Kafka实战-Flume到Kafka (转)
原文链接:Kafka实战-Flume到Kafka
1.概述
前面给大家介绍了整个Kafka项目的开发流程,今天给大家分享Kafka如何获取数据源,即Kafka生产数据。下面是今天要分享的目录:
- 数据来源
- Flume到Kafka
- 数据源加载
- 预览
下面开始今天的分享内容。
2.数据来源
Kafka生产的数据,是由Flume的Sink提供的,这里我们需要用到Flume集群,通过Flume集群将Agent的日志收集分发到 Kafka(供实时计算处理)和HDFS(离线计算处理)。关于Flume集群的Agent部署,这里就不多做赘述了,不清楚的同学可以参考《高可用Hadoop平台-Flume NG实战图解篇》一文中的介绍,下面给大家介绍数据来源的流程图,如下图所示:

这里,我们使用Flume作为日志收集系统,将收集到的数据输送到Kafka中间件,以供Storm去实时消费计算,整个流程从各个Web节点 上,通过Flume的Agent代理收集日志,然后汇总到Flume集群,在由Flume的Sink将日志输送到Kafka集群,完成数据的生产流程。
3.Flume到Kafka
从图,我们已经清楚了数据生产的流程,下面我们来看看如何实现Flume到Kafka的输送过程,下面我用一个简要的图来说明,如下图所示:

这个表达了从Flume到Kafka的输送工程,下面我们来看看如何实现这部分。
首先,在我们完成这部分流程时,需要我们将Flume集群和Kafka集群都部署完成,在完成部署相关集群后,我们来配置Flume的Sink数据流向,配置信息如下所示:
- 首先是配置spooldir方式,内容如下所示:
producer.sources.s.type = spooldir
producer.sources.s.spoolDir = /home/hadoop/dir/logdfs
- 当然,Flume的数据发送方类型也是多种类型的,有:Console、Text、HDFS、RPC等,这里我们系统所使用的是Kafka中间件来接收,配置内容如下所示:

producer.sinks.r.type = org.apache.flume.plugins.KafkaSink
producer.sinks.r.metadata.broker.list=dn1:9092,dn2:9092,dn3:9092
producer.sinks.r.partition.key=0
producer.sinks.r.partitioner.class=org.apache.flume.plugins.SinglePartition
producer.sinks.r.serializer.class=kafka.serializer.StringEncoder
producer.sinks.r.request.required.acks=0
producer.sinks.r.max.message.size=1000000
producer.sinks.r.producer.type=sync
producer.sinks.r.custom.encoding=UTF-8
producer.sinks.r.custom.topic.name=test
这样,我们就在Flume的Sink端配置好了数据流向接受方。
4.数据加载
在完成配置后,接下来我们开始加载数据,首先我们在Flume的spooldir端生产日志,以供Flume去收集这些日志。然后,我们通过Kafka的KafkaOffsetMonitor监控工具,去监控数据生产的情况,下面我们开始加载。
- 启动ZK集群,内容如下所示:
zkServer.sh start
注意:分别在ZK的节点上启动。
- 启动Kafka集群
kafka-server-start.sh config/server.properties &
在其他的Kafka节点输入同样的命令,完成启动。
- 启动Kafka监控工具
java -cp KafkaOffsetMonitor-assembly-0.2.0.jar \
com.quantifind.kafka.offsetapp.OffsetGetterWeb \
--zk dn1:2181,dn2:2181,dn3:2181 \
--port 8089 \
--refresh 10.seconds \
--retain 1.days
- 启动Flume集群
flume-ng agent -n producer -c conf -f flume-kafka-sink.properties -Dflume.root.logger=ERROR,console
然后,我在/home/hadoop/dir/logdfs目录下上传log日志,这里我只抽取了一少部分日志进行上传,如下图所示,表示日志上传成功。

5.预览
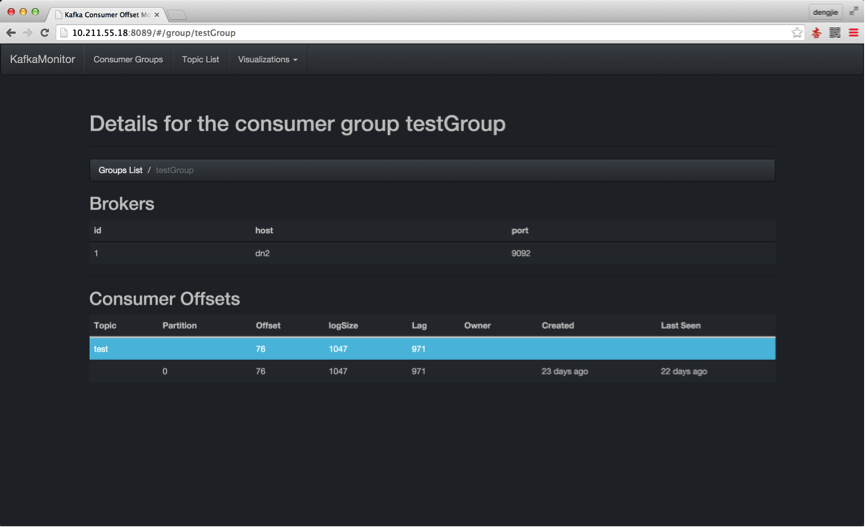
下面,我们通过Kafka的监控工具,来预览我们上传的日志记录,有没有在Kafka中产生消息数据,如下所示:
- 启动Kafka集群,为生产消息截图预览

- 通过Flume上传日志,在Kafka中产生消息数据
6.总结
本篇文章给大家讲述了Kafka的消息产生流程,后续会在Kafka实战系列中为大家讲述Kafka的消息消费流程等一整套流程,这里只是为后续的Kafka实战编码打下一个基础,让大家先对Kafka的消息生产有个整体的认识。
Kafka实战-Flume到Kafka (转)的更多相关文章
- 【Kafka】Flume整合Kafka
目录 需求 一.Flume下载地址 二.上传解压Flume 三.配置flume.conf 四.启动flume 五.测试整合 需求 实现flume监控某个目录下面的所有文件,然后将文件收集发送到kafk ...
- Kafka实战宝典:Kafka的控制器controller详解
一.控制器简介 控制器组件(Controller),是 Apache Kafka 的核心组件.它的主要作用是在 Apache ZooKeeper 的帮助下管理和协调整个 Kafka 集群.集群中任意一 ...
- Flume 与Kafka区别
今天开会讨论日志处理为什么要同时使用Flume和Kafka,是否可以只用Kafka 不使用Flume?当时想到的就只用Flume的接口多,不管是输入接口(socket 和 文件)以及输出接口(Kafk ...
- Kafka实战-Flume到Kafka
1.概述 前面给大家介绍了整个Kafka项目的开发流程,今天给大家分享Kafka如何获取数据源,即Kafka生产数据.下面是今天要分享的目录: 数据来源 Flume到Kafka 数据源加载 预览 下面 ...
- 【转】Kafka实战-Flume到Kafka
Kafka实战-Flume到Kafka Kafka 2015-07-03 08:46:24 发布 您的评价: 0.0 收藏 2收藏 1.概述 前面给大家介绍了整个Kafka ...
- Kafka实战分析(一)- 设计、部署规划及其调优
1. Kafka概要设计 kafka在设计之初就需要考虑以下4个方面的问题: 吞吐量/延时 消息持久化 负载均衡和故障转移 伸缩性 1.1 吞吐量/延时 对于任何一个消息引擎而言,吞吐量都是至关重要的 ...
- 《Apache Kafka 实战》读书笔记-认识Apache Kafka
<Apache Kafka 实战>读书笔记-认识Apache Kafka 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. 一.kafka概要设计 kafka在设计初衷就是 ...
- Kafka实战-数据持久化
1.概述 经过前面Kafka实战系列的学习,我们通过学习<Kafka实战-入门>了解Kafka的应用场景和基本原理,<Kafka实战-Kafka Cluster>一文给大家分享 ...
- Kafka实战-Kafka到Storm
1.概述 在<Kafka实战-Flume到Kafka>一文中给大家分享了Kafka的数据源生产,今天为大家介绍如何去实时消费Kafka中的数据.这里使用实时计算的模型——Storm.下面是 ...
随机推荐
- Linux下文件特殊权限
SUIDSUID表示在所有者的位置上出现了s在一个命令的所有者的权限上如果出现了s,当其他人在执行该命令的时候将具有所有者的权限.SUID权限仅对二进制文件有效 SGID表示在组的位置上出现了s如果一 ...
- Tarojs+redux支付宝小程序开发攻略
技术选型 对于习惯react语法的开发者来讲,RN是实现native的必备工具. 我们甚至可以屏蔽官方稳定而强大的配置层,直接上手开发. 而后,同为表层React语法的Rax.Taro这样的开源多端开 ...
- Loadrunner中cookie解释与用法
loadrunner对于cookie的处理loadrunner中与cookie处理相关的常用函数如下: web_add_cookie():添加新的cookie或者修改已经存在的cookie web_r ...
- BZOJ1102 [POI2007]GRZ山峰和山谷 [BFS]
题目传送门 GRZ山峰和山谷 Description FGD小朋友特别喜欢爬山,在爬山的时候他就在研究山峰和山谷.为了能够让他对他的旅程有一个安排,他想知道山峰和山谷的数量.给定一个地图,为FGD想要 ...
- golang中接口interface和struct结构类的分析
再golang中,我们要充分理解interface和struct这两种数据类型.为此,我们需要优先理解type的作用. type是golang语言中定义数据类型的唯一关键字.对于type中的匿名成员和 ...
- Java_关键字、匿名对象、内部类、访问修饰符、代码块
final关键字 概述: 继承的出现提高了代码的复用性,并方便开发.但随之也有问题,有些类在描述完之后,不想被继承,或者有些类中的部分方法功能是固定的,不想让子类重写.可是当子类继承了这些特殊类之后, ...
- braft初探
接上一篇<brpc初探>. 什么是RAFT 看内部一个开源项目的时候,一开始我以为他们自己实现了raft协议.但是看了代码之后,发现用的是braft.因为在我们自己bg里一直在提paxos ...
- [BZOJ5334][TJOI2018]数学计算(exgcd/线段树)
模意义下除法若结果仍为整数的话,可以记录模数的所有质因子,计算这些质因子的次幂数,剩余的exgcd解决. $O(n\log n)$但有9的常数(1e9内的数最多有9个不同的质因子),T了. #incl ...
- BZOJ 3676: [Apio2014]回文串 后缀自动机 Manacher 倍增
http://www.lydsy.com/JudgeOnline/problem.php?id=3676 过程很艰难了,第一次提交Manacher忘了更新p数组,超时,第二次是倍增的第0维直接在自动机 ...
- [CODE FESTIVAL 2016]Problem on Tree
题意:给一棵树,对于一个满足以下要求的序列$v_{1\cdots m}$,求最大的$m$ 对$\forall1\leq i\lt m$,路径$(v_i,v_{i+1})$不包含$v$中除了$v_i,v ...