认识一下HDFS, HDFS(Hadoop Distributed File System )Hadoop分布式文件系统.它其实是将一个大文件分成若干块保存在不同服务器的多个节点中.通过联网 ...
- windows下zookeeper集群安装
windows下zookeeper单机版安装,见:https://www.cnblogs.com/lbky/p/9867899.html 一:zookeeper节点为什么是奇数个? 单机模式的zk进程 ...
随机推荐
- TF录像存储专项测试
测试环境 移动设备:小米4C 移动设备版本:Android 5.1 IPC版本号:0.1.4110_10.1.1.1.3948 安居小宝版本:Version:2.0.1 测试网络:IPC使用WIFI网 ...
- eclipse在线安装mybatis generator插件
转自:http://blog.csdn.net/u012283609/article/details/67640433 安装步骤: 打开eclipse菜单栏help–>Eclipse Marke ...
- scrapy框架 小知识
持久化 去重规则 深度 cookie start_url 深度和优先级 下载中间件 持久化 步骤 pipeline/items a. 先写pipeline类 class XXXPipeline(obj ...
- javascript总结45: HTML DOM media 属性
定义和用法 media 属性设置或返回显示文档的设备. 对于样式信息而言,目标媒介非常重要.移动设备和桌面计算机的样式可能是不同的. 实例 <html> <head> < ...
- Word2013写CSDN博客
目前大部分的博客作者在用Word写博客这件事情上都会遇到以下3个痛点: 1.所有博客平台关闭了文档发布接口,用户无法使用Word,Windows Live Writer等工具来发布博客.使用Word写 ...
- ACM 媛在努力 华山论剑
媛在努力 描述在多媒体数据处理中,数据压缩算法尤为重要.小媛上完课后就想自己发明一个数据压缩算法.她想呀想,终于想到一个方法.在多媒体数据中有很多数据都是重复的,所以她想把连续相同的数据用数据出现的次 ...
- Karma和Jasmine 自动化单元测试环境搭建
最近初学AngularJS ,看到的一些教程中经常有人推荐使用Karma+Jasmine来进行单元测试.自己之前也对Jasmine有些了解,jasmine也是一个不错的测试框架. 1. karma介绍 ...
- CentOS 7.2安装zabbix 3.0 LTS
1.zabbix简介 zabbix(音同 zæbix)是一个基于WEB界面的提供分布式系统监视以及网络监视功能的企业级的开源解决方案. zabbix能监视各种网络参数,保证服务器系统的安全运营:并提供 ...
- php的数组汉字符串常用函数
<?php// function add($a,$b,$func){// if(!is_callable($func)){// return false;// }// $m=$a+$b+$fun ...
- C#应用程序所有已经打开的窗体的集合
获取所有打开的窗体的集合 Application.OpenForms 获取其中的某个窗体 Application.OpenForms["窗体名"]