Libsvm学习
本篇博客转自 http://www.cppblog.com/guijie/archive/2013/09/05/169034.html
在电脑文件夹E:\other\matlab 2007a\work\SVM\libsvm-mat-3.0-1 ,这个是已经编译好的,到64位机上要重新编译(不要利用别人传的,因为可能改过SVM程序,例如Libing wang他改过其中程序,最原始版本:E:\other\matlab 2007a\work\SVM\libsvm-mat-3.0-1.zip,从 http://www.csie.ntu.edu.tw/~cjlin/libsvm/matlab/libsvm-mat-3.0-1.zip 下载)。svmtrain在matlab自带的工具箱中也有这个函数, libing 讲libsvm-mat-3.0-1放到C:\Program Files\MATLAB\R2010a\toolbox\目录,再adddpath和savepath即可。如果产生以下问题:每次都要 adddpath和savepath ,在matlab重新启动后要重新。
adddpath和savepath。解决方案:可以在要运行的程序前面添加如下语句即可:
addpath('C:\Program Files\MATLAB\R2010a\toolbox\libsvm-mat-3.0-1');
注意: make的时候一定要在libsvm目录里面,不然就会出现以下错误:
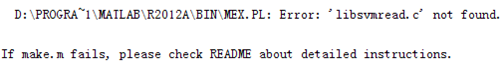
README文件写得很好,其中的Examples完全理解(包括Precomputed Kernels.Constructing a linear kernel matrix and then using the precomputed kernel gives exactly the same testing error as using the LIBSVM built-in linear kernel.核就是相似度,自己想定义什么相似度都可以)
(1) model = svmtrain(training_label_vector, training_instance_matrix [, 'libsvm_options']);
libsvm_options的设置:
Examples of options: -s 0 -c 10 -t 1 -g 1 -r 1 -d 3
Classify a binary data with polynomial kernel (u'v+1)^3 and C = 10
options:
-s svm_type : set type of SVM (default 0)
0 -- C-SVC
1 -- nu-SVC
2 -- one-class SVM
3 -- epsilon-SVR
4 -- nu-SVR
C-SVC全称是什么?
C-SVC(C-support vector classification),nu-SVC(nu-support vector classification),one-class SVM(distribution estimation),epsilon-SVR(epsilon-support vector regression),nu-SVR(nu-support vector regression)。0,1是多类分类,2是二分类。 3,4是回归。
-t kernel_type : set type of kernel function (default 2)
0 -- linear: u'*v //线性核
1 -- polynomial: (gamma*u'*v + coef0)^degree //多项式核
2 -- radial basis function: exp(-gamma*|u-v|^2)
3 -- sigmoid: tanh(gamma*u'*v + coef0)
-d degree : set degree in kernel function (default 3)
-g gamma : set gamma in kernel function (default 1/num_features)
-r coef0 : set coef0 in kernel function (default 0)
-c cost : set the parameter C of C-SVC, epsilon-SVR, and nu-SVR (default 1)
-n nu : set the parameter nu of nu-SVC, one-class SVM, and nu-SVR (default 0.5)
-p epsilon : set the epsilon in loss function of epsilon-SVR (default 0.1)
-m cachesize : set cache memory size in MB (default 100)
-e epsilon : set tolerance of termination criterion (default 0.001)
-h shrinking: whether to use the shrinking heuristics, 0 or 1 (default 1)
-b probability_estimates: whether to train a SVC or SVR model for probability estimates, 0 or 1 (default 0)
-wi weight: set the parameter C of class i to weight*C, for C-SVC (default 1)
The k in the -g option means the number of attributes in the input data.
(2)如何采用线性核?
matlab> % Linear Kernel
matlab> model_linear = svmtrain(train_label, train_data, '-t 0');
严格讲,线性核也要像高斯核一样调整c这个参数,Libing wang讲一般C=1效果比较好,可能调整效果差异不大,当然要看具体的数据集。c大,从SVM目标函数可以看出,c越大,相当于惩罚松弛变量,希望松弛变量接近0,即都趋向于对训练集全分对的情况,这样对训练集测试时准确率很高,但推广能力未必好,即在测试集上未必好。c小点,相当于边界的有些点容许分错,将他们当成噪声点,这样外推能力比较好。
(3)如何采用高斯核?
matlab> load heart_scale.mat
matlab> model = svmtrain(heart_scale_label, heart_scale_inst, '-c 1 -g 0.07');
(4)如何实现交叉验证?
README文件有如下一句话:If the '-v' option is specified, cross validation is
conducted and the returned model is just a scalar: cross-validation
accuracy for classification and mean-squared error for regression.
(5) 如何调整高斯核的两个参数?
思路1:在训练集上调整两个参数使在训练集上测试错误率最低,就选这样的参数来测试测试集
思路1的问题:Libing Wang讲这样很容易过学习,因为在训练集上很容易达到100%准确率,但在测试集上未必好,即过学习。用思路2有交叉验证,推广性能比较好(交叉验证将训练集随机打乱,推广性能很好)
思路2:% E:\other\matlab 2007a\work\DCT\DCT_original\network.m
思路2的问题:针对不同的数据集,这两个参数分别在什么范围内调整,有没有什么经验?Libing Wang讲没什么规律,先粗调整,再仔细调整。这个相当于在训练集上交叉验证。还有另外一种思路:类似A Regularized Approach to Feature Selection for Face Detection (ACCV 2007)的4.2节,Libing Wang讲在训练集上交叉验证也相当于训练集挑 了一部分做验证,原理一样
(6)如何采用预定义核?
To use precomputed kernel, you must include sample serial number asthe first column of the training and testing data (assume your kernel matrix is K, # of instances is n):
matlab> K1 = [(1:n)', K]; % include sample serial number as first column
matlab> model = svmtrain(label_vector, K1, '-t 4');
matlab> [predict_label, accuracy, dec_values] = svmpredict(label_vector, K1, model); % test the training data
We give the following detailed example by splitting heart_scale into 150 training and 120 testing data. Constructing a linear kernel matrix and then using the precomputed kernel gives exactly the same testing error as using the LIBSVM built-in linear kernel.
matlab> load heart_scale.mat
matlab>
matlab> % Split Data
matlab> train_data = heart_scale_inst(1:150,:);
matlab> train_label = heart_scale_label(1:150,:);
matlab> test_data = heart_scale_inst(151:270,:);
matlab> test_label = heart_scale_label(151:270,:);
matlab>
matlab> % Linear Kernel
matlab> model_linear = svmtrain(train_label, train_data, '-t 0');
matlab> [predict_label_L, accuracy_L, dec_values_L] = svmpredict(test_label, test_data, model_linear);
matlab>
matlab> % Precomputed Kernel
matlab> model_precomputed = svmtrain(train_label, [(1:150)', train_data*train_data'], '-t 4');
matlab> [predict_label_P, accuracy_P, dec_values_P] = svmpredict(test_label, [(1:120)', test_data*train_data'], model_precomputed);
matlab>
matlab> accuracy_L % Display the accuracy using linear kernel
matlab> accuracy_P % Display the accuracy using precomputed kernel
(7)如何实现概率估计?
For probability estimates, you need '-b 1' for training and testing:
matlab> load heart_scale.mat
matlab> model = svmtrain(heart_scale_label, heart_scale_inst, '-c 1 -g 0.07 -b 1');
matlab> load heart_scale.mat
matlab> [predict_label, accuracy, prob_estimates] = svmpredict(heart_scale_label, heart_scale_inst, model, '-b 1');
非概率估计
matlab> load heart_scale.mat
matlab> model = svmtrain(heart_scale_label, heart_scale_inst, '-c 1 -g 0.07');
matlab> [predict_label, accuracy, dec_values] = svmpredict(heart_scale_label, heart_scale_inst, model); % test the training data
(8) svmpredict的用法(摘自libsvm-mat-2.9-1的README)
[predicted_label, accuracy, decision_values/prob_estimates] = svmpredict(testing_label_vector, testing_instance_matrix, model [, 'libsvm_options']);
输入:testing_label_vector, If labels of test data are unknown, simply use any random values. (type must be double)。模型一旦确定,预测的标记就确定了,如果不利用第二个输出accuracy,则testing_label_vector随便设置,当然如果要利用accuracy,就要将testing_label_vector设置成测试标记了。(Action recognition\ASLAN database中的代码CLSlibsvmC,第九行用到svmpredict,testing_label_vector设置成ones(size(Samples,2),1),是无所谓的)。
svmpredict输出的含义:
predictd_label, is a vector of predicted labels(故CLSlibsvmC的12到14行没用);
摘自libsvm-mat-3.0-1的README
The function 'svmpredict' has three outputs. The first one, predictd_label, is a vector of predicted labels. The second output, accuracy, is a vector including accuracy (for classification), mean squared error, and squared correlation coefficient (for regression). The third is a matrix containing decision values or probability estimates (if '-b 1' is specified). If k is the number of classes, for decision values, each row includes results of predicting k(k-1)/2 binary-class SVMs. For probabilities, each row contains k values indicating the probability that the testing instance is in each class. Note that the order of classes here is the same as 'Label' field in the model structure.
(9)LibSVM是如何采用one-versus-rest和one-verse-one实现多类分类的?
one-versus-rest和one-verse-one的定义见模式识别笔记第四页反面(同时见孙即祥教材P47)。找libing wang和junge zhang,他们都讲没对这个深究过。根据“If k is the number of classes, for decision values, each row includes results of predicting k(k-1)/2 binary-class SVMs. For probabilities, each row contains k values indicating the probability that the testing instance is in each class. ”,我觉得应该是probabilities实现的是one-versus-rest,即采用-b 1这个选项,他俩都觉得我理解应该是正确的。junge讲参加pascal竞赛和imagenet,他们都是训练k个SVM(即one-versus-rest,没用one-versus-one,后者太慢,而且估计效果差不多),没有直接采用SVM做多类问题。
20130910 LibSVM作者回信:
Libsvm implements only 1vs1.
For 1vsrest, you can check the following
libsvm faq
Q: LIBSVM supports 1-vs-1 multi-class classification. If instead I would
like to use 1-vs-rest, how to implement it using MATLAB interface?
网址:http://www.csie.ntu.edu.tw/~cjlin/libsvm/faq.html#f808Q: LIBSVM supports 1-vs-1 multi-class classification. If instead I would like to use 1-vs-rest, how to implement it using MATLAB interface?
Please use code in the following directory. The following example shows how to train and test the problem dna (training and testing).
Load, train and predict data:
[trainY trainX] = libsvmread('./dna.scale');
[testY testX] = libsvmread('./dna.scale.t');
model = ovrtrain(trainY, trainX, '-c 8 -g 4');
[pred ac decv] = ovrpredict(testY, testX, model);
fprintf('Accuracy = %g%%\n', ac * 100);
Conduct CV on a grid of parameters
bestcv = 0;
for log2c = -1:2:3,
for log2g = -4:2:1,
cmd = ['-q -c ', num2str(2^log2c), ' -g ', num2str(2^log2g)];
cv = get_cv_ac(trainY, trainX, cmd, 3);
if (cv >= bestcv),
bestcv = cv; bestc = 2^log2c; bestg = 2^log2g;
end
fprintf('%g %g %g (best c=%g, g=%g, rate=%g)\n', log2c, log2g, cv, bestc, bestg, bestcv);
end
end
(9)如何实现验证模式下的准确率?
见我写的程序RVM\code\Yale\SVM\TestYale_SVM_2classes
--------------------------------------------------------------------------------------------------------------------------------------------------------
http://blog.sina.com.cn/s/blog_64b046c701018c8n.html
MATLAB自带的svm实现函数与libsvm差别小议
1 MATLAB自带的svm实现函数仅有的模型是C-SVC(C-support vector classification); 而libsvm工具箱有C-SVC(C-support vector classification),nu-SVC(nu-support vector classification),one-class SVM(distribution estimation),epsilon-SVR(epsilon-support vector regression),nu-SVR(nu-support vector regression)等多种模型可供使用。
2 MATLAB自带的svm实现函数仅支持分类问题,不支持回归问题;而libsvm不仅支持分类问题,亦支持回归问题。
3 MATLAB自带的svm实现函数仅支持二分类问题,多分类问题需按照多分类的相应算法编程实现;而libsvm采用1v1算法支持多分类。
4 MATLAB自带的svm实现函数采用RBF核函数时无法调节核函数的参数gamma,貌似仅能用默认的;而libsvm可以进行该参数的调节。
5 libsvm中的二次规划问题的解决算法是SMO;而MATLAB自带的svm实现函数中二次规划问题的解法有三种可以选择:经典二次方法;SMO;最小二乘。(这个是我目前发现的MATLAB自带的svm实现函数唯一的优点~)
--------------------------------------------------------------------------------------------------------------------------------------------------------
SVM 理论部分
SVM下面推导核化形式(Eric Xing教材)+M. Belkin, P. Niyogi, and V. Sindhwani, “Manifold Regularization: AGeometric Framework for Learning from Labeled and Unlabeled Examples,” J. Machine Learning Research, vol. 7, pp. 2399-2434, 2006的4.3和4.4节.+Ensemble Manifold Regularization (TPAMI 2012)
电脑里的"ZhuMLSS14.pdf"是很好的入门材料
Libsvm学习的更多相关文章
- LibSVM学习详细说明
代码文件主要针对Matlab进行说明,但个人仍觉得讲解的支持向量机内容非常棒,可以做为理解这一统计方法的辅助资料; LibSVM是台湾林智仁(Chih-Jen Lin)教授2001年开发的一套支持向量 ...
- LibSVM学习(四)——逐步深入LibSVM 转
原文:http://blog.csdn.net/flydreamgg/article/details/4470121 其实,在之前上海交大模式分析与机器智能实验室对2.6版本的svm.cpp做了部分注 ...
- 【libsvm学习】
参考: http://www.cnblogs.com/bigshuai/articles/2883256.html http://www.cnblogs.com/tornadomeet/archive ...
- LibSVM使用指南
LibSVM使用指南 一. SVM简介 在进行下面的内容时我们认为你已经具备了数据挖掘的基础知识. SVM是新近出现的强大的数据挖掘工具,它在文本分类.手写文字识别.图像分类.生物序列分析等实 ...
- LIBSVM的使用方法
[原文:http://wenku.baidu.com/view/7e7b6b896529647d27285276.html] 目 录 1 Libsvm下载... 3 2 Libsvm3.0环境变量设 ...
- libsvm参数选择
以前接触过libsvm,现在算在实际的应用中学习 LIBSVM 使用的一般步骤是: 1)按照LIBSVM软件包所要求的格式准备数据集: 2)对数据进行简单的缩放操作: 3)首要考虑选用RBF 核函数: ...
- 项目二:使用机器学习(SVM)进行基因预测
SVM软件包 LIBSVM -- A Library for Support Vector Machines(本项目所用到的SVM包)(目前最新版:libsvm-3.21,2016年7月8日) C-S ...
- 机器学习实验一SVM分类实验
一.实验目的和内容 (一)实验目的 1.熟悉支持向量机SVM(Support Vector Machine)模型分类算法的使用. 2.用svm-train中提供的代码框架(填入SVM分类器代码)用tr ...
- 文本分类学习 (十)构造机器学习Libsvm 的C# wrapper(调用c/c++动态链接库)
前言: 对于SVM的了解,看前辈写的博客加上读论文对于SVM的皮毛知识总算有点了解,比如线性分类器,和求凸二次规划中用到的高等数学知识.然而SVM最核心的地方应该在于核函数和求关于α函数的极值的方法: ...
随机推荐
- nginx作反向代理,实现负载均衡
nginx作反向代理,实现负载均衡按正常的方法安装好 ngixn,方法可参考http://www.cnblogs.com/lin3615/p/4376224.html其中作了反向代理的服务器的配置如下 ...
- C++安装失败解决办法
法一:删除注册表中的HKY_LOCAL_MACHINE\\SYSTEM|ControlSet001\\Services\\VSS,卸载重装.法二:点击 setup目录下的 wpie15.exe .. ...
- (一)在linux上ubuntu搭建hustOJ系统
同实验室有人在用java写签到系统,正好我在学习PHP,我就在想能不能在以前学长留下来一直没用OJ上添加一个签到功能. 于是说干就干,就找了许多关于hustoj的文章参考. 首先要说的是安装husto ...
- 分享:mysql 随机查询数据
在mysql中查询5条不重复的数据,使用以下: 1 SELECT * FROM `table` ORDER BY RAND() LIMIT 5 就可以了.但是真正测试一下才发现这样效率非常低.一个1 ...
- PHP中$_REQUEST中包含的数据,数据被覆盖问题
这个问题涉及到php.ini中的两个变量. variables_order = "EGPCS" variables_order 系统在定义PHP预定义变量,EGPCS 是 Envi ...
- URI、URL以及URN的区别
首先,URI,是uniform resource identifier,统一资源标识符,用来唯一的标识一个资源.而URL是uniform resource locator,统一资源定位器,它是一种具体 ...
- linux文件目录下各文件简介
/bin:存放最常用命令: /boot:启动Linux的核心文件: /dev:设备文件: /etc:存放各种配置文件: /home:用户主目录: /lib:系统最基本的动态链接共享库: /mnt:一般 ...
- H5不能少的功能-滑动分页
// 滑动分页 $(window).scroll(function() { var mayLoadContent = $(window).scrollTop() & ...
- 人工智能起步-反向回馈神经网路算法(BP算法)
人工智能分为强人工,弱人工. 弱人工智能就包括我们常用的语音识别,图像识别等,或者为了某一个固定目标实现的人工算法,如:下围棋,游戏的AI,聊天机器人,阿尔法狗等. 强人工智能目前只是一个幻想,就是自 ...
- iOS 进阶 第三天(0326)
0326 Xib:描述软件界面,轻量级,一般用来描述局部界面 Xib的获取,如下图所示: xib在我们开发的时候叫xib,但如果运行在我们手机里会生成nib.所以xib和nib两种方法来访问xib