spark[源码]-TaskSchedulerlmpl类源码
TaskSchedulerImpl概述
TaskSchedulerlmpl是创建三大核心TaskSheduler的实现类,TaskScheduler是一个特征类,DAGScheduler在提交TaskSet给底层调度器的时候是面向接口TaskScheduler,这符合面向对象中依赖抽象而不依赖具体的原则,带来底层资源调度器的可插拔性,导致Spark可以运行众多的资源调度器模式上,例如Standalone,Yarn,Mesos,Local,EC2,其他自定义的资源调度器。
TaskScheduler获取集群的资源。TaskScheduler从高层调度器DAGScheduler获得每个Task一系列任务的集合。负责把任务task发送给集群。如果失败重新尝试。返回具体的events事件给DAGScheduler汇报。
我们以Standalone模式为例,聚焦于TaskSchedulerImpl。
初始构造
构造流程如下:
1.通过读取sparkConf的配置信息,来初始化一些配置。
spark.task.maxFailures:默认最大task失败尝试是4次。
spark.speculation.interval :task任务检查频率 100ms。
speculationScheduler :推测调度。
spark.starvation.timeout: 饥饿超时时间,大于15s发出警告。
spark.task.cpus: 每个task请求的cpu数量,默认是1。

taskSets和stage的关系,task和TaskSetManger的关系,task和Executor的关系。
hasReceivedTask :已经接受的task false。
hasLaunchedTask :已经启动的task false。
nextTaskId :下一个taskid。
executorIdToTaskCount :每个执行者上总共的task数量。
protected val executorsByHost = new HashMap[String, HashSet[String]]。
protected val hostsByRack = new HashMap[String, HashSet[String]]。
protected val executorIdToHost = new HashMap[String, String]。
var dagScheduler: DAGScheduler = null :dag调度这初始化。
var backend: SchedulerBackend = null backend :初始化。
val mapOutputTracker = SparkEnv.get.mapOutputTracker : map输出追综者。
var schedulableBuilder: SchedulableBuilder = null :调度树建造者初始化。
var rootPool: Pool = null :根节点。
schedulingModeConf:调度方式 ,默认是 fifo。调度模式有FAIR和FIFO两种模式,任务的最终调度实际都是落实到接口SchedulerBackend的具体实现上的。
2.创建TaskResultGetter()
运行一个线程池,该线程池对任务结果进行反序列化和远程提取(如果需要)。
根据SchedulerBackend适配器初始创建

根据代码可以看出,TaskScheduler的创建需要依赖SchedulerBackend(Standalone)这个资源适配器的。
scheduler.initialize(backend)传入的参数backend。
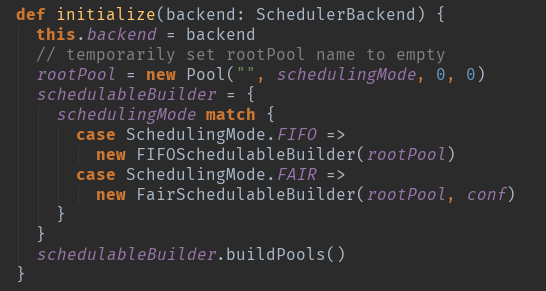
这个地方有两个重要的变量进行创建了,
一个是调度池配置创建roolPool:这个地方主要是初始化资源调度的模式,初始化调度算法。
一个是调度树的创建schedulableBuilder:这个地方主要是创建调度树,对taskSetManger进行调度管理。
TaskSchedulerImpl.submitTasks:主要的作用是将TaskSet加入到TaskSetManager
SchdulableBuilder.addTaskSetmanager:SchdulableBuilder会确定TaskSetManager的调度顺序,然后按照TaskSetManager来确定每个Task具体运行在哪个ExecutorBackend中。
rootpool创建
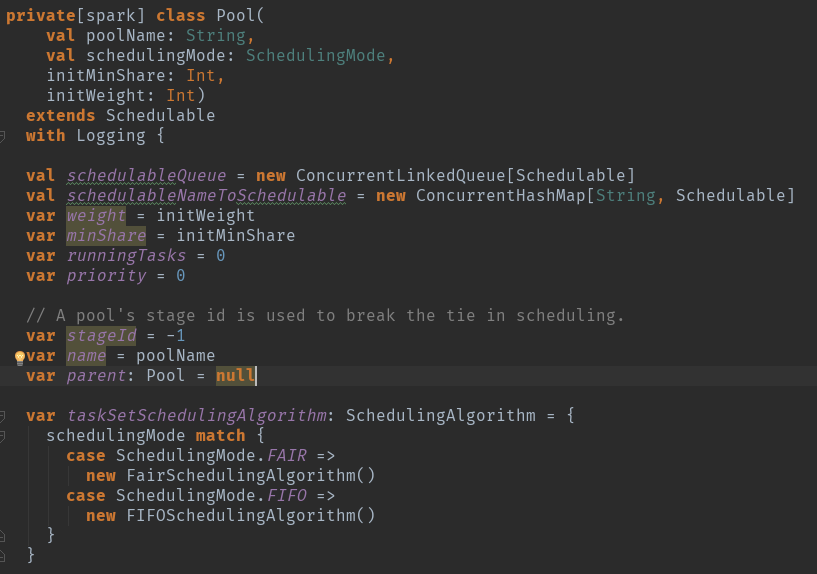
val schedulableQueue = new ConcurrentLinkedQueue[Schedulable] 调度队列
val schedulableNameToSchedulable = new ConcurrentHashMap[String, Schedulable] 调度对应关系
var weight = initWeight 调度池权重
var minShare = initMinShare 计算资源中的cpu核数
var runningTasks = 0 正在运行的task数量
var priority = 0 优先级
var stageId = -1 池的阶段id用于在调度中中断绑定
var name = poolName 调度池名字
var parent: Pool = null
调度算法,根据调度模式初始化算法。org.apache.spark.scheduler.SchedulingAlgorithm。
调度池则用于调度每个sparkContext运行时并存的多个互相独立无依赖关系的任务集。
调度池负责管理下一级的调度池和TaskSetManager对象。
用户可以通过配置文件定义调度池和TaskSetManager对象。
1.调度的模式Scheduling mode:用户可以设置FIFO或者FAIR调度方式。
2.weight,调度的权重,在获取集群资源上权重高的可以获取多个资源。
3.miniShare:代表计算资源中的cpu核数。
配置conf/faurscheduler.xml配置调度池的属性,同时要在sparkConf对象中配置属性。
SchedulableBuilder创建
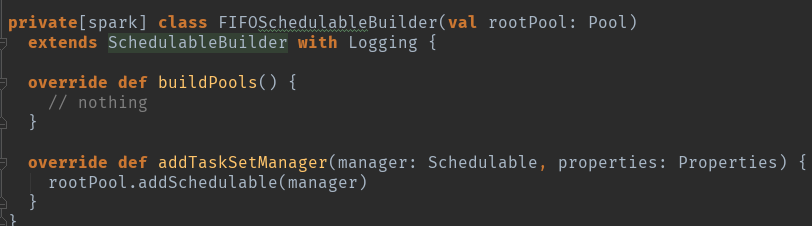
可以看到在FIFO的模式下buildPool基本上没干啥,主要是addTaskSetManager是连接TaskSetManager和资源调度池的桥梁。
spark[源码]-TaskSchedulerlmpl类源码的更多相关文章
- Spark之SQL解析(源码阅读十)
如何能更好的运用与监控sparkSQL?或许我们改更深层次的了解它深层次的原理是什么.之前总结的已经写了传统数据库与Spark的sql解析之间的差别.那么我们下来直切主题~ 如今的Spark已经支持多 ...
- 《深入理解Spark:核心思想与源码分析》——SparkContext的初始化(叔篇)——TaskScheduler的启动
<深入理解Spark:核心思想与源码分析>一书前言的内容请看链接<深入理解SPARK:核心思想与源码分析>一书正式出版上市 <深入理解Spark:核心思想与源码分析> ...
- 《深入理解Spark:核心思想与源码分析》(前言及第1章)
自己牺牲了7个月的周末和下班空闲时间,通过研究Spark源码和原理,总结整理的<深入理解Spark:核心思想与源码分析>一书现在已经正式出版上市,目前亚马逊.京东.当当.天猫等网站均有销售 ...
- 《深入理解Spark:核心思想与源码分析》(第2章)
<深入理解Spark:核心思想与源码分析>一书前言的内容请看链接<深入理解SPARK:核心思想与源码分析>一书正式出版上市 <深入理解Spark:核心思想与源码分析> ...
- 《深入理解Spark:核心思想与源码分析》一书正式出版上市
自己牺牲了7个月的周末和下班空闲时间,通过研究Spark源码和原理,总结整理的<深入理解Spark:核心思想与源码分析>一书现在已经正式出版上市,目前亚马逊.京东.当当.天猫等网站均有销售 ...
- 《深入理解Spark:核心思想与源码分析》正式出版上市
自己牺牲了7个月的周末和下班空闲时间,通过研究Spark源码和原理,总结整理的<深入理解Spark:核心思想与源码分析>一书现在已经正式出版上市,目前亚马逊.京东.当当.天猫等网站均有销售 ...
- Spark Streaming揭秘 Day26 JobGenerator源码图解
Spark Streaming揭秘 Day26 JobGenerator源码图解 今天主要解析一下JobGenerator,它相当于一个转换器,和机器学习的pipeline比较类似,因为最终运行在Sp ...
- Spark Streaming运行流程及源码解析(一)
本系列主要描述Spark Streaming的运行流程,然后对每个流程的源码分别进行解析 之前总听同事说Spark源码有多么棒,咱也不知道,就是疯狂点头.今天也来撸一下Spark源码. 对Spark的 ...
- Java集合---Array类源码解析
Java集合---Array类源码解析 ---转自:牛奶.不加糖 一.Arrays.sort()数组排序 Java Arrays中提供了对所有类型的排序.其中主要分为Prim ...
随机推荐
- 剑指 offer set 14 打印 1 到 N 中 1 的个数
总结 1. 假设 n == 2212, 算法分为两个步骤. 第一步, 将这个 2212 个数分为 1~ 212, 213 ~ 2212 2. 第一部分实际上是将 n 的规模缩小到 212. 假如知道如 ...
- 简单是Jedis实例(相对连接池而言)
在引入相关jar包后,只要new一个Jedis对象,就能做redis相关操作了.以下是一个简单的jedis实例: package com.pptv.redis; import java.util.Ar ...
- 【BZOJ2565】最长双回文串 Manacher
[BZOJ2565]最长双回文串 Description 顺序和逆序读起来完全一样的串叫做回文串.比如acbca是回文串,而abc不是(abc的顺序为“abc”,逆序为“cba”,不相同).输入长度为 ...
- 160506、Spring mvc新手入门(11)-返回json 字符串的其他方式
Spring MVC返回 json字符串的方式有很多种方法,这里介绍最简单,也是最常使用的两种方式 一.使用 PrintWriter printWriter 直接输出字符串到返回结果中 不需 ...
- 在nginx启动后,如果我们要操作nginx,要怎么做呢 别增加无谓的上下文切换 异步非阻塞的方式来处理请求 worker的个数为cpu的核数 红黑树
nginx平台初探(100%) — Nginx开发从入门到精通 http://ten 众所周知,nginx性能高,而nginx的高性能与其架构是分不开的.那么nginx究竟是怎么样的呢?这一节我们先来 ...
- 预见未来丨机器学习:未来十年研究热点 量子机器学习(Quantum ML) 量子计算机利用量子相干和量子纠缠等效应来处理信息
微软研究院AI头条 https://mp.weixin.qq.com/s/SAz5eiSOLhsdz7nlSJ1xdA 预见未来丨机器学习:未来十年研究热点 机器学习组 微软研究院AI头条 昨天 编者 ...
- closure--- 闭包与并行运算
闭包有效的减少了函数所需定义的参数数目.这对于并行运算来说有重要的意义.在并行运算的环境下,我们可以让每台电脑负责一个函数,然后将一台电脑的输出和下一台电脑的输入串联起来.最终,我们像流水线一样工 ...
- F5刷新与在地址栏按回车的区别
“F5刷新”,它是在你现有页面的基础上,检查网页是否有更新的内容.在检查时,会保留之前的一些变量的值: “转到”和在地址栏回车,则相当于你重新输入网页的URL访问,这种情况下,浏览器会尽量使用已经存在 ...
- JS之for...in和for...of
for...in输入键: for...in循环有几个缺点. 数组的键名是数字,但是for...in循环是以字符串作为键名“0”.“1”.“2”等等. for...in循环不仅遍历数字键名,还会遍历手动 ...
- MYSQL--表分区、查看分区(转)
一. mysql分区简介 数据库分区 数据库分区是一种物理数据库设计技术.虽然分区技术可以实现很多效果,但其主要目的是为了在特定的SQL操作中减少数据读写的总量以缩减sql语句的响应时间, ...